Long-context LLMs vs RAG

Introduction
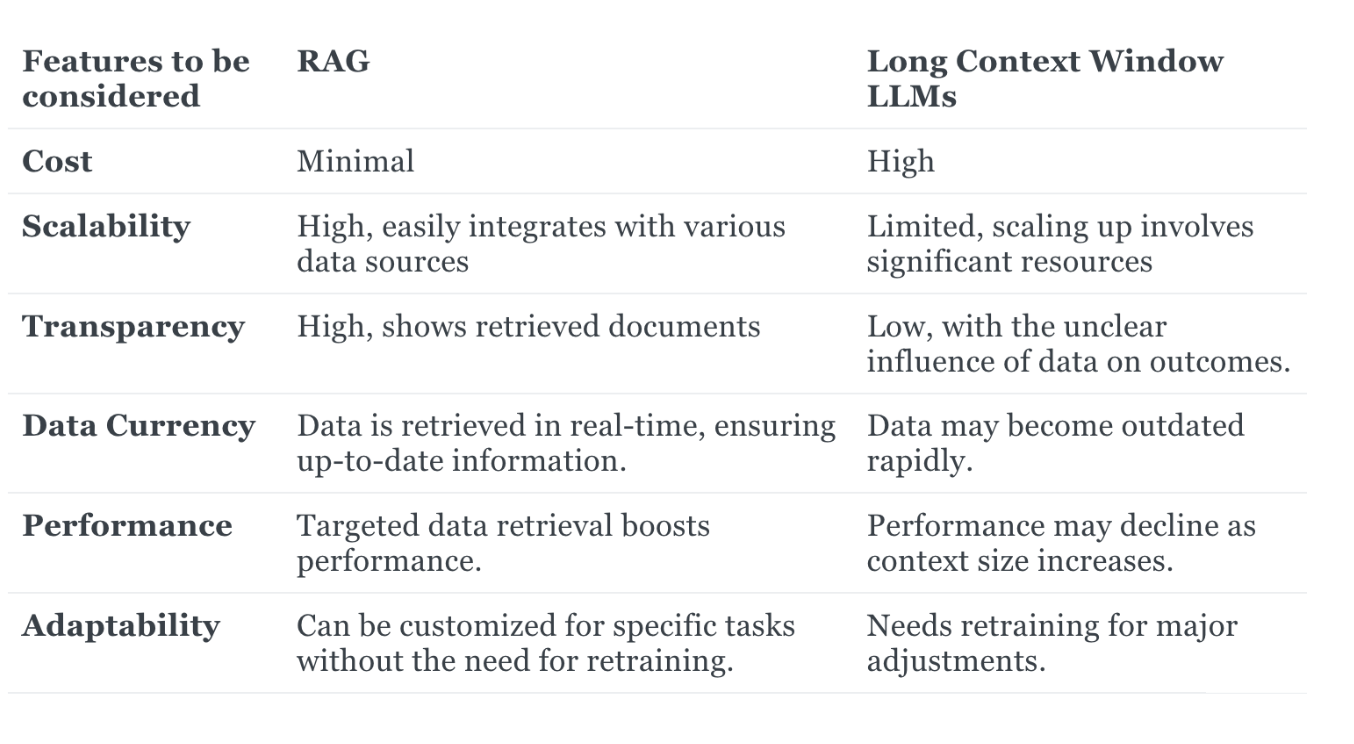
In this blog, we explore the evolving landscape of large language models (LLMs) and their approaches to handling extensive text and complex queries. We delve into the capabilities of long-context LLMs, which excel at managing large volumes of information but come with high computational costs. In contrast, we examine Retrieval-Augmented Generation (RAG) models, which enhance performance by integrating external knowledge and are particularly effective for specific tasks such as closed questions and complex document comprehension.
What are long-context LLMs?
Long context LLMs are models that have a larger context window, enabling them to retain more text in a kind of working memory. This capacity helps the models keep track of key moments and details in extended conversations, lengthy documents, or large codebases. As a result, these models can generate responses that are coherent not only in the immediate moment but also over a longer context.
What problems do long-context LLMs solve?
Long context LLMs address the limitations of standard models by allowing for a larger context window, which enables them to process and retain more text at once. This helps to mitigate the "needle in a haystack" problem, where stuffing too much text into a limited context window can reduce the model's ability to understand and recall relevant information. By extending the context window, long context LLMs can handle more extensive inputs without suffering from the performance degradation observed in standard models when processing large amounts of text.
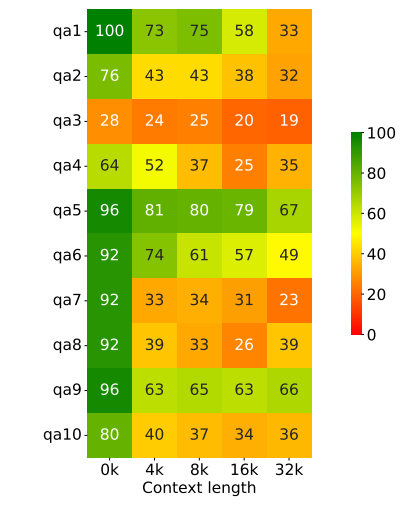
In the research paper "In Search of Needles in a 11M Haystack: Recurrent Memory Finds What LLMs Miss" they found, mistarl-medium model's performance scales only for some tasks but quickly degenerates for majority of others as context grows. Every row shows accuracy in % of solving corresponding BABILong task ('qa1'-'qa10') and every column corresponds to the task size submitted to mistarl-medium with 32K context window.
Why are long-context LLMs expensive?
Large context LLMs are expensive because, according to the quadratic scaling rule, when the length of a text sequence doubles, the LLM requires four times as much memory and computing power to process it. This exponential increase in resource demands makes handling long contexts costly. Recent research has proposed methods like prompt compression, model distillation, and LLM cascading to reduce these costs.
What is RAG?
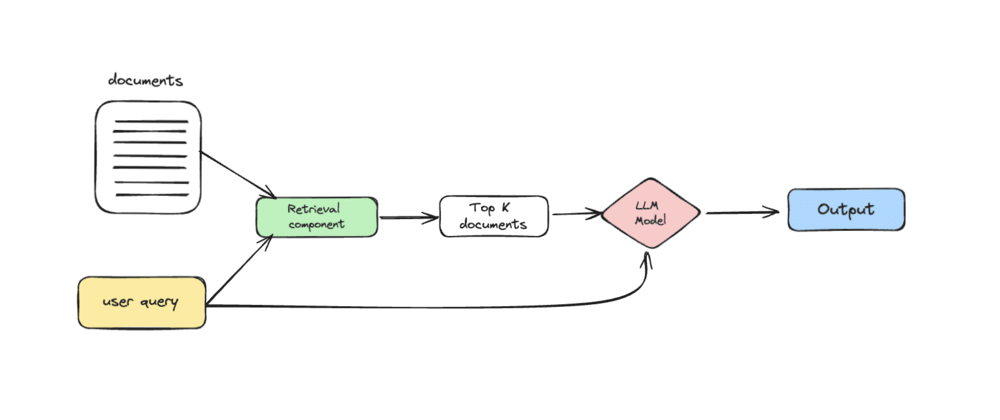
RAG is a process designed to enhance the output of a large language model (LLM) by incorporating information from an external, authoritative knowledge base. This approach ensures that the responses generated by the LLM are not solely dependent on the model's training data. Large Language Models are trained on extensive datasets and utilize billions of parameters to perform tasks such as answering questions, translating languages, and completing sentences. By using RAG, these models can tap into specific domains or an organization's internal knowledge base without needing to be retrained. This method is cost-effective and helps maintain the relevance, accuracy, and utility of the LLM's output in various contexts.
Comparative studies on long-context LLMs and RAGs
A study by Google Deep Mind and the University of Michigan
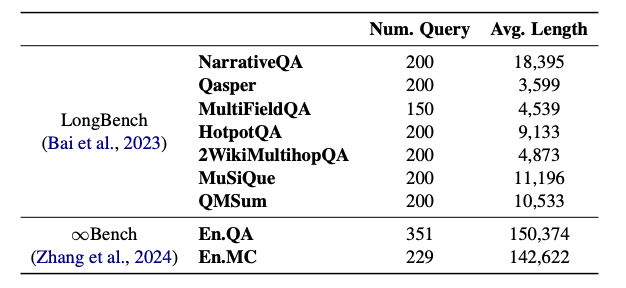
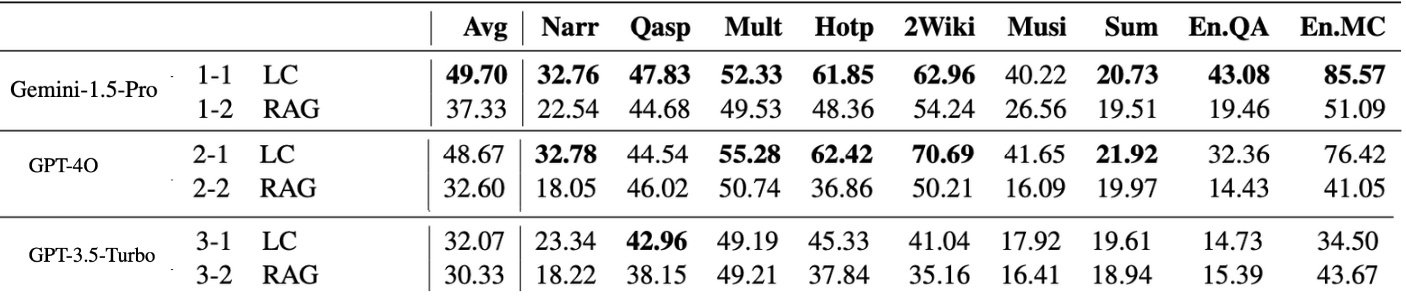
In the study "Retrieval Augmented Generation or Long-Context LLMs? A Comprehensive Study and Hybrid Approach," the authors compared the performance of long-context LLMs and RAG. They tested three advanced LLMs: Gemini-1.5-Pro (Google, 2024), supporting up to 1 million tokens; GPT-4o (OpenAI, 2024), supporting 128k tokens; and GPT-3.5-Turbo (OpenAI, 2023), with a 16k token limit. For RAG, they used two retrievers: Contriever, a dense retriever excelling on BEIR datasets. Long contexts were chunked into 300-word segments, selecting the top 5 based on cosine similarity for processing. They then benchmarked the performance of LC and RAG across nine datasets: six from LongBench—Narr, Qasp, Mult, Hotp, 2Wiki, and Musi—and two from InfiniteBench—EnQA and EnMC.
Results
LC LLMs consistently outperform RAG across all three models, with LC surpassing RAG by 7.6% for Gemini-1.5-Pro, 13.1% for GPT-4O, and 3.6% for GPT-3.5-Turbo. The performance gap is notably larger for the newer models, highlighting their superior long-context understanding.
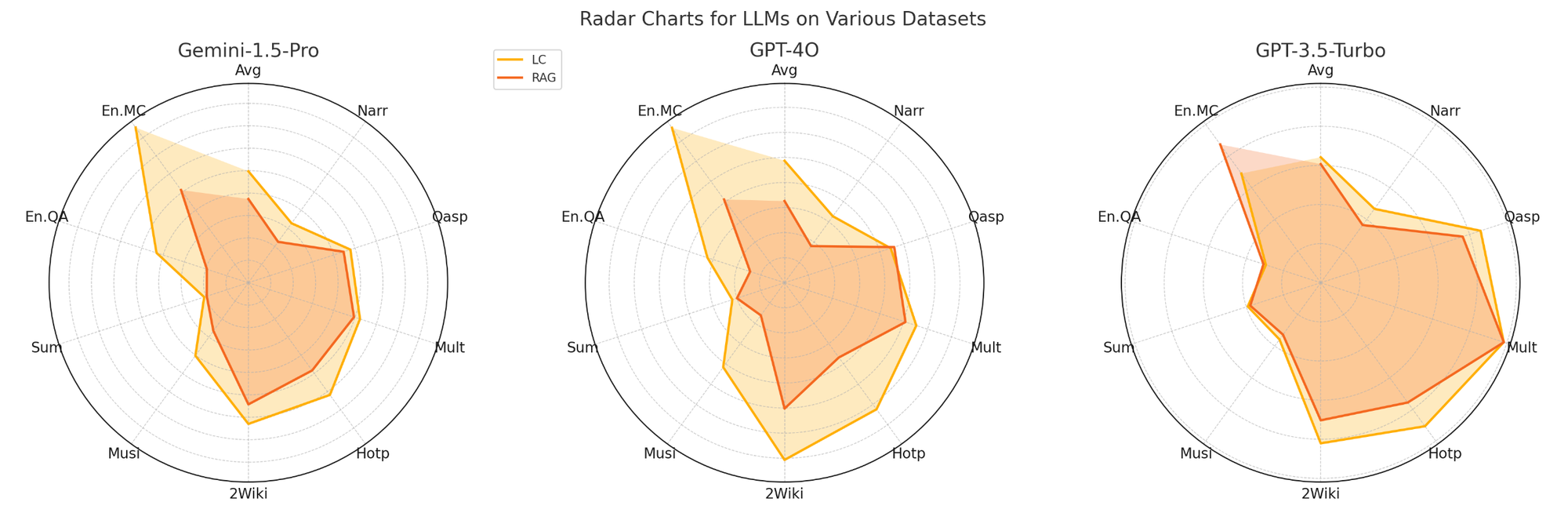
An exception is observed with the two longer ∞Bench datasets (EnQA and EnMC), where RAG outperforms LC for GPT-3.5-Turbo.
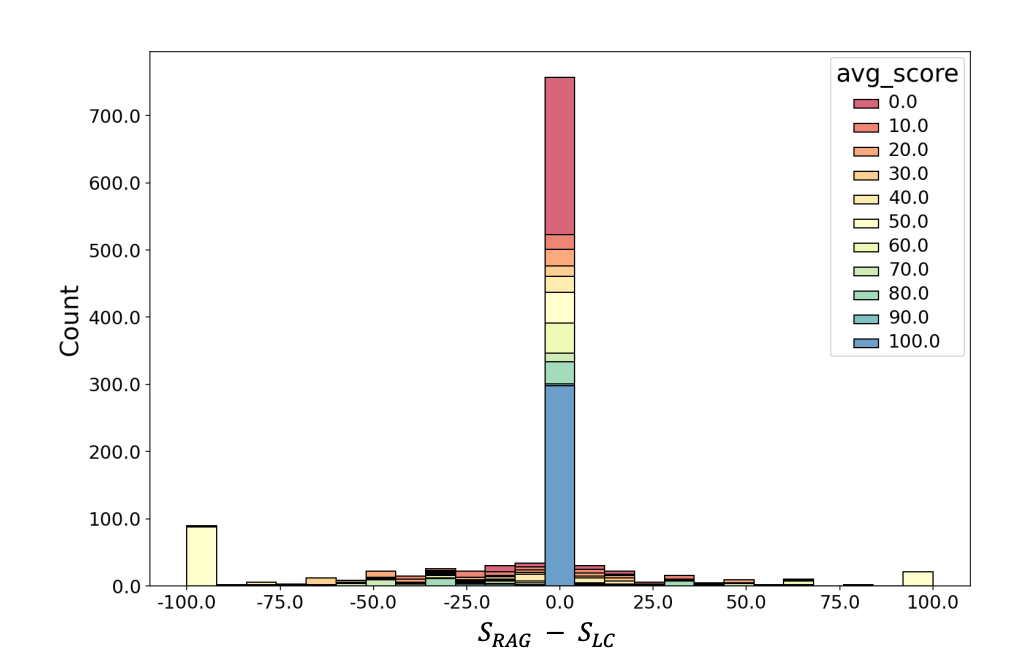
The study further shows that RAG and LC scores are closely aligned for most queries. In fact, the model predictions match exactly for 63% of queries, and in 70% of cases, the score difference is less than 10 in absolute value.
A study by Iowa State University and Pacific Northwest National Laboratory
In this study, the researchers explore how large language models (LLMs) help understand the complex documents associated with the National Environmental Policy Act (NEPA). To do this, they introduce a new benchmark called NEPAQuAD, which is a benchmark for evaluating LLMs on NEPA-related questions. It uses GPT-4 to generate questions from Environmental Impact Statement (EIS) passages, with answers and supporting text reviewed by experts for accuracy.
The study examines three advanced LLMs—Claude Sonnet, Gemini, and GPT-4—designed to manage large contexts across different settings. It finds that NEPA documents pose significant challenges for these models, particularly in understanding complex semantics and processing lengthy texts. Additionally, the researchers implement an RAG approach based on the methodology described in the research paper here.
Results
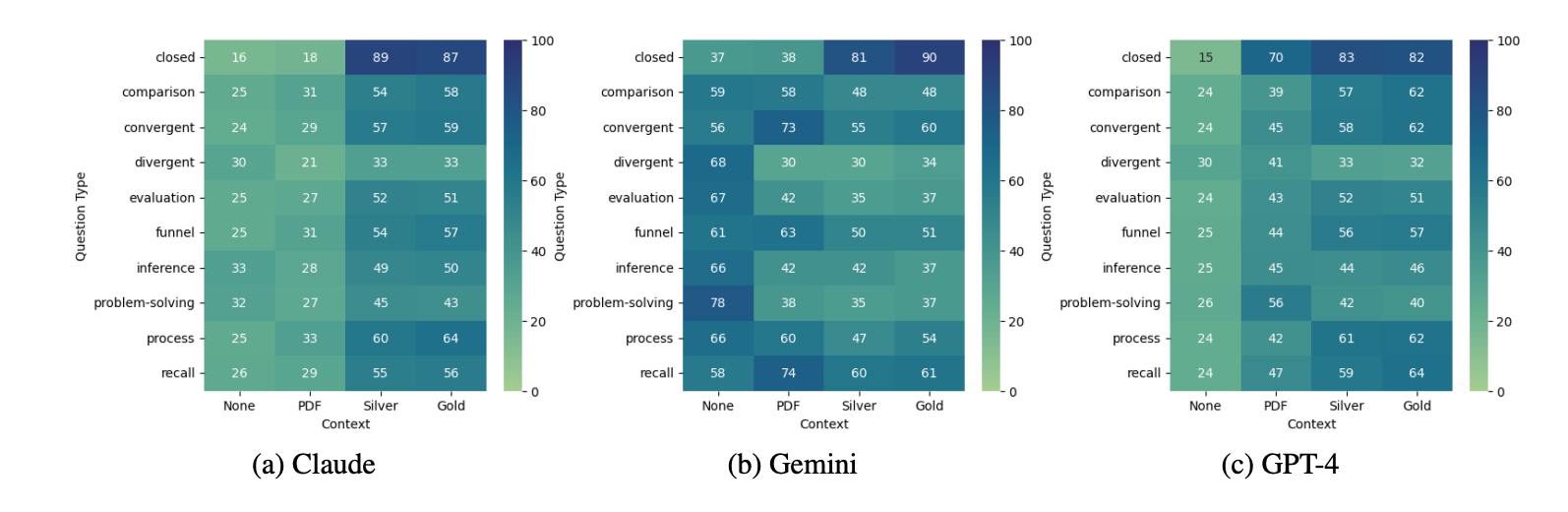
The findings indicate that models enhanced with the RAG technique perform better than those simply fed with the entire PDF content as a long context. This suggests that incorporating relevant knowledge retrieval can significantly boost the performance of LLMs on tasks involving complex document comprehension, like those required in the NEPA domain.
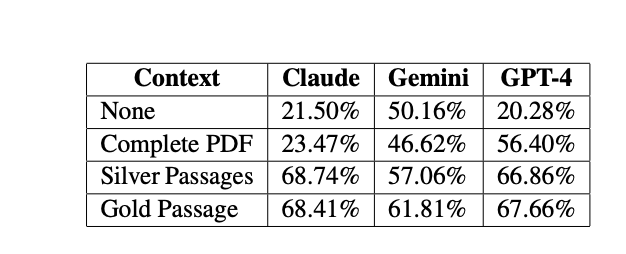
The study's analysis of LLM performance across various question types indicates that all models excel at closed questions when provided with silver (RAG context) or gold data as context. Notably, RAG models and those using other contextual data generally perform best on closed questions but struggle with divergent and problem-solving questions, highlighting the effectiveness of RAG in enhancing performance for specific question types.
Conclusion
Long-context LLMs handle extensive text well but are costly due to high computational demands. RAG models, which integrate external knowledge, particularly excel at closed questions and specific tasks like NEPA document comprehension. While long-context models generally outperform RAG on long-context understanding tasks, RAG remains crucial for certain applications. Thus, RAG will continue to play a significant role alongside long-context LLMs.By employing advanced query understanding and tailoring RAG techniques to specific datasets, its performance could be further enhanced, ensuring it remains a valuable tool in various applications.