Uber: Natural language to SQL
In today’s data-driven world, businesses increasingly rely on sophisticated querying systems to extract valuable insights. The complexity of writing SQL Queries can be a barrier, particularly for non-technical teams. Uber has revolutionized this process by leveraging GenAI to empower its teams to generate accurate SQL queries simply by asking through its QueryGPT system.
This blog will break down this particular Uber QueryGPT system. By examining the structure and functioning of the model in Uber’s internal operations, we will provide further details regarding the model’s role in the system's organizational data privacy, security, and continuous improvement.
What is QueryGPT?
QueryGPT is a fundamental level system developed in-house at Uber that aims to bridge the gap between non-technical, or better yet, any user’s natural language prompts aimed at interacting with the internal data models by creating relevant, in-context SQL queries. Using LLMs, vector databases, and similarity search to generate complex queries from English questions, the model significantly enhances productivity among teams.
This process involves breaking down the question's syntax and intent. It maps words in the question to relevant database terms and generates a query aligned with that intent. This eliminates the need for SQL expertise among Uber’s analysts and general staff.
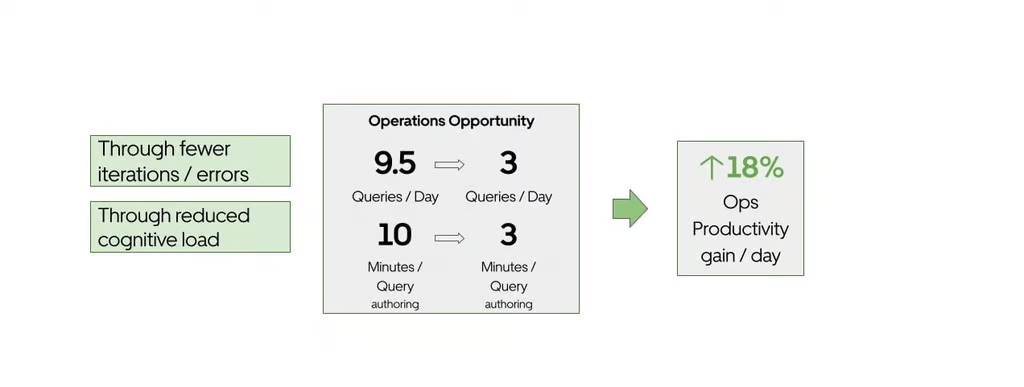
As they describe it, Uber's data platform processes around 1.2 million queries monthly, with the Operations team accounting for 36% of these. Creating a query requires significant time, often 10 minutes, as users search through datasets and write SQL. With the introduction of QueryGPT, this process has been streamlined. Queries can be generated in about 3 minutes, offering substantial productivity gains. The shift from manual to AI-assisted query creation saves time, allowing teams to focus on higher-value tasks.
Customizations presented by QueryGPT
QueryGPT was first discussed and introduced at Uber during the Generative AI Hackdays in May 2023. After countless iterations, it improved its ability to generate SQL queries from user prompts.
Initial proposal
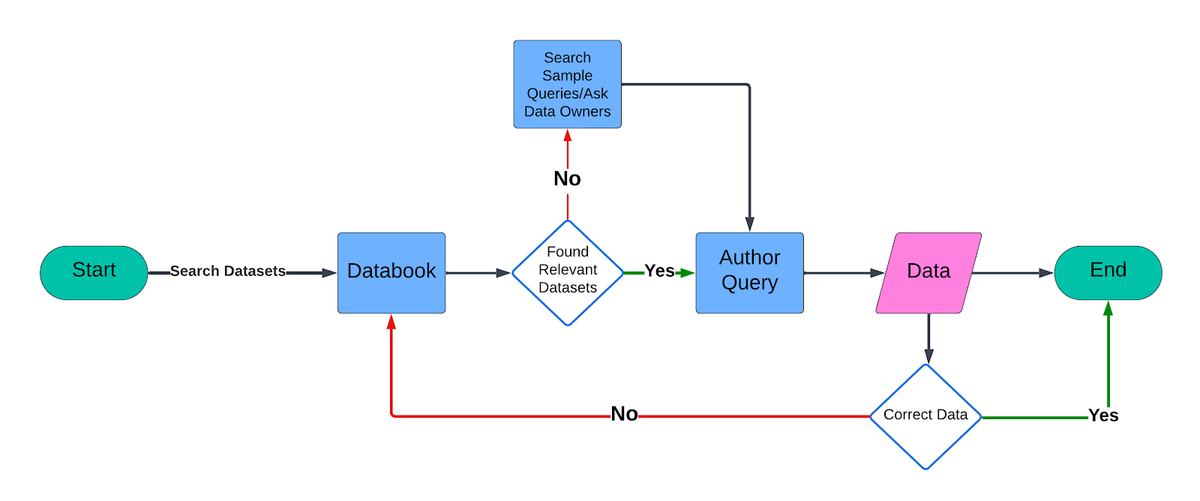
The initial version of QueryGPT was a relatively simple RAG model pipeline made to fetch relevant SQL queries. A natural language prompt was vectorized to search through a set of SQL samples and schema using k-nearest neighbor search. Once the closed schemas from the dataset were identified, an LLM was called to use it as an example and generate SQL queries by editing, omitting, or combining known schemas.
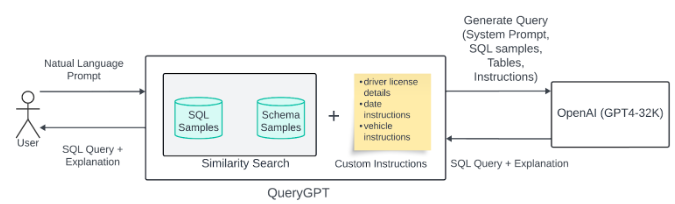
While the approach provided a reliable system for a small number of schema (20 to be exact), the model lacked scaling. As more tables and queries were added, the accuracy of generated queries became distant. Which resulted in shortcomings such as:
- Poor query relevance: A simple similarity search between user input and the schema didn’t always return relevant results, especially with more complex or specific queries.
- Understanding user intent: The model struggled to understand the specific intent behind user queries, making it hard to map them to the correct schema.
- Large schemas: Some schemas, especially Tier 1 tables, had over 200 columns, leading to token size problems. The largest available model at the time supported only 32K tokens, and using too many large schemas would break the LLM call.
These shortcomings further resulted in more work and iterations of the model, bringing us to the current version.
Current production
The in-production version of the system addresses limitations from the first iteration by providing several key improvements, most notably the introduction of Workspaces. Workspaces were introduced to improve query relevance. These are curated collections of SQL samples and tables specific to different business domains, such as:
- Mobility: Deals with data about trips, drivers, etc.
- Core Services, Ads, Platform Engineering, IT: Other business areas at Uber.
Each workspace focuses on a set of relevant schemas and SQL queries, narrowing the search for the LLM and improving the accuracy of the generated queries. Additionally, users can create Custom Workspaces for specialized needs not covered by existing workspaces. This introduction's critical relevance lies in the empowerment of more potent agents in the pipeline who handle several operations securely and with context.
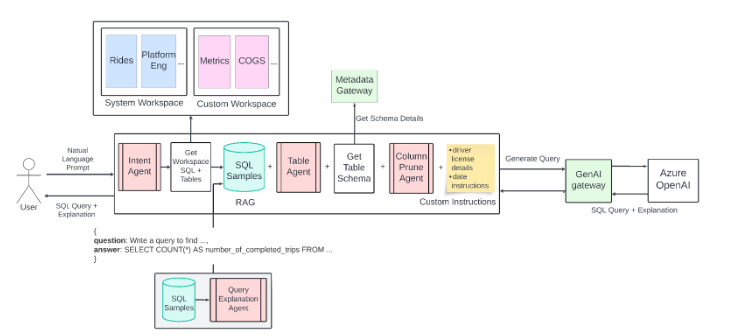
Intent agent
The Intent Agent was introduced. It classifies the user’s natural language prompt into a specific intent, mapping it to relevant workspaces (business domains). This allows the model to focus on a much narrower set of tables and SQL queries, improving efficiency and relevance.
For example:
A query like “Write a query to find the number of trips that were completed by Teslas in Seattle yesterday” would map to the Mobility workspace.
Table Agent
This agent suggests a list of tables for query generation based on the user’s input. The user can then acknowledge the tables or edit the list to select the correct ones. This feature became crucial given the feedback about incorrect table selection for query generation, which can pose a significant security risk.
Column prune Agent
Handling large schemas with many columns (up to 200+) leads to problems with token limits. Even with the GPT-4 Turbo model, which has a token limit of 128K, large schemas could still cause token overflow. To solve this, the Column Prune Agent was introduced. This agent prunes irrelevant columns from the schemas, reducing the token size. By only including the relevant columns in the LLM input, this agent helps:
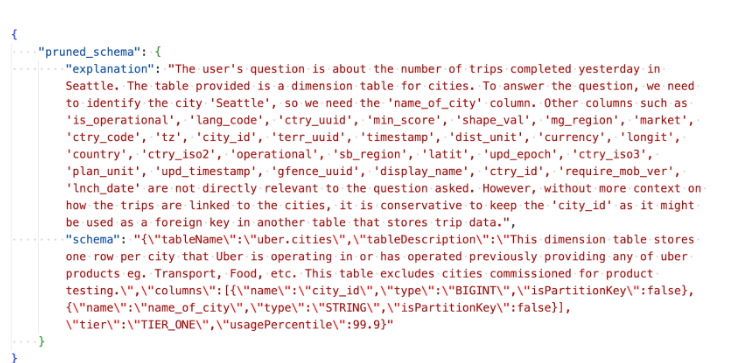
Pruning in action
- Reduce token size, avoiding token limit issues.
- Decrease the cost of LLM calls since fewer tokens are used.
- Lower latency by speeding up query generation, as the input size is smaller.
Experiments
To monitor QueryGPT's progress and ensure steady improvements, Uber implemented a standardized evaluation procedure. This approach allowed them to distinguish between regular performance gaps and uncommon issues, ensuring that algorithm changes contributed to consistent improvement.
The evaluation process began with curating a set of real user queries from QueryGPT logs. These queries were manually validated for intent, required schemas, and the corresponding SQL output. The evaluation covered a variety of business domains and datasets to capture diverse use cases.

A flexible evaluation framework was developed to capture performance in both production and staging environments. Two primary product flows were used:
- Vanilla Flow:
- Purpose: To measure QueryGPT's baseline performance.
- Procedure: The model infers intent and datasets, generates SQL, and evaluates the results for accuracy.
- Decoupled Flow:
- Purpose: To assess performance with a human-in-the-loop, isolating individual components.
- Procedure: The model uses predefined intent and datasets to generate SQL, and the results are assessed separately.
Metrics captured during the evaluation included:
- Intent: Accuracy of intent detection.
- Table Overlap: How well the selected tables matched the requirements.
- Successful Run: Whether the generated SQL executed without errors.
- Run Has Output: Whether the query returned results.
- Qualitative Query Similarity: A comparison between the generated SQL and the golden SQL using a similarity score.
These metrics helped identify patterns and monitor performance over time.
Are you interested in evaluating and monitoring your own GenAI pipeline? Check out Maxim’s GenAI Evaluation servings to see what fits your needs.
Key learnings to implement
Several key insights emerge from the Uber team's experiences with QueryGPT that organizations can implement. These learnings mainly reflect the boost in productivity the model offers compared to its accuracy, which is highly likely because of the non-deterministic nature of LLM outputs.
- LLMs as effective classifiers: Specialized agents like the Intent Agent and Table Agent performed well by focusing on narrow tasks, improving accuracy, and reducing complexity.
- Hallucinations: While efforts were made to reduce hallucinations (where the model generates incorrect tables or columns), this remains a challenge. Uber is experimenting with iterative refinement through chat mode and exploring a Validation Agent.
- Incomplete user prompts: Users often submit vague or incomplete queries. To address this, a Prompt Enhancer was introduced to help improve the context before sending the query to the model.
- High expectations for SQL output: Users expect highly accurate and functional SQL queries. Meeting this expectation required focusing on specific personas during testing and adapting the product to meet their needs.
These experiments and learnings have enhanced the model’s accuracy, usability, and performance.
Conclusion
The development of QueryGPT has been exponential for Uber’s internal operations, which should compel other companies to explore such avenues for possible integration of AI assistants and agents in their pipeline, leveraging the contextual understanding and retrieval ability of LLMs, which seamlessly integrates with various data banks efficiently.
Various other systems, such as GitHub CoPilot, WatsonX Code Assistant, and Amazon Q, have observed examples of such production boosts that compel the adoption of such systems in pipelines.
Further Reading
Open Source and In-House: How Uber Optimizes LLM Training
Genie: Uber’s Gen AI On-Call Copilot
Maxim is an evaluation platform for testing and evaluating LLM applications. Test your Gen AI application's performance with Maxim.