Ensuring responsible AI: An overview of DeepMind’s FACTS framework

Introduction
DeepMind introduces the FACTS Grounding, an online leaderboard and benchmark designed to evaluate the factual accuracy of language models' long-form responses based on a given context in user prompts. The benchmark requires models to generate text grounded in a provided document, which can be up to 32,000 tokens long, fulfilling specific user requests. Here, AI evaluation is done in two phases: first, responses that do not fulfill the user request are disqualified, and second, the accuracy of the responses is judged based on their grounding in the provided document. Multiple judge models are used to aggregate factuality scores to minimize evaluation bias.
Factuality in LLMs
Factuality in LLMs refers to the ability to generate factually accurate responses in information-seeking scenarios. This research focuses on two main scenarios: factuality with respect to a given context (user requests and grounding documents) and factuality with respect to external sources and general world knowledge. The primary challenge in achieving factuality lies in both modeling (architecture, training, and inference) and measurement (evaluation methodology, data, and metrics). While LLM pretraining may teach models salient world knowledge, it does not directly optimize for factuality; instead, it encourages the generation of generally plausible text, aka next-word prediction.
Modeling and measurement challenges
LLMs are inherently difficult to optimize for factual accuracy due to the nature of their pretraining objectives. Post-training methods, such as supervised fine-tuning and reinforcement learning, can improve factuality but may compromise other desirable attributes like creativity and novelty. Measurement is challenging because it requires a thorough inspection of each claim in the models’ responses, especially in long-form generation tasks.
Benchmarking with FACTS Grounding
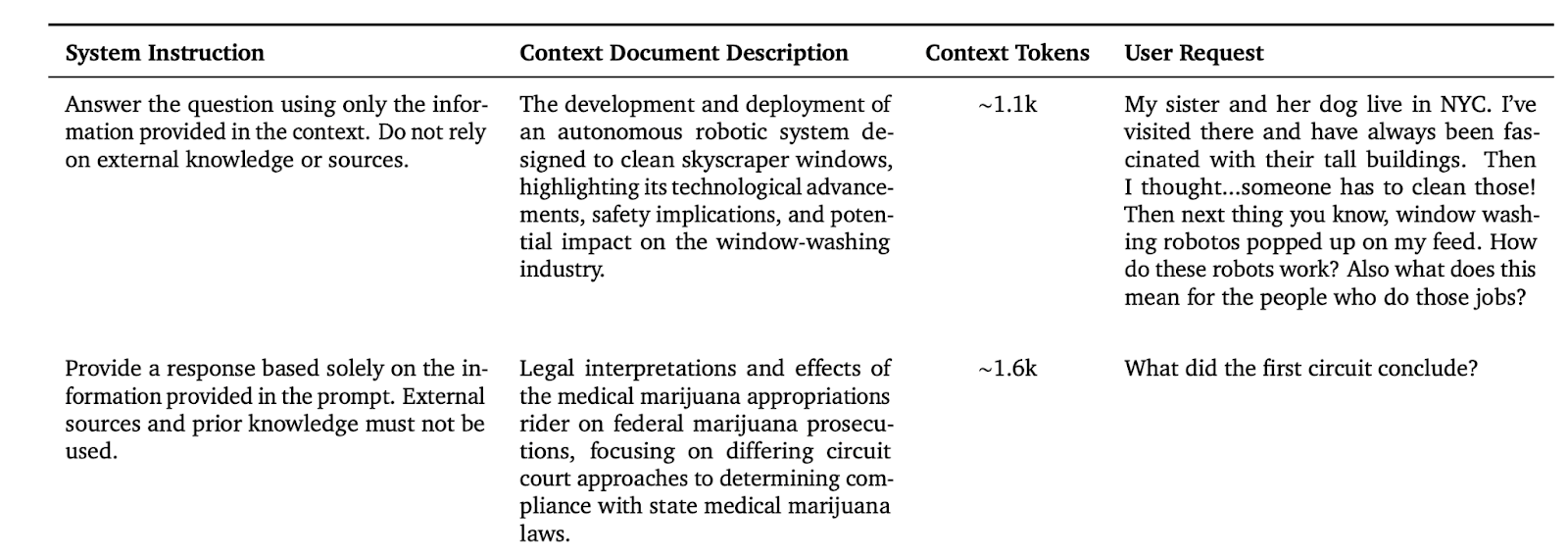
The FACTS Grounding benchmark focuses on evaluating the factuality of model responses with respect to a provided context document. It encompasses a wide range of user requests, including summarization, fact-finding, and information analysis, while ensuring responses are fully grounded in the input document. The benchmark includes 860 public examples and 859 private examples, with prompts requiring long-form input and output. Each example includes a context document, a user request, and system instructions for generating responses exclusively from the provided context.

Data quality and metrics
The evaluation set was designed to ensure models rely exclusively on the provided context, with non-trivial user requests that do not require domain expertise or complex reasoning. The final dataset contains context documents with a mean length of 2,500 tokens and a maximum length of 32,000 tokens. The factuality score is calculated by aggregating verdicts from multiple judge models after disqualifying ineligible responses.
Results
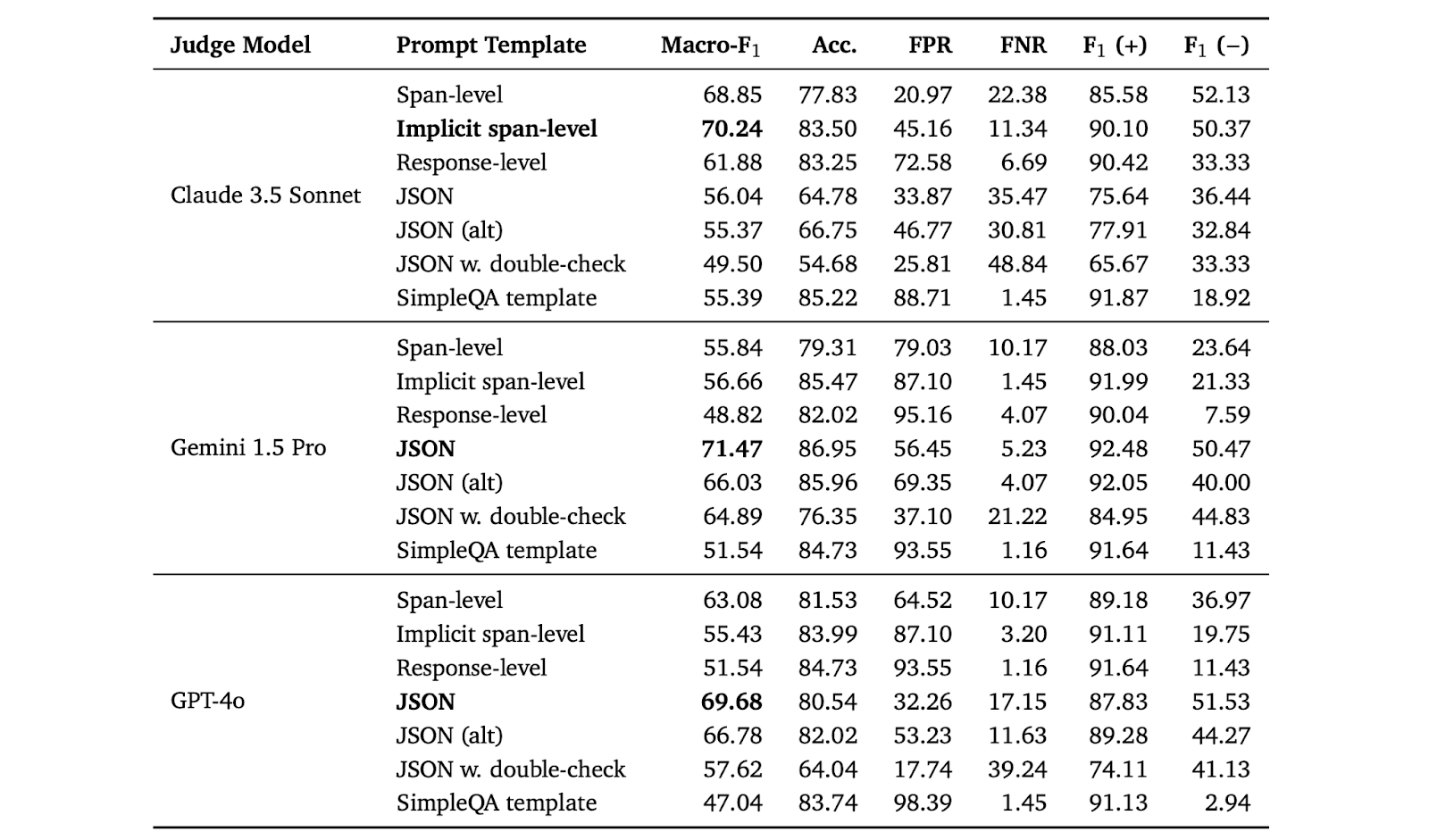
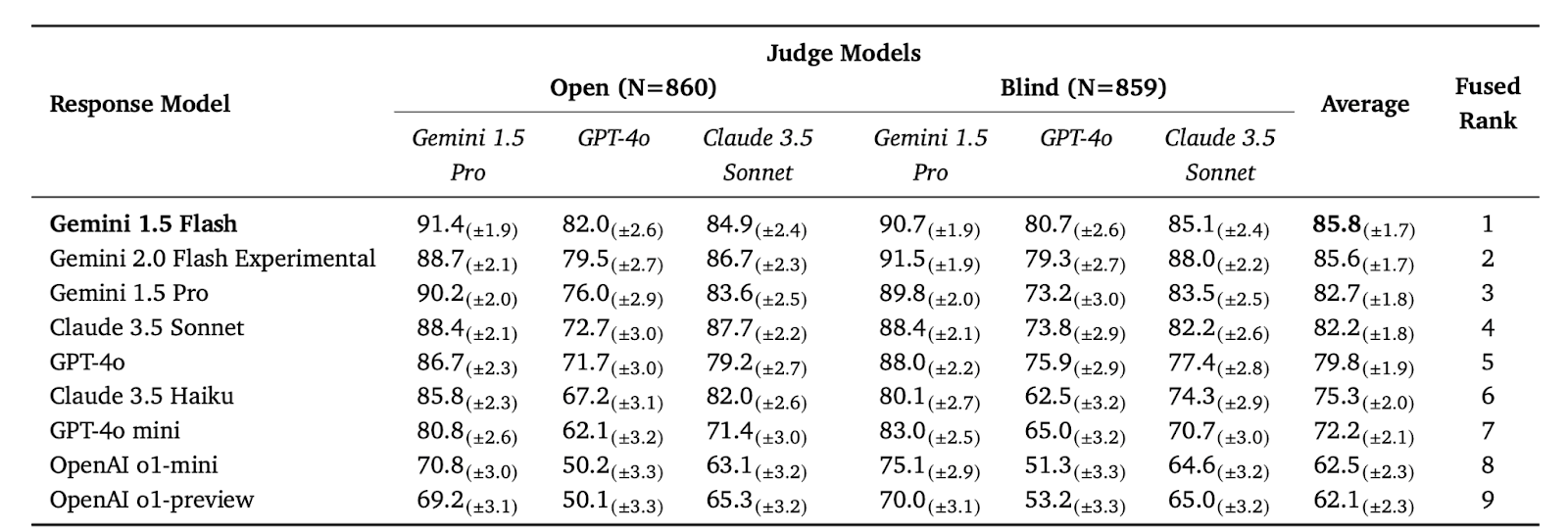
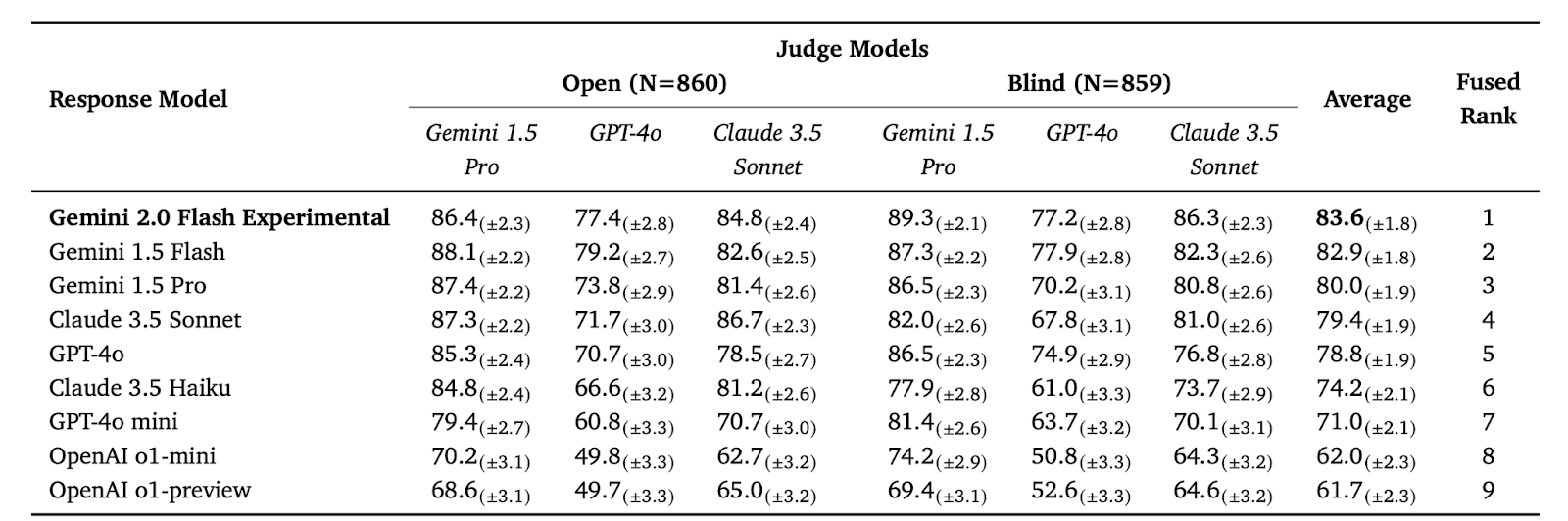
The tested models included various versions of Gemini and GPT-4o, among others. A ranking aggregation method combined the individual model rankings into a unified ranking using the Condorcet algorithm. The use of multiple judge models, while increasing computational cost, is essential to mitigate model biases. They also found that models generally rate their own outputs higher than those of other models, exhibiting a mean increase of +3.23% for LLMs as a judge. Disqualifying ineligible responses reduced the final factuality score by 1%–5% and caused minor shifts in model rankings.
Conclusion
The FACTS Grounding leaderboard is a rigorous benchmark for evaluating the factual accuracy of language models in generating long-form responses grounded in provided documents. It highlights the importance of factuality as a parameter to be considered, as models are not being trained for that purpose. This work encourages researchers to use this benchmark to advance the factual capabilities of models and improve methodologies for evaluating factuality.
Maxim is an evaluation platform for testing and evaluating LLM applications. Test your Gen AI application's performance with Maxim.


