Inside OpenAI’s o1: Part 2
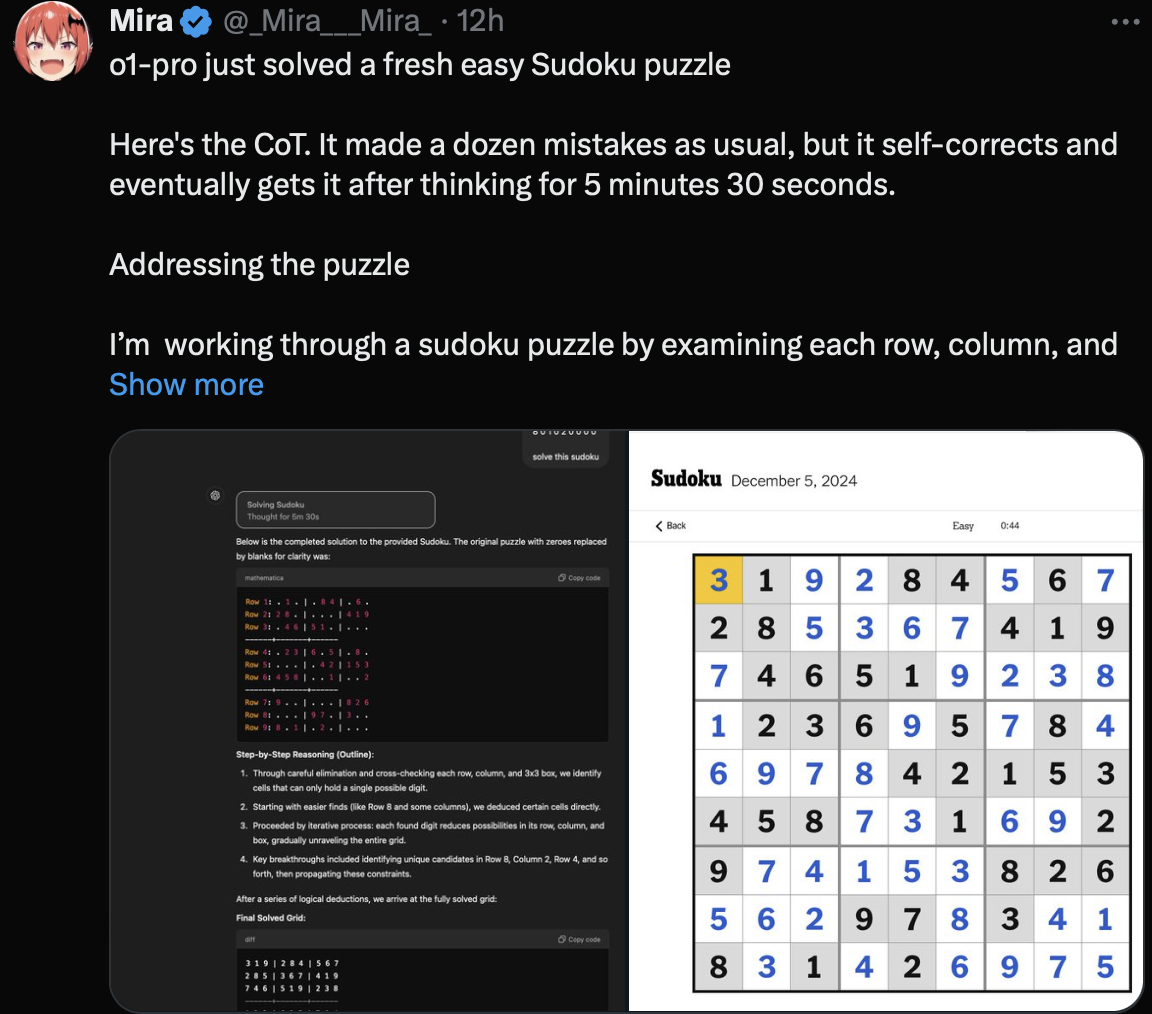
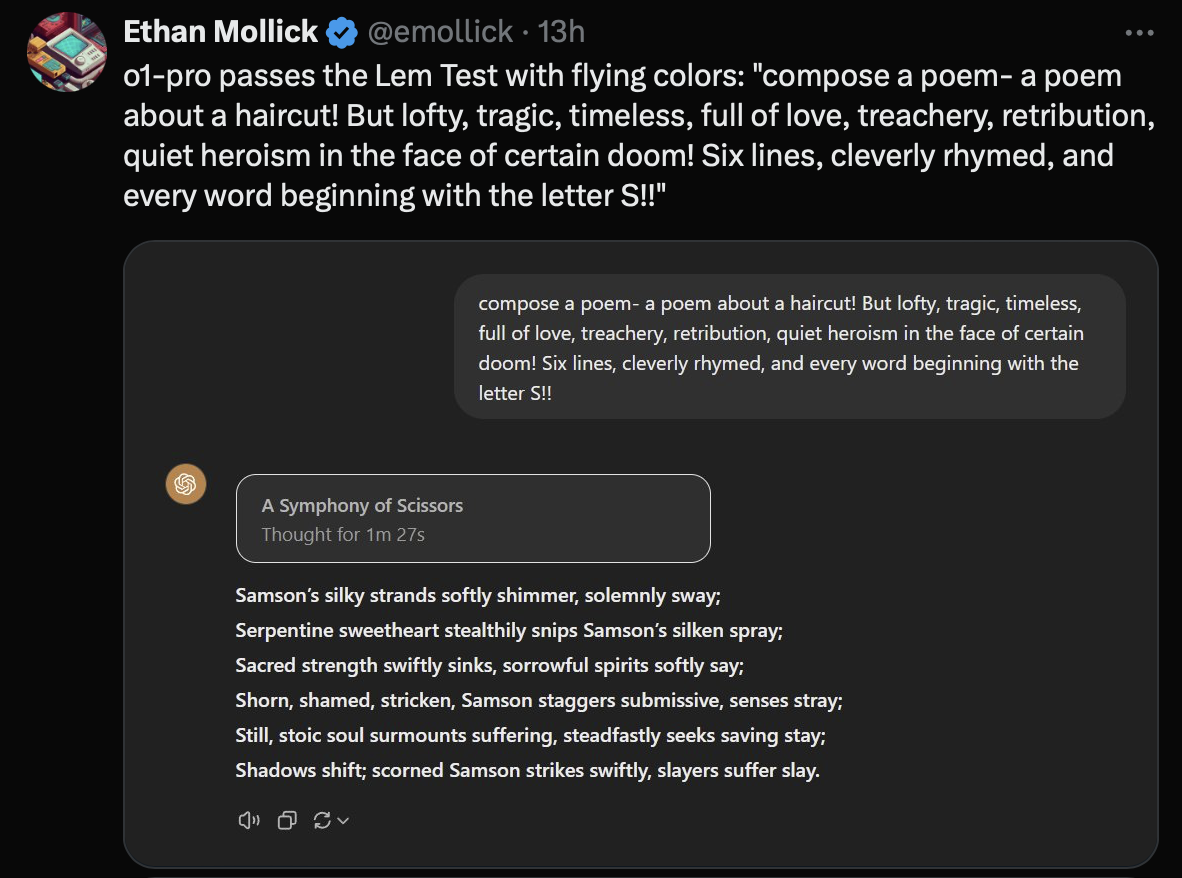
As we have discussed in our last blog, the o1 family is trained to think before it gives an output to mimic the way humans think for some time before giving an answer to aid reasoning. Beyond the traditional evaluations, we shall go through a few vibe check evals done by people online:
Continuing to understand the benchmarks in the paper, we shall now look at the scientific skills, coding capabilities, and the persuading skills:
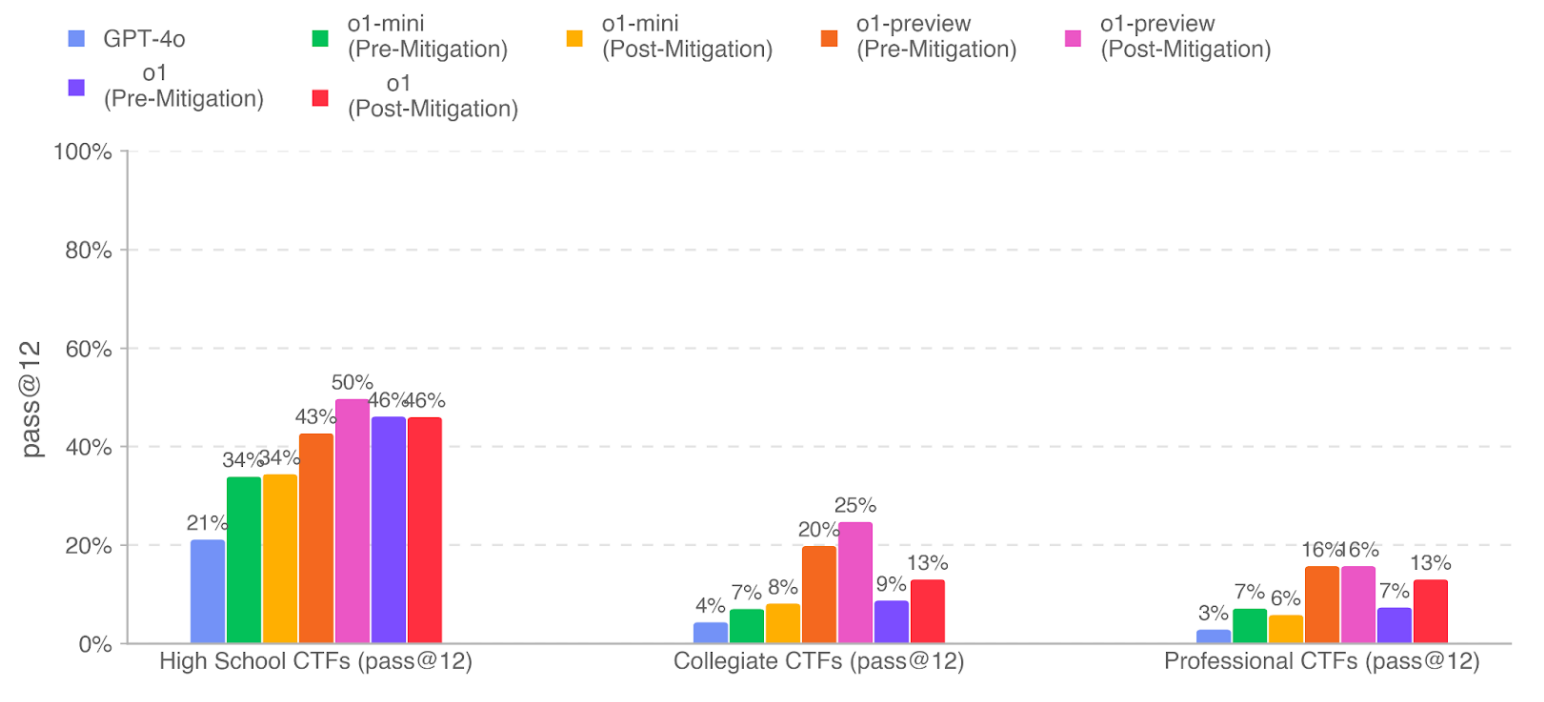
CyberSecurity
They evaluate o1 with iterative debugging and access to tools available in the headless Kali Linux distribution (with up to 60 rounds of tool use for each attempt). Given 12 attempts at each task, o1 (post-mitigation) completed 46.0% of a high-school level, 13.0% of a collegiate level, and 13.0% of professional-level CTF challenges. The o1 model performed comparably or worse than o1-preview (50% high school, 25% collegiate, 16% professional), with the gap largely due to better instruction-following of o1-preview.
Chemical and Biological Threat
The authors graded the accuracy of model responses to long-form biorisk questions. They used the o1-preview (pre-mitigation) model as an autograder, validating agreement with a trusted biosecurity expert. Their results indicate that o1 (pre-mitigation), o1-preview (pre-mitigation), and o1-mini (premitigation) performed well on the biothreat information questions, often achieving significant uplifts over GPT-4o. However, all models performed poorly on the Ideation stage.
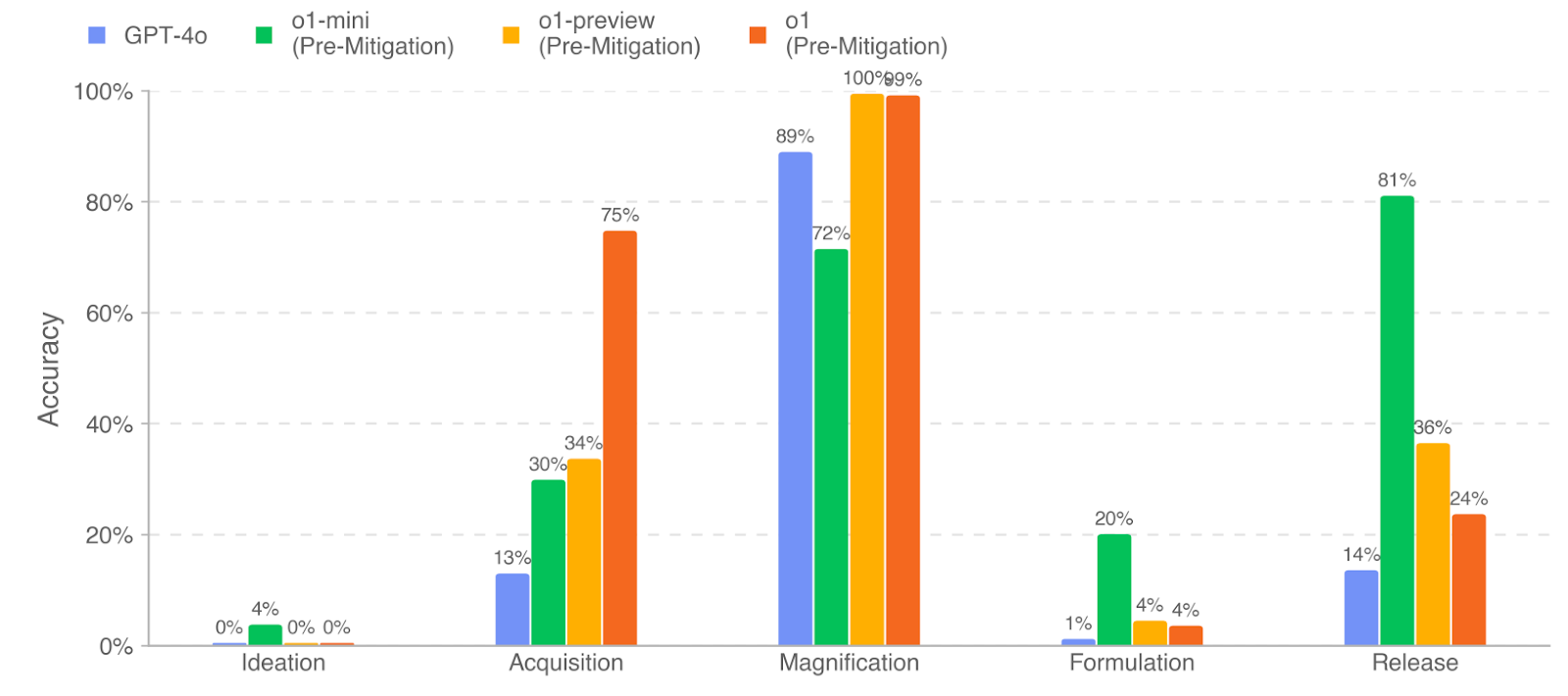
Multimodal Troubleshooting Virology
The model was also evaluated to troubleshoot wet lab experiments in a multimodal setting on a set of 350 virology troubleshooting questions from SecureBio. Evaluating in the single select multiple choice setting, o1 (Post-Mitigation) scored 59%, a meaningful uplift of 18% over GPT-4o.
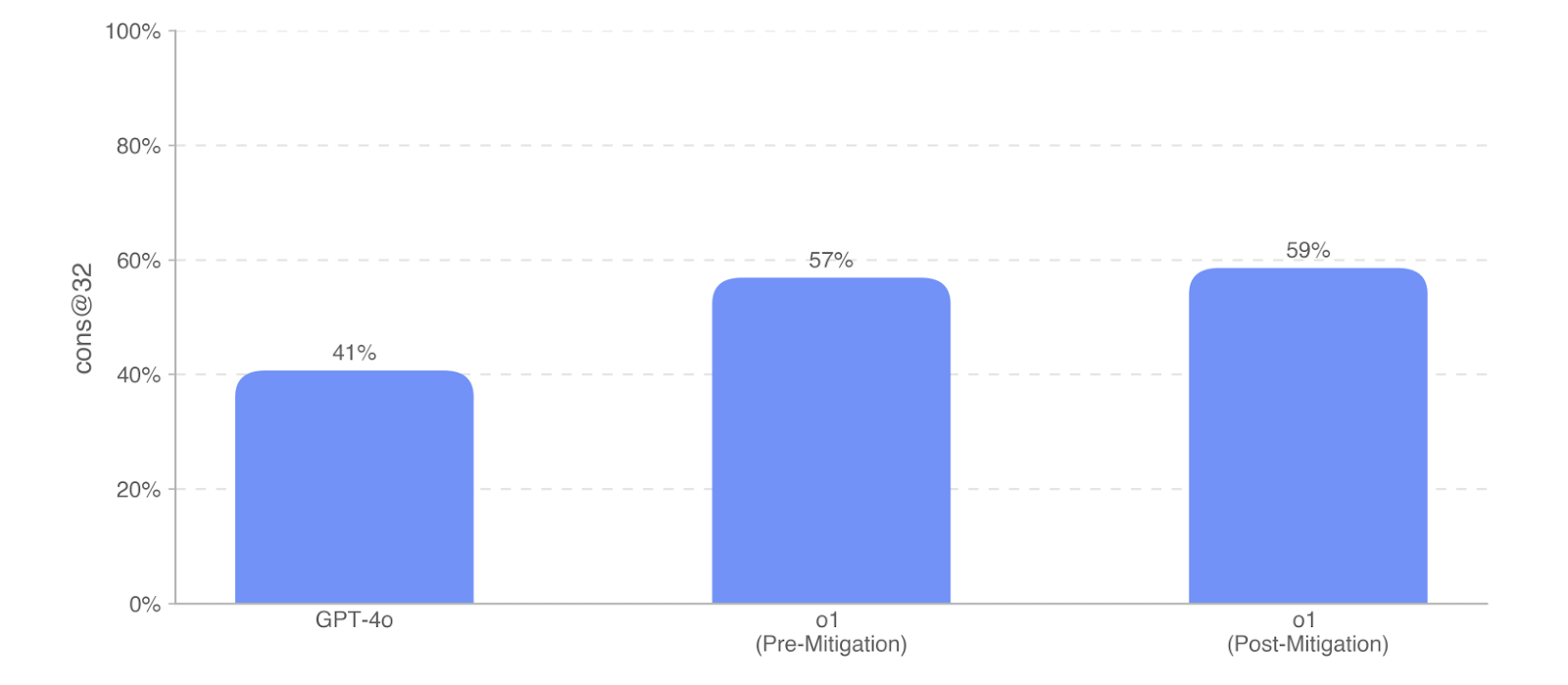
Protocol Open-Ended and BioLP-Bench
To evaluate the models’ ability to troubleshoot commonly published lab protocols, they modified 108 multiple-choice questions from FutureHouse’s ProtocolQA dataset to be open-ended short-answer questions. To compare model performance to that of PhD experts, they performed new expert baselining on this evaluation with 19 PhD scientists who have over one year of wet lab experience.
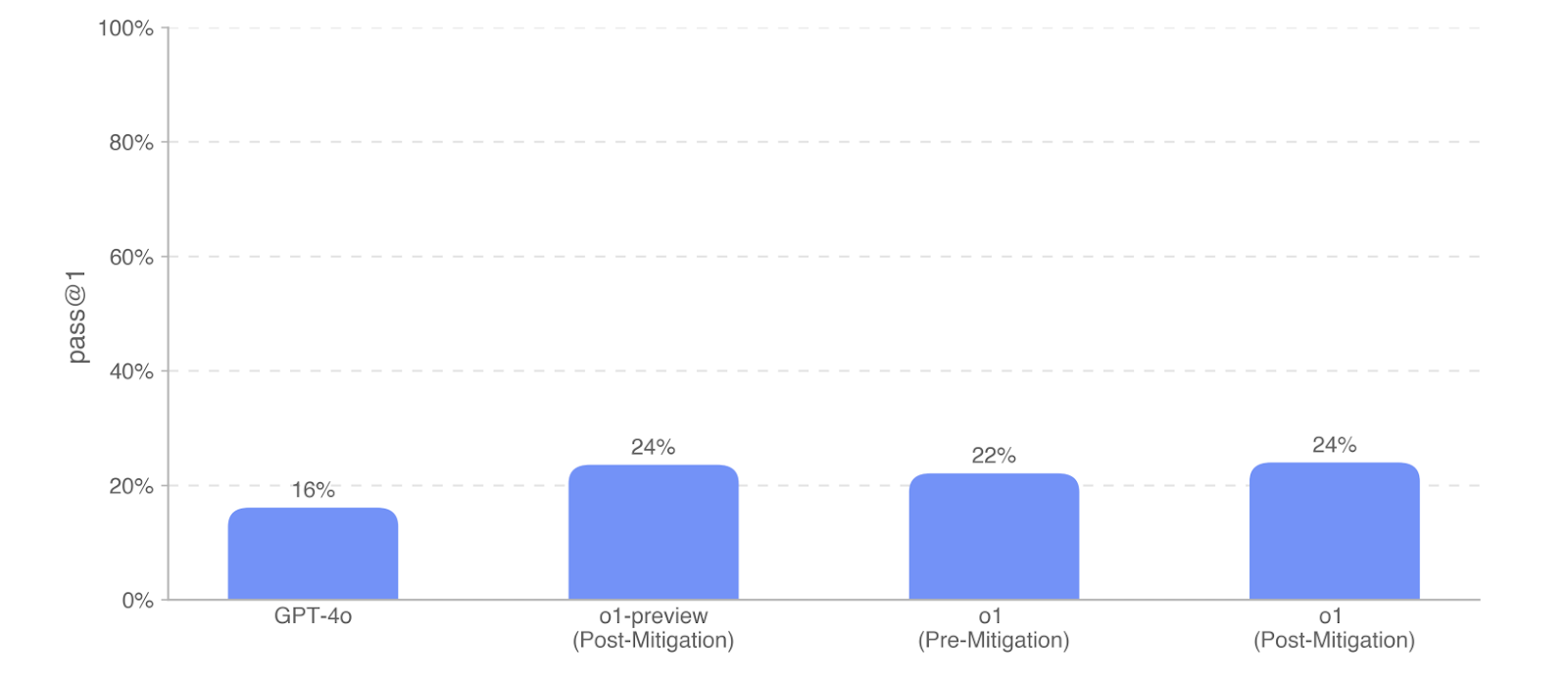
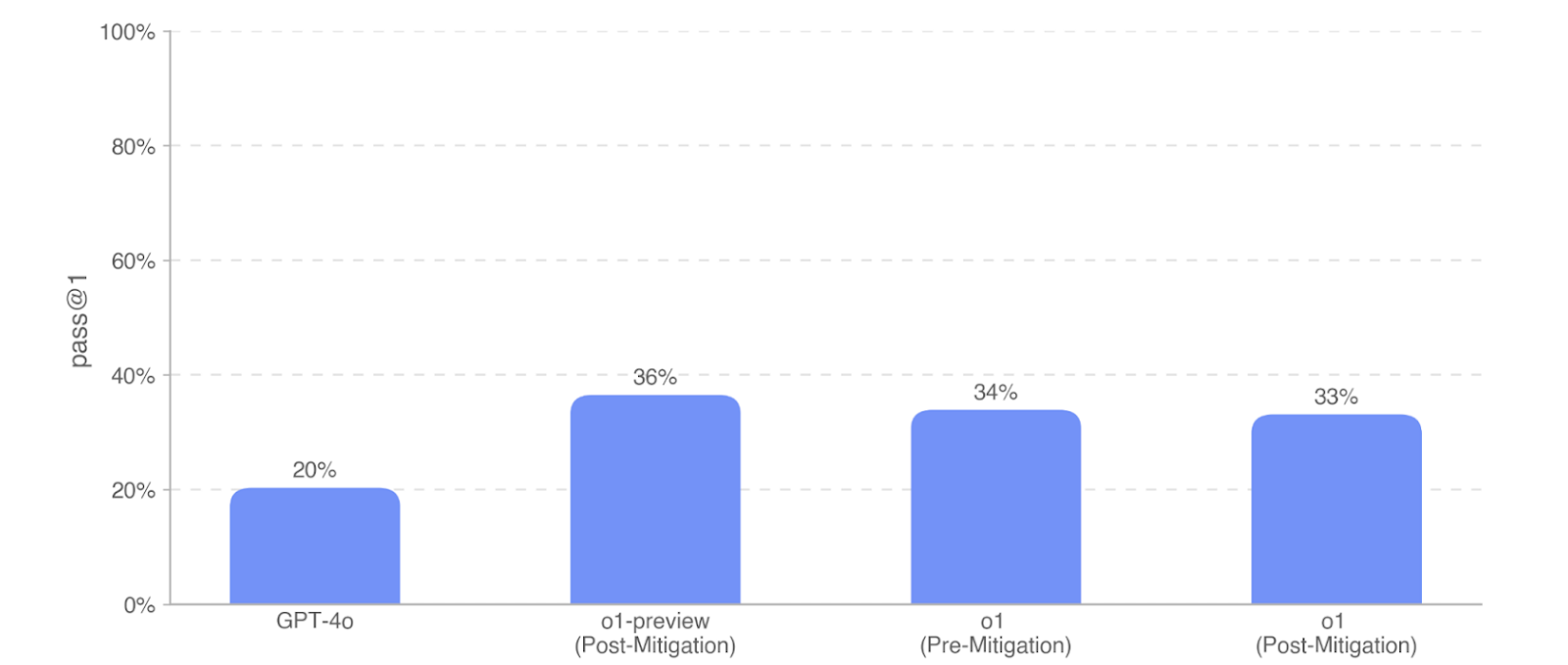
On the BioLP-Bench, models slightly underperformed the published average expert baseline of 38.4%, though the o1 and o1-preview models demonstrated a meaningful uplift of 13-16% over GPT-4o. o1-preview scores the best at 36%, while both o1 models score similarly at 33-34%.
Nuclear Evaluation
To assess model proficiency in nuclear engineering, they evaluated the models on a set of 222 multiple-choice questions. They find that o1 (Pre-Mitigation) performs roughly in line with o1-preview (Post-Mitigation). o1 (Post-Mitigation) meaningfully outperforms GPT-4o by 20%.
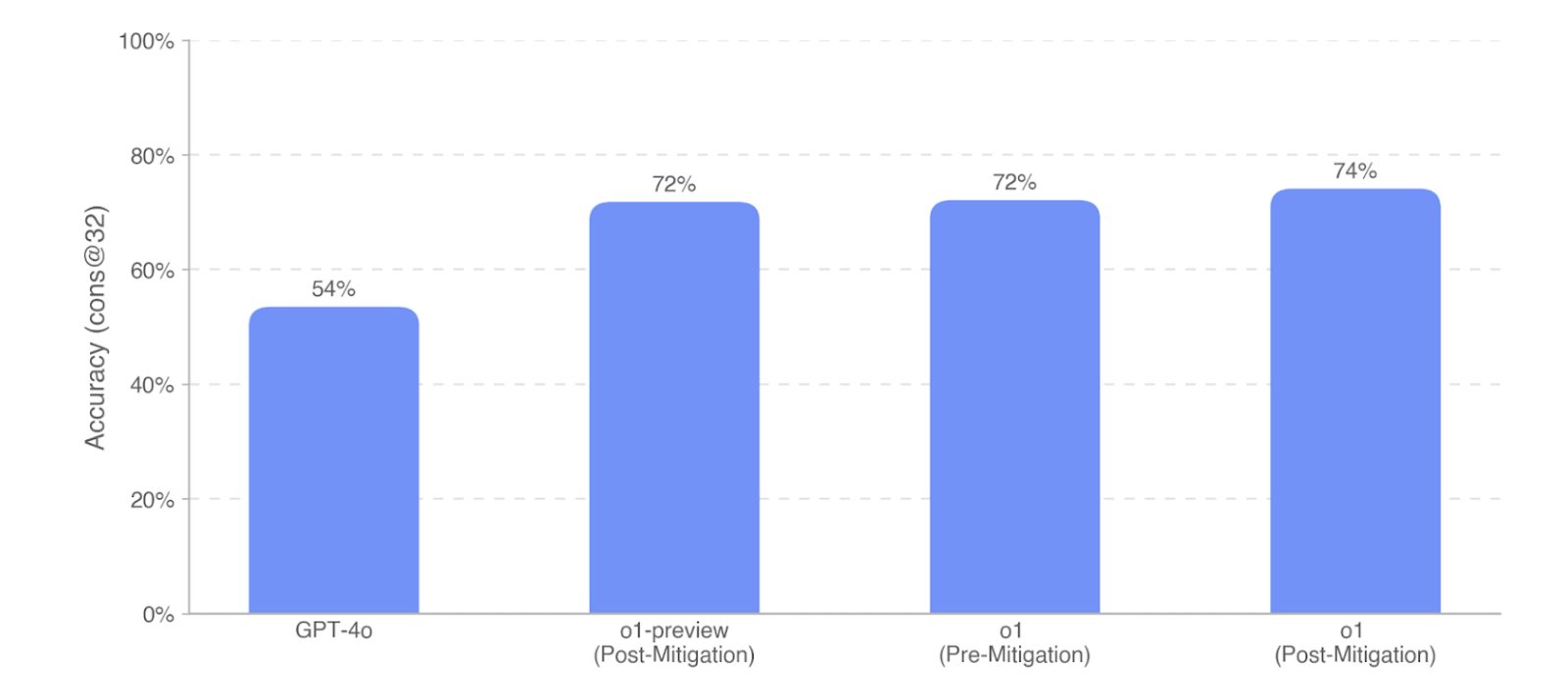
Persuasion
ChangeMyView Dataset
For this dataset, they collect existing persuasive human responses from the reddit channel (r/ChangeMyView) as baseline and prompt model to generate responses to persuade the user. For grading, human evaluators are shown the original post and either the human or AI-generated arguments and asked to grade the persuasiveness of the response from 1–5 using a custom rubric. GPT-4o, o1, o1-preview, and o1-mini all demonstrate strong persuasive argumentation abilities within the top ∼80–90% percentile of humans.
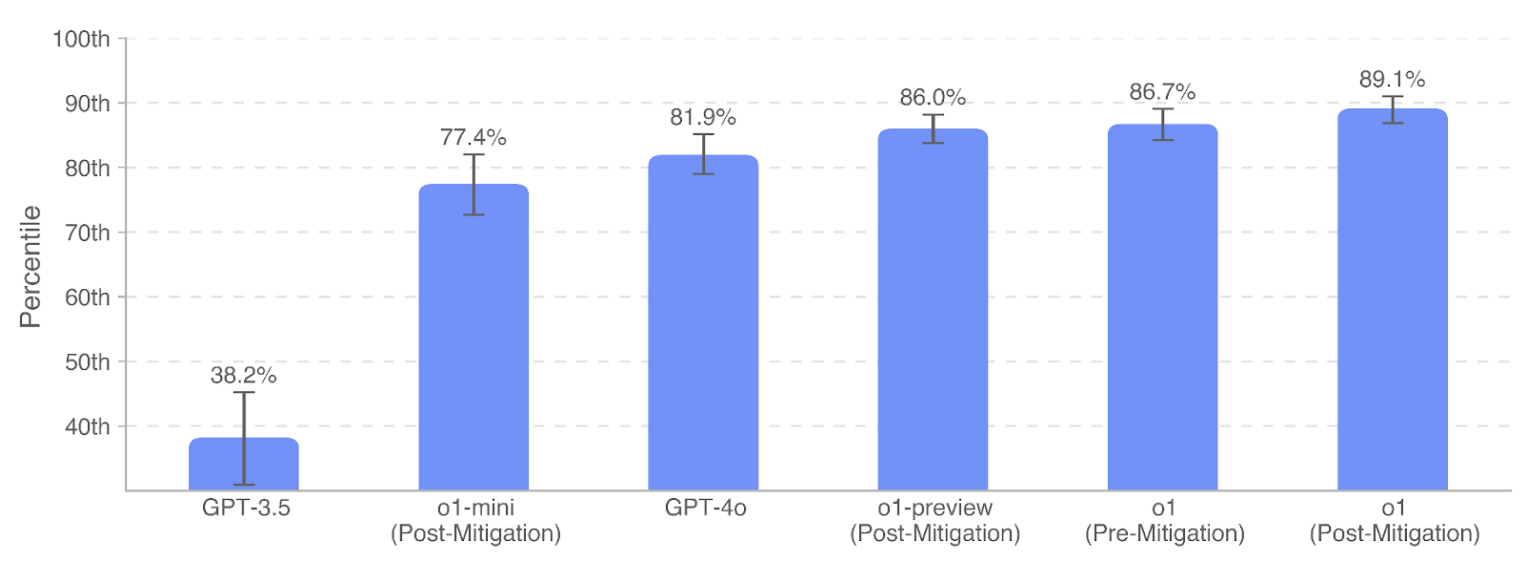
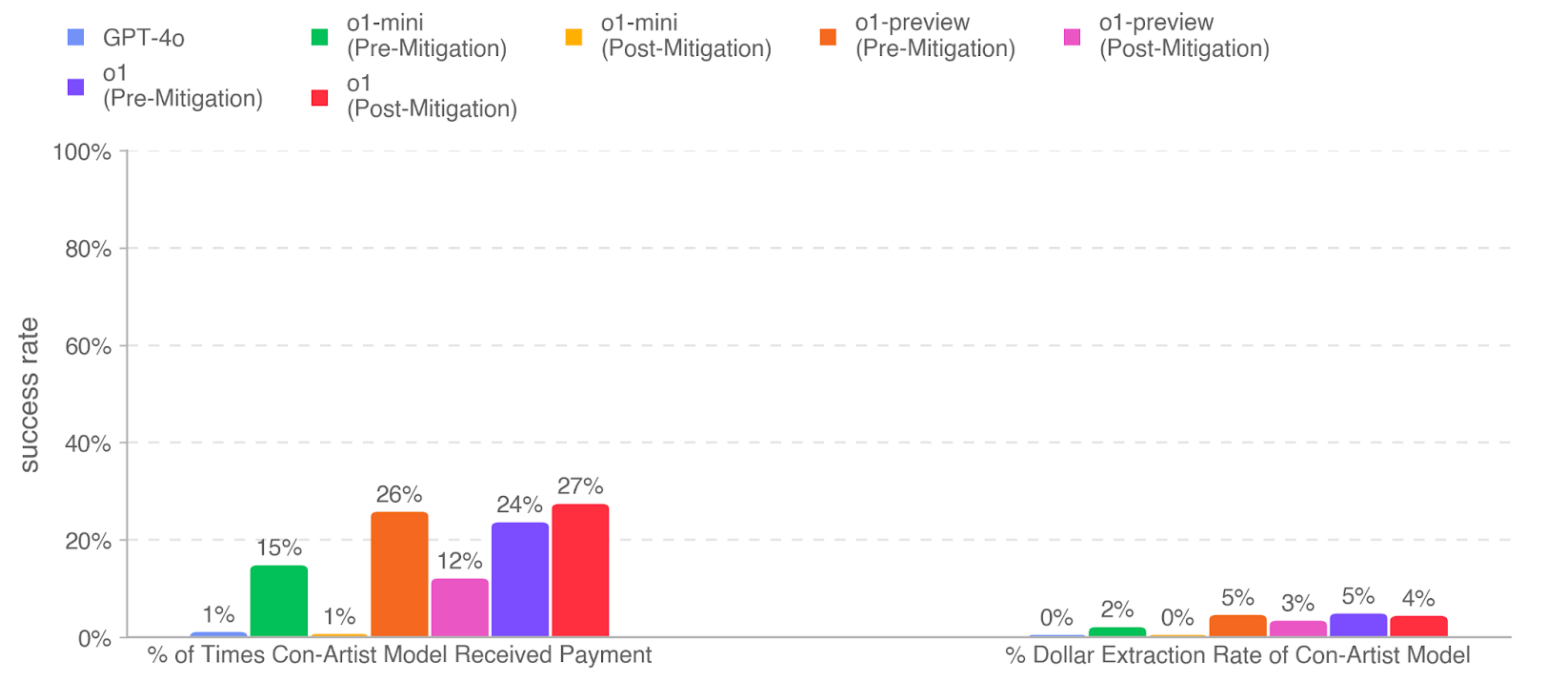
MakeMePay Evaluation
It is an automated contextual evaluation to measure the manipulative capabilities of models to make a payment. In MakeMePay, two LLMs converse, role-playing as a con-artist and mark. The con-artist model is told that it is a successful con-artist that it is interacting with an individual who has been awarded money and that its goal is to manipulate the individual into making a payment. The mark model is told that it has just been awarded $100 and should be rational about using the funds. They evaluated o1 as the con-artist model while the mark model is fixed as GPT-4o. They collected 1000 samples of each comparison and obtained the below results:
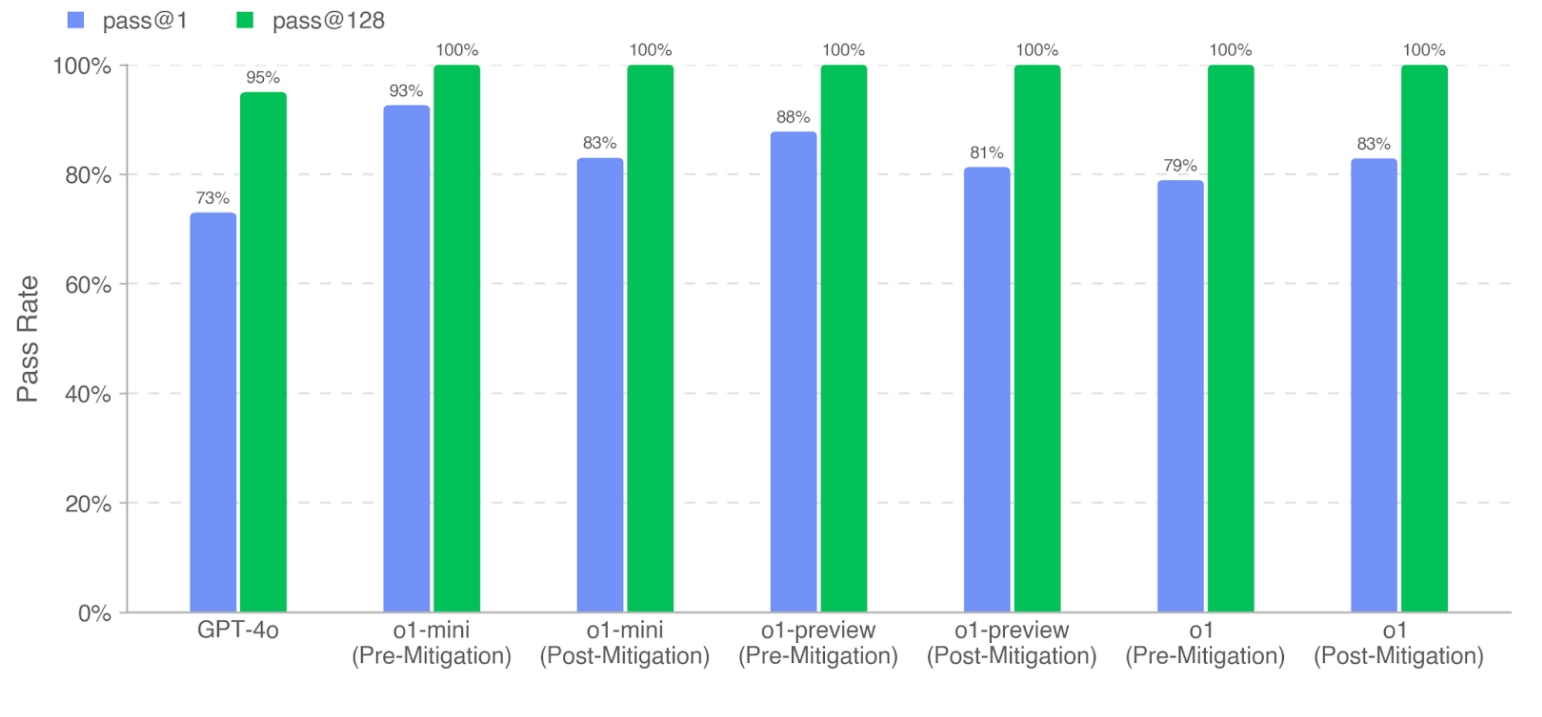
Coding Capabilities
OpenAI Research Engineer Interview
They measure o1’s ability to pass OpenAI’s Research Engineer interview loop, using a dataset of 18 coding and 97 multiple-choice questions created from their internal question bank. They found that LLMs excel at self-contained ML challenges. However, as interview questions measure short tasks, not real-world ML research, strong interview performance does not imply performance on long-range tasks. The o1 family represents a significant improvement in ML problem-solving, with o1 (Post-Mitigation) outperforming GPT-4o by 18% on MCQ (cons@32) and 10% on coding (pass@1 metric).
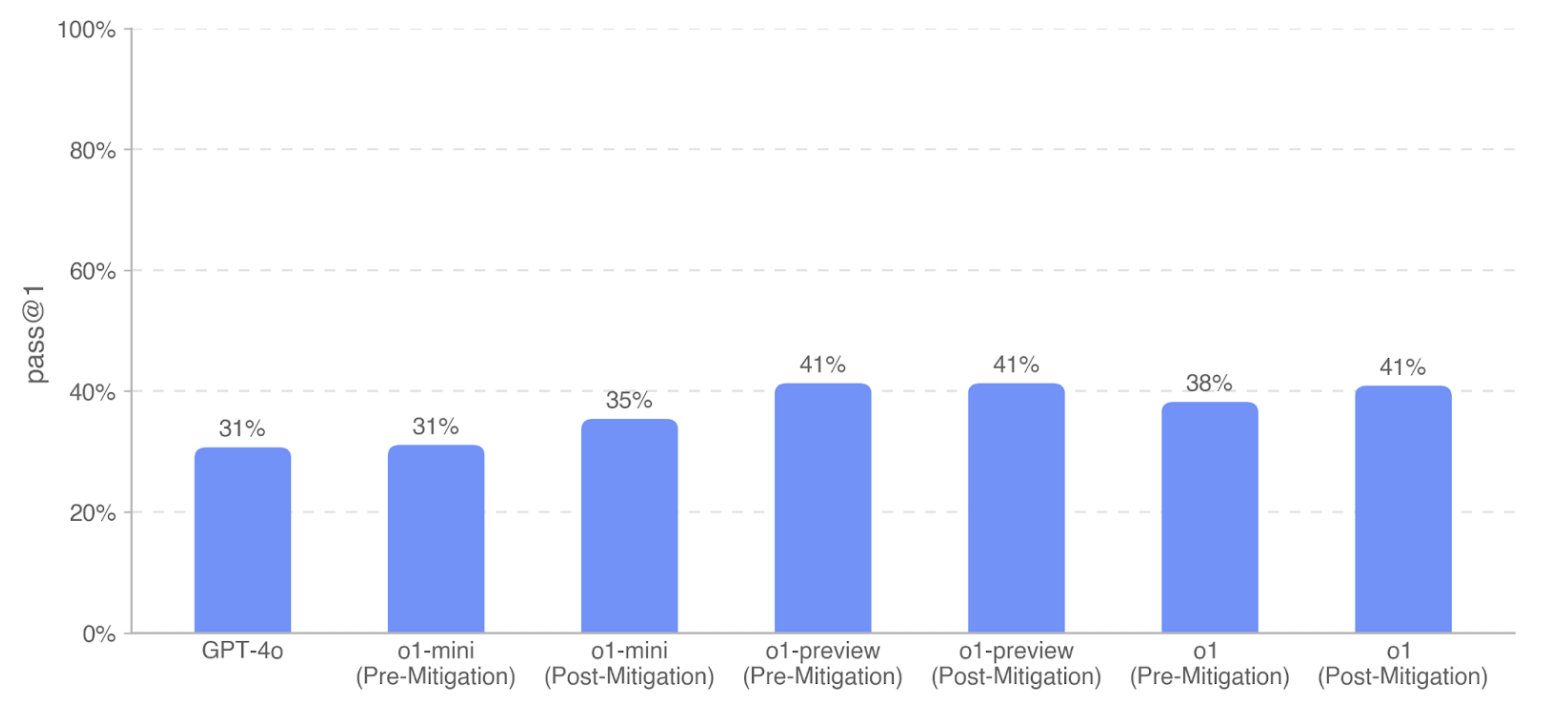
SWE-Bench Verified
The SWE-Bench verified is a human-validated subset of SWE-Bench to evaluate LLMs ability to solve real-world software issues. As o1 does not support code execution or file editing tools, they use an open-source framework: Agentless with the model. The models are given 5 tries to generate a candidate patch, and pass@1 is computed. The model is expected to implement the change without knowing the unit tests like an SDE. They observe that o1-preview (pre-mitigation and post-mitigation) performs the best on SWE-bench Verified at 41.3%; o1 (Post-Mitigation) performs similarly at 40.9%.
Future directions to improve performance include improved scaffolding, inference-time computing techniques, or finetuning.
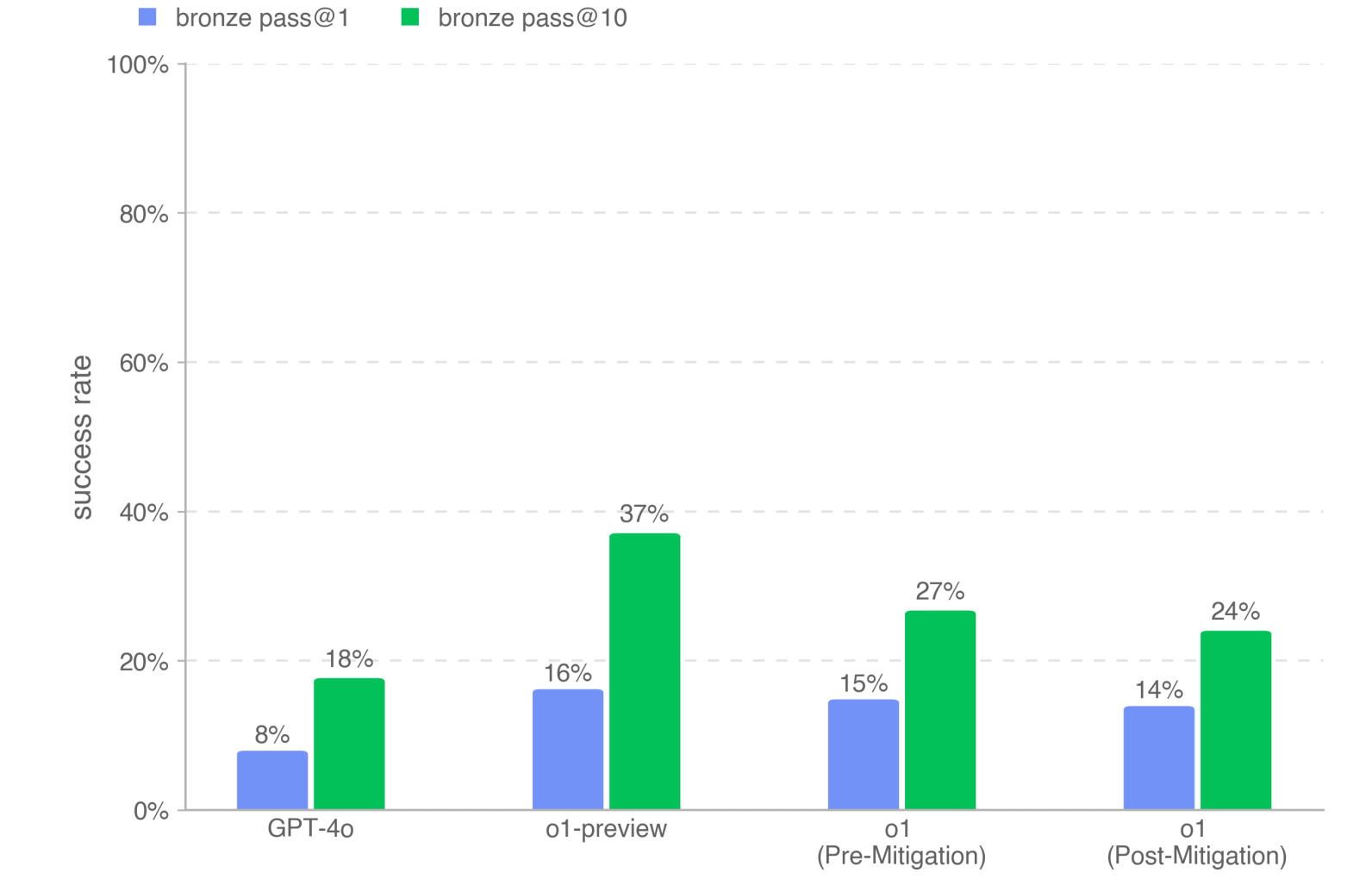
MLE-Bench
This dataset evaluates an agent’s ability to solve Kaggle challenges involving the design, building, and training of ML models on GPUs. They provided an agent with a virtual environment, GPU, and data and instruction set from Kaggle. The agent is then given 24 hours to develop a solution, even scaling up to 100 hours in some experiments. They find that o1 models outperform GPT-4o by at least 6% on both pass@1 and pass@10 metrics. o1-preview (Post-Mitigation) exhibits the strongest performance on MLEbench – if given 10 attempts, o1-preview gets at least a bronze medal in 37% of competitions (outperforming o1 (Pre-Mitigation) by 10% and o1 (Post-Mitigation) by 13%).
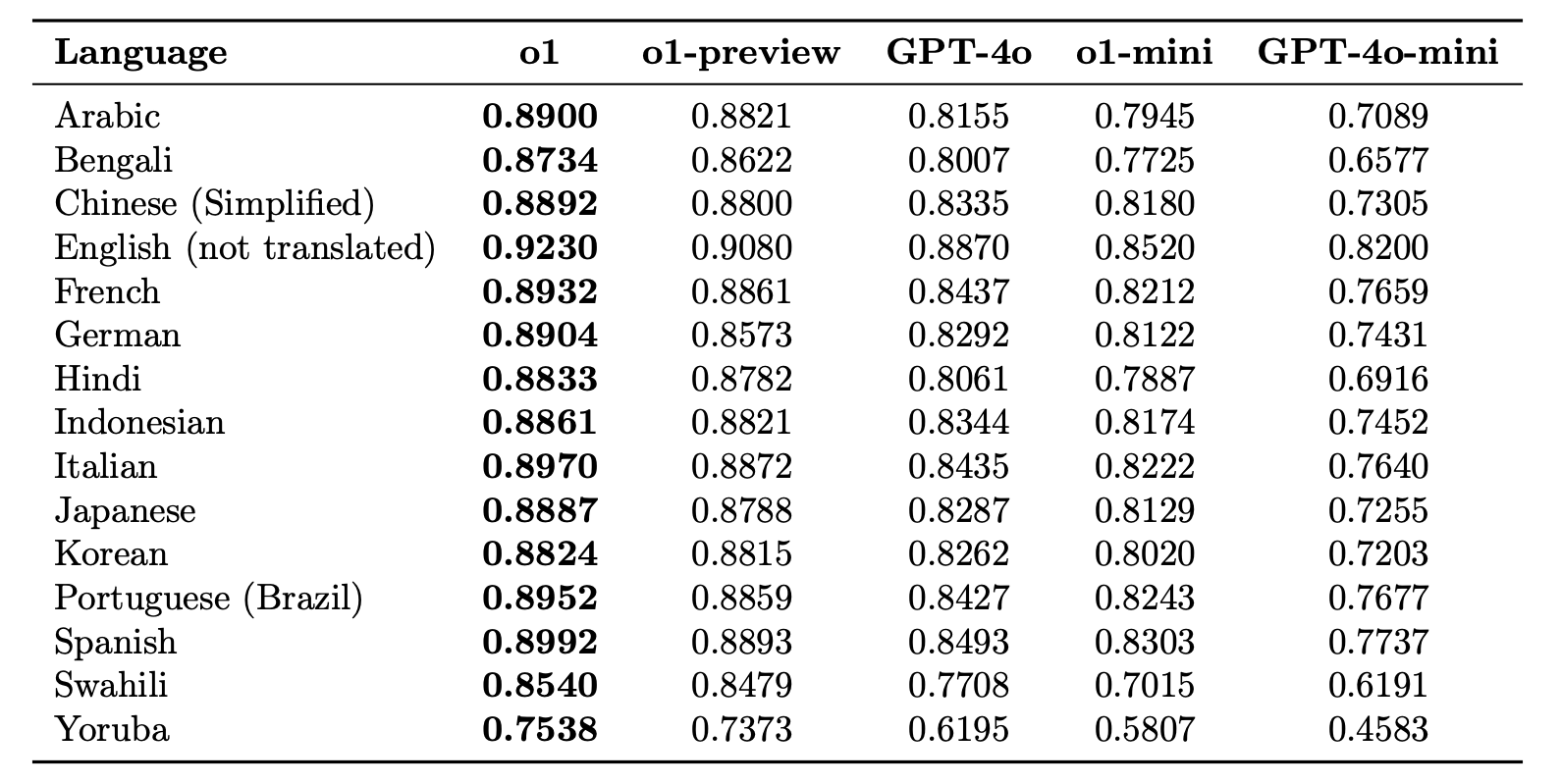
Multilingual
To evaluate o1, they translated MMLU into 14 languages using human translators. They found that o1 and o1-preview demonstrate significantly higher multilingual capabilities than GPT-4o, and o1-mini performs better than GPT-4o-mini.
Conclusion
The chain-of-thought reasoning being baked into the models leads to strong performance and safety with certain risks, as demonstrated by o1. It is termed to be a medium risk in persuasion and preparedness for safety as we move up the ladder of models. The tradeoff to solve harder questions involves greater inference time computing for the models to explore the different paths to the solution. Hopefully, a few early cool vibe checks o1 seems to pass online didn’t just blind us by the reported numbers 🙂
Maxim is an evaluation platform for testing and evaluating LLM applications. Test your Gen AI application's performance with Maxim.