Agent Evaluation: Metrics for Evaluating Agentic Workflows

This is Part 2 of our Agent Evaluations series. Here are Part 1 and Part 3 in this series.
As AI agents start to gain traction across industries, driving innovation in tasks ranging from customer support to automation of tasks like booking requires their real-world performance evaluation to go beyond static benchmarks. Evaluating agents helps assess their decision-making process, adaptability, and goal-directed behavior in dynamic environments. This requires moving from single-turn responses to multi-turn evaluations, which necessitate different metrics to understand effectiveness [1].
Why Traditional Metrics aren't Enough
Modern AI agents handle complex, multi-step tasks that require planning, tool use, reflection, and adaptation. We need metrics that capture this complexity.
Consider a restaurant booking agent - while it might show a 95% success rate in making reservations, this metric fails to capture whether it can adapt when complications arise. When a requested time slot is unavailable, a reliable agent should explore alternatives like nearby time slots rather than simply reporting failure. This demonstrates how traditional success metrics can mask the agent's ability to navigate real-world complexity. Thus, agent evaluation metrics need to be more dynamic in nature, capturing the challenges of complex environments.
Let’s discuss some system-specific metrics that one should consider to better understand their agent.
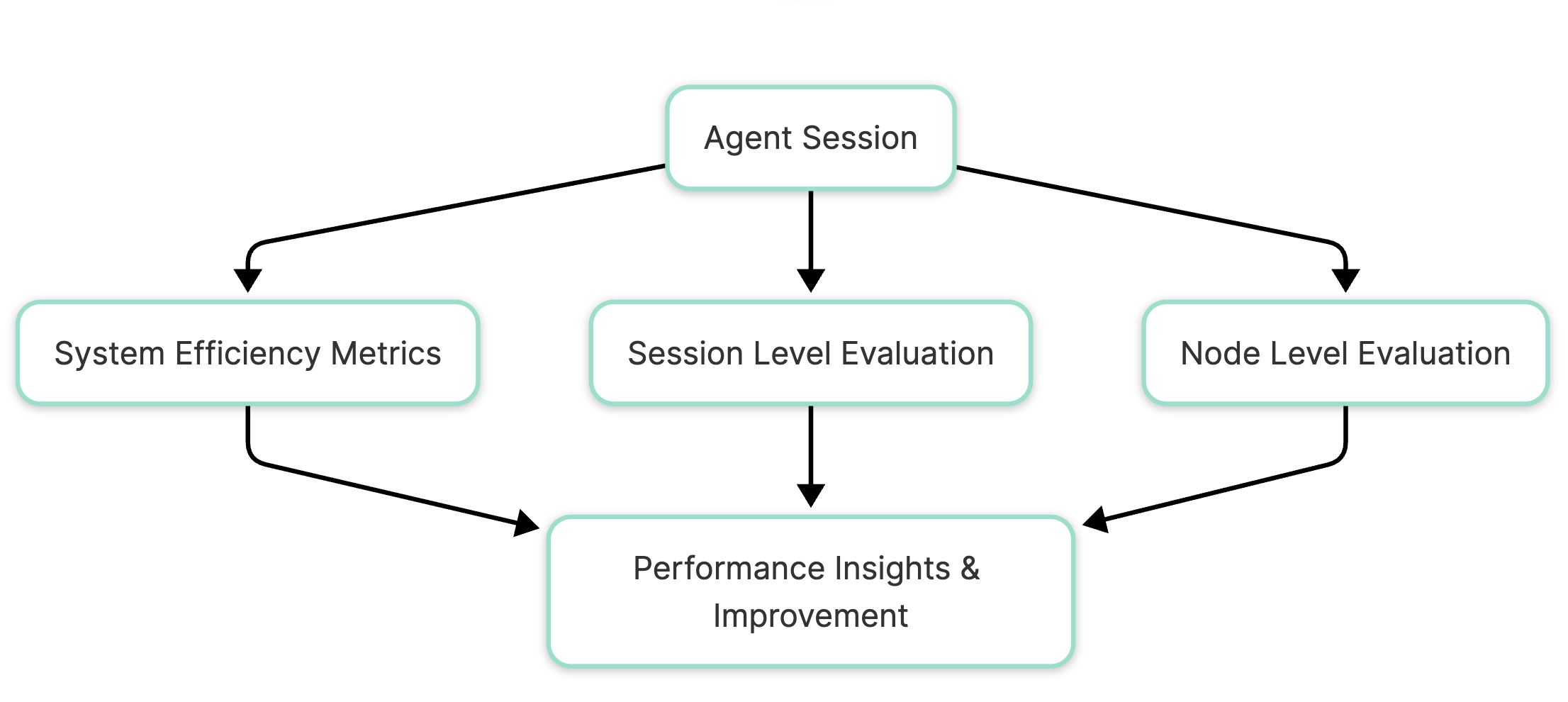
Metrics for Agent Evaluation
System Efficiency Metrics
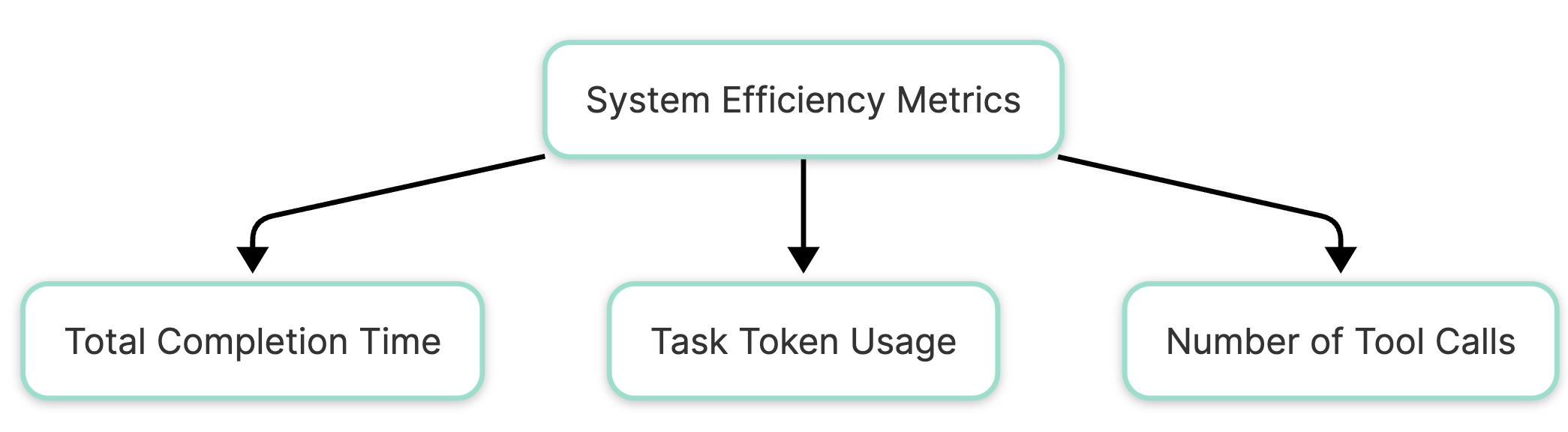
The first set of metrics helps us understand if our AI agent is operating efficiently. These metrics help assess resource utilization in terms of tokens and tool usage.
Total completion time helps to better understand how long each part of the process takes. When an agent spends three minutes on a task, we need to know if it was stuck in a loop for two of those minutes or making steady progress.
Every API call and token processed quickly accumulates in an agentic setup, impacting efficiency and cost. Effective agents minimize costs while maximizing value. Hence, metrics like Task token usage, Number of tool calls helps track the task efficiency. This will help quickly identify whether the agent is solving tasks in a cost-optimal manner. Such metrics also help to pinpoint the pitfalls and iterate on them quickly.
Agent Quality Metrics
These metrics evaluate the effectiveness of the agent in solving tasks, the methods used, and the encountered failures. These metrics can be broadly classified into overall agent evaluation and their component evaluation:
Session Level Evaluation
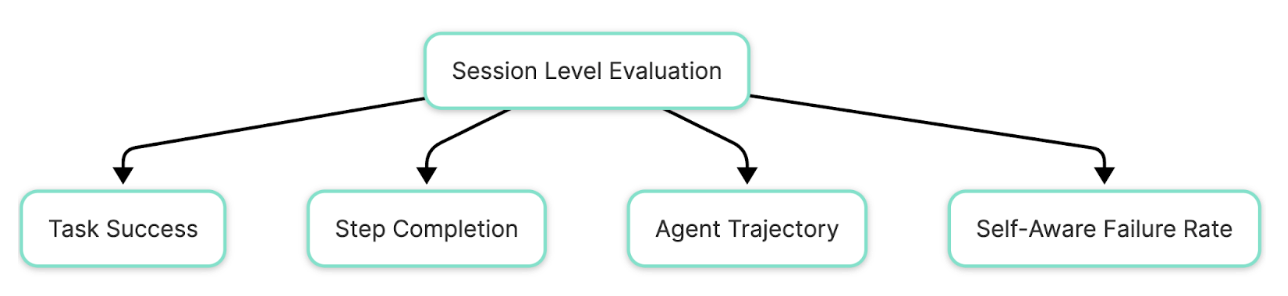
Task success: This metric [1][2] determines whether the agent successfully achieves the user’s goal based on its session output. It helps to measure if the agent, over its multiple steps, despite all its adaptations, can successfully reach the intended target to solve the task it set out to achieve.
Step completion: This is where we get granular but in an interesting way. If the user has a predefined approach to solving a task, this metric evaluates if the agent also conforms to the expected steps without deviating much to reach the goal. This evaluation metric can help assess if all the expected steps were executed correctly.
Agent trajectory: There may be multiple trajectories to reach a goal. This metric assesses whether the agent follows a reasonable and effective path to solve the user query. What we can be looking for:
- Smart choices: Does the agent pick the right tool for the job?
- Adaptability: Can it handle unexpected situations? Think of a GPS recalculating when you take a wrong turn.
This metric can also be thought of as another way of evaluating the plan being followed by an agent inspired by this research paper.
Self-aware failure rate: This metric [4] helps to measure failures where the agent is aware of its limitations in solving a task which could be ascertained with messages such as “I am unable to do this task due to <xyz> reason” or “I have hit the rate limit errors”. These failures could be due to a lack of capability of the agent or due to the agent looping on the same step again failing at it.
In addition to the above agent-specific metrics, we can extend the capabilities of existing single-turn metrics using LLM as a judge to measure the bias or toxicity in the agent outputs.
Node Level Evaluation
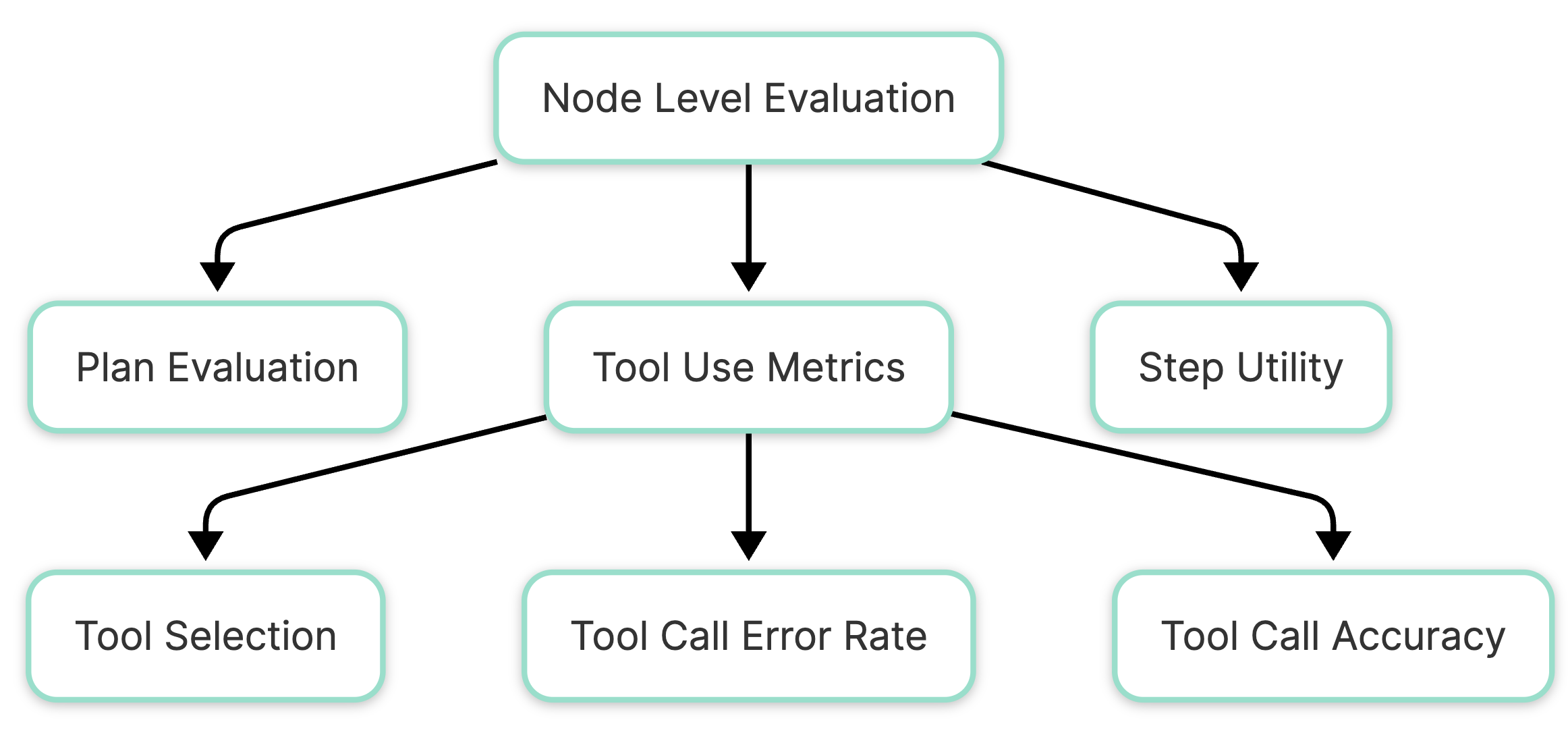
Now, let’s get into the nitty-gritty of the agentic evaluation. These metrics help to dive deeper to assess the performance of the agent's planning, tool use, and steps:
Tool use metrics: While dealing with agents, tool use is an essential part of helping improve the performance of agents. However, it is essential to evaluate the tool used to ensure that the agent calls the right tools and gets the right outputs from the tools to better understand their functioning. Hence, the following metrics are of importance:
- Tool selection: It is imperative to check if the agent is calling the correct tool to solve the task in that step, along with passing the adequate input parameters for the tool call to be implemented. This metric helps to ensure that there was no part of the agent in the tool call failure.
- Tool call error rate: To ensure that future steps taken by the agent are not affected, one can check if the tool being called by the agent is giving an output. This evaluation helps recognize some steps, in the tool call pipeline being the problem to rectify.
- Tool call accuracy: Finally, the quality of the tool call needs to be verified, for which the output obtained by the agent’s tool call, given the input query is evaluated. Given it is not possible to know the accurate output from the lens of evaluation, we can compare the output with an expected output to score the accuracy.
Plan evaluation: Planning what steps to take is hard and can result in failures [1]. Hence, it's important to evaluate an agent for planning failures. The key questions we aim to address are- will the plan help solve the task given constraints, or if there are errors in reflection due to which the planning is failing, or if there are tool failures that can happen in the plan generated. One can use LLM models to verify plans, as highlighted in this research paper.
Step utility: This metric helps to evaluate the number of contributing steps. The question to answer via the metric is whether the step is helpful, harmful, or neutral in the context of the overall objective? Did it move the task forward, did it create obstacles that hindered progress, or was it inconsequential?
Examples of Real-World Agents
To better understand what we discussed above, let’s look at a few examples of real-world agent evaluations:
Travel Agent
If we gave the following scenario: "Book a round trip from London to San Francisco on the cheapest dates in March for CEO of a company"
As we can see above, we can use Maxim AI’s simulation agent to query a target travel agent to book a flight for a customer. To evaluate this agent, let's use a few metrics that we discussed till now:

This metric helps us understand that the agent did the right steps to reach its target of booking the flight seeing only the trajectory of the agent.

This metric helps us understand that the agent did the expected steps defined by the user while booking the flight.

This metric helps us understand that the agent was successful in completing the task, fulfilling all the user requirements in booking it.
Customer Service Agent
If we gave the following scenario: "Output the current address of the person with email id akubekv@ftc.gov and then change their address to BHIVE, Indiranagar in the database"


For a successful customer service agent as well, we can refer to the above metrics via Maxim to holistically evaluate our agent and ensure it's working in an optimal manner.
Conclusion
Agentic evaluation shifts AI assessment from static benchmarks to dynamic, multi-turn interactions, ensuring a more accurate measure of decision-making and task completion. By combining system-specific metrics and metrics to evaluate agent performance, this framework provides a structured approach to evaluating efficiency, accuracy, and goal achievement, leading to more reliable AI agents.
Learn how to build a structured AI evaluation process encompassing both pre-release and post-release phases for developing robust and reliable agents in part 3 of this series. Understand agentic systems and the importance of evaluating their quality in part 1.
References
[1] https://huyenchip.com/2025/01/07/agents.html
[2] https://arxiv.org/pdf/2308.03688