Best practices for implementing retrieval-augmented generation (RAG)

Introduction
In the five-part series "Understanding RAG," we began by explaining the foundational Retrieval-Augmented Generation (RAG ) framework and progressively explored advanced techniques to refine each component. In Part 1, we provided an overview of the RAG framework. Subsequent parts offered an in-depth analysis of the three main components: indexing, retrieval, and generation. In this final blog, we will discuss the findings from the research paper "Searching for Best Practices in Retrieval-Augmented Generation," in which the authors undertook a comprehensive study to identify and evaluate the most effective techniques for optimizing RAG systems. To provide a clear and comprehensive overview of the advanced RAG framework and its components, we include an illustrative image below. This visual representation encapsulates the various components and techniques designed to enhance the performance of the RAG system. We will discuss each component and the associated techniques that contribute to optimizing the system's overall performance.
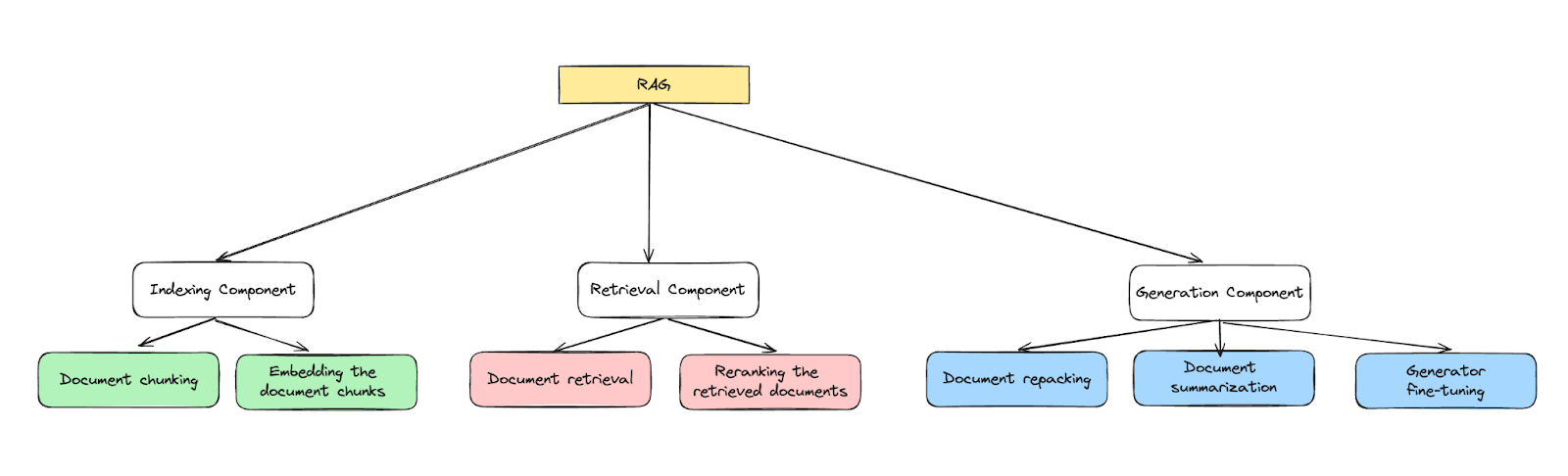
Indexing component
The indexing component consists of chunking documents and embedding these chunks to store the embeddings in a vector database. In earlier parts of the "Understanding RAG" series, we explored advanced chunking techniques, including sliding window chunking and small-to-big chunking, and highlighted the importance of selecting the optimal chunk size. Larger chunks offer more context but can increase processing time, while smaller chunks enhance recall but may provide insufficient context.
Equally important is the choice of an effective embedding model. Embeddings are crucial as they deliver compact, semantically meaningful representations of words and entities. The quality of these embeddings has a significant impact on the performance of retrieval and generation processes.
Recommendation for document chunking
In the paper "Searching for Best Practices in Retrieval-Augmented Generation," the authors evaluated various chunking techniques using zephyr-7b-alpha3 and gpt-3.5-turbo4 models for generation and evaluation. The chunk overlap was set to 20 tokens, and the first 60 pages of the document lyft_2021 were used as the corpus. Additionally, the authors prompted LLMs to generate approximately 170 queries based on the chosen corpus to use these as input queries.
The study suggests that chunk sizes of 256 and 512 tokens offer the best balance between providing sufficient context and maintaining high faithfulness and relevancy.
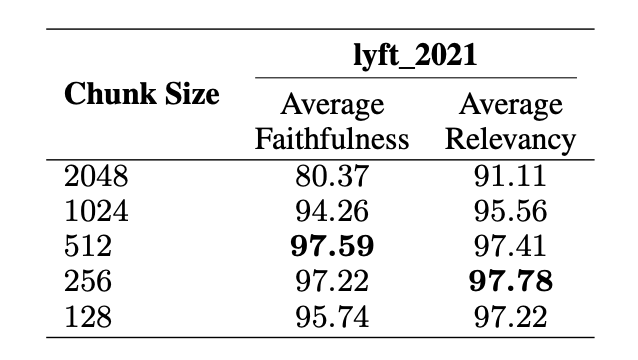
Larger chunks (2048 tokens): Offer more context but at the cost of slightly lower faithfulness. Smaller chunks (128 tokens): Improve retrieval recall but may lack sufficient context, leading to slightly lower faithfulness.
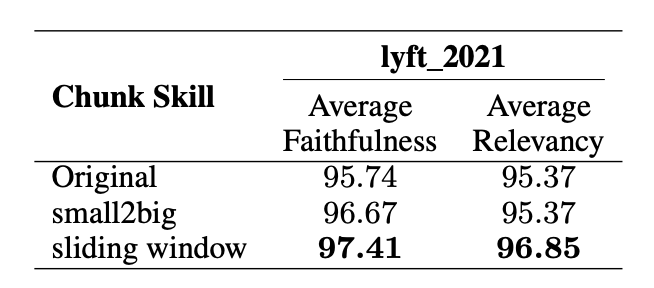
Additionally, it highlights that using advanced chunking techniques, such as sliding window chunking, further optimizes these benefits.
Recommendation for embedding model
Choosing the right embedding model is equally important for effective semantic matching of queries and chunk blocks. To select the appropriate open-source embedding model, the authors conducted another experiment using the evaluation module of FlagEmbedding, which uses the dataset namespace-Pt/msmarco7 for queries and the dataset namespace-Pt/msmarco-corpus8 for the corpus and metrics like RR and MRR were used for evaluation.
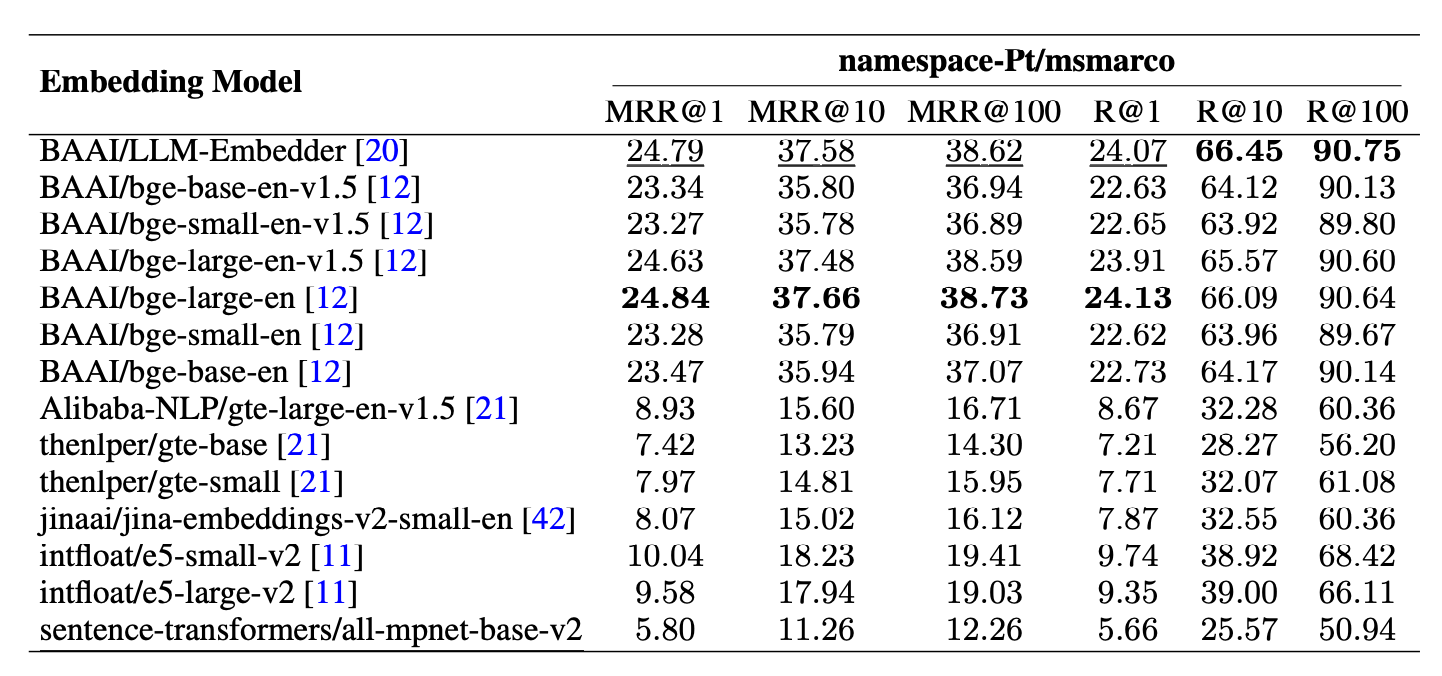
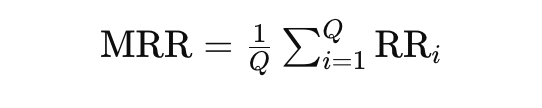
In the study, the authors selected LLM-Embedder as the embedding model due to its ability to deliver results comparable to the BAAI/bge-large-en model, while being three times smaller in size. This choice strikes a balance between performance and model size efficiency, making it a practical option. Following the discussion on embedding models, we will now turn our attention to the retrieval component. This segment will provide a brief overview of the retrieval process and present the recommendations made by the authors in the paper "Searching for Best Practices in Retrieval-Augmented Generation."
Retrieval component
The retrieval component of RAG can be further divided into two key stages. The first stage involves retrieving document chunks relevant to the query from the vector database. The second stage, reranking, focuses on further evaluating these retrieved documents to rank them based on their relevance, ultimately selecting only the most pertinent documents.
In the earlier parts of this blog series, we explored various retrieval methods, including Query2doc, HyDE (Hypothetical Document Embeddings), and TOC (TREE OF CLARIFICATIONS). Additionally, in Part four, we delved into reranking, talking about the different models that can be employed for this purpose.
In this section, we will present the findings from the research paper "Searching for Best Practices in Retrieval-Augmented Generation," which investigates the most effective retrieval methods and reranking models. We will also provide a brief overview of the experimental setup used in the study.
Recommendations for retrieval methods
The performance of various retrieval methods was evaluated on the TREC DL 2019 and 2020 passage ranking datasets.
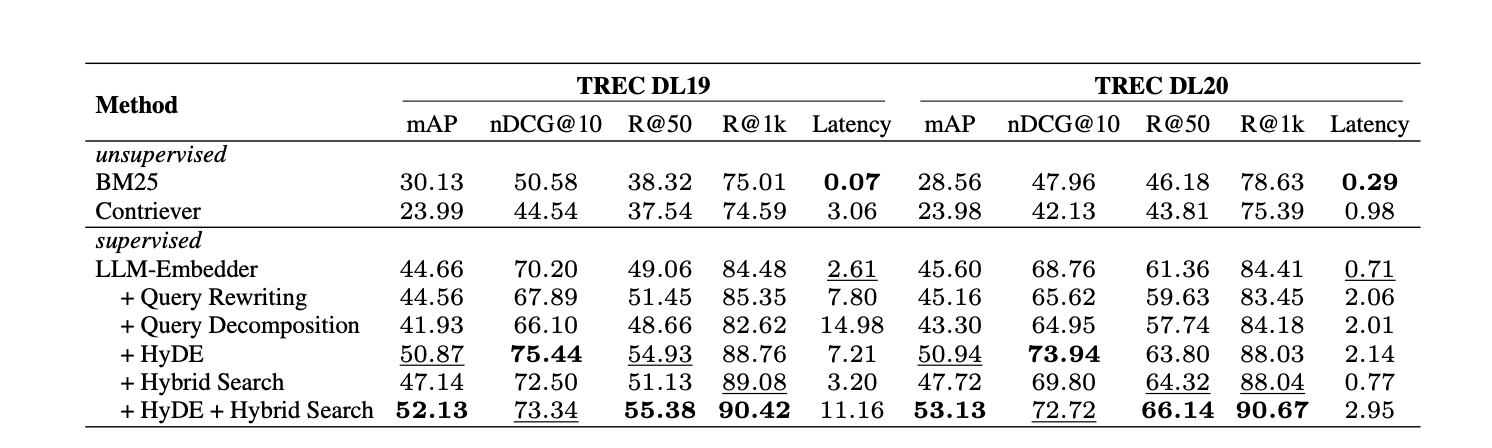
The performance of various retrieval methods was evaluated on the TREC DL 2019 and 2020 passage ranking datasets. The results indicate that the combination of Hybrid Search with HyDE and the LLM-Embedder achieved the highest scores. This approach combines sparse retrieval (BM25) and dense retrieval (original embedding), delivering notable performance with relatively low latency while maintaining efficiency.
Recommendations for reranking models
Similar experiments were conducted on the MS MARCO Passage ranking dataset to evaluate several bi-encoder and cross-encoder reranking models, such as monoT5, monoBERT, RankLLaMA, and TILDEv2.
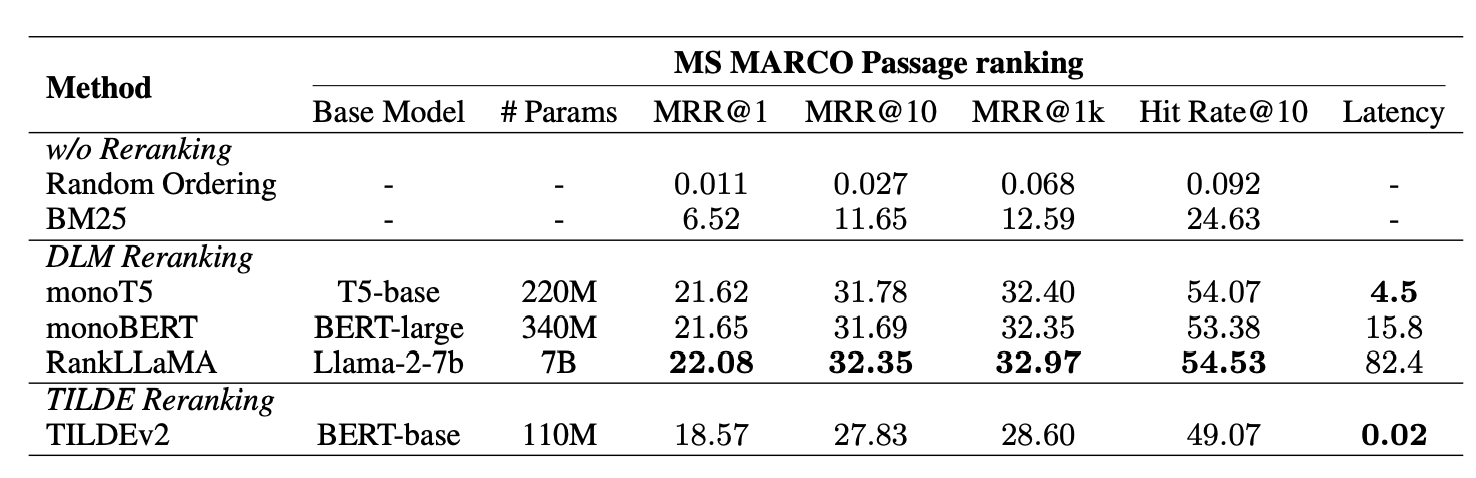
The findings in the paper "Searching for Best Practices in Retrieval-Augmented Generation" recommend monoT5 as a well-rounded method that balances performance and efficiency. For those seeking the best possible performance, RankLLaMA is the preferred choice, whereas TILDEv2 is recommended for its speed when working with a fixed collection.
Generation component
After the indexing and retrieval component comes the generation component in RAG systems. In this component, the documents retrieved from the reranking stage are further summarised and ordered (based on the relevancy score to the query) to provide them as input to the fine-tuned LLM model for the final answer generation.
Techniques like document repacking, document summarisation, and generator model fine-tuning are used to enhance the generation component. In Part Four of the "Understanding Rag" blog series, we have discussed all the methods in detail. In this section, we will discuss the findings from the paper "Searching for Best Practices in Retrieval-Augmented Generation," where the authors tried to evaluate each process and find the most efficient approach.
Recommendation for document repacking
Document repacking, discussed in detail in part Four of the "Understanding RAG" series, is a vital technique in the RAG workflow that enhances response generation. After reranking the top K documents by relevancy scores, this technique optimizes their order for the language model (LLM), ensuring more accurate and relevant responses. The three primary repacking methods include the forward method, which arranges documents in descending relevancy; the reverse method, which arranges them in ascending relevancy; and the sides method, which places the most relevant documents at both the beginning and end of the sequence.

In the research paper "Searching for Best Practices in Retrieval-Augmented Generation," various repacking techniques were evaluated across several datasets, including Commonsense Reasoning, fact-checking, Open-Domain QA, MultiHop QA, and Medical QA. The study identified the "reverse" method as the most effective repacking approach based on metrics such as accuracy (Acc), exact match (EM), and RAG scores across all tasks. The evaluation also included an assessment of average latency, measured in seconds per query, to determine efficiency.
Recommendation for document summarization
Summarization in RAG aims to improve response relevance and efficiency by condensing retrieved documents and reducing redundancy before inputting them into the LLM. In Part Four of the "Understanding RAG" series, we covered various summarization techniques, including RECOMP and LongLLMLingua. This section will focus on identifying the most efficient technique based on the paper "Searching for Best Practices in Retrieval-Augmented Generation."
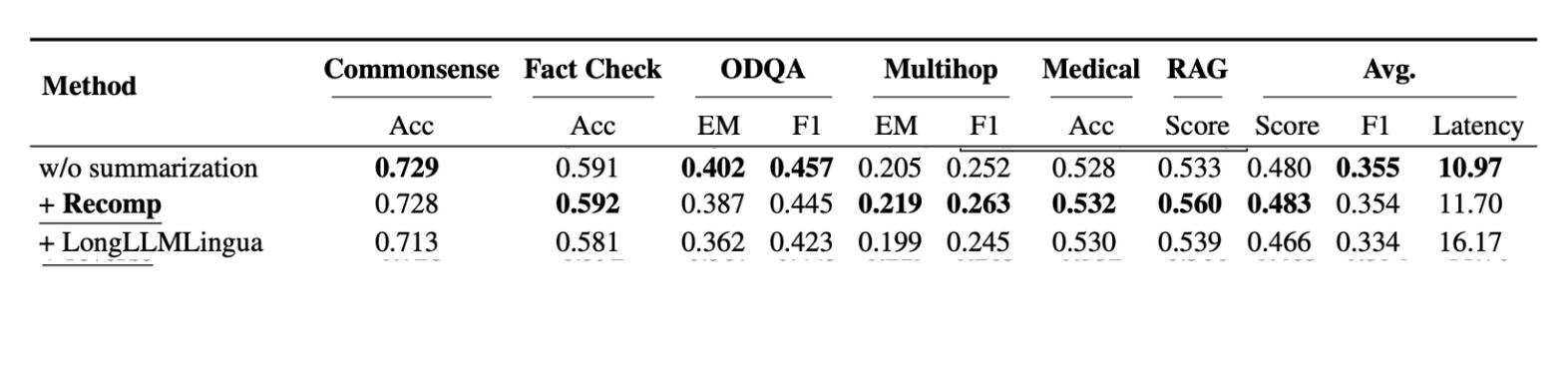
The paper "Searching for Best Practices in Retrieval-Augmented Generation" evaluated various summarization methods across three benchmark datasets: NQ, TriviaQA, and HotpotQA. RECOMP emerged as the superior technique, demonstrating exceptional performance across metrics such as accuracy (Acc) and exact match (EM). The “Avg” (average score) reflects the mean performance across all tasks, while average latency is recorded in seconds per query. The best scores are highlighted in bold.
Recommendation for generator fine-tuning
The paper "Searching for Best Practices in Retrieval-Augmented Generation" investigates how fine-tuning affects the generator, particularly with relevant versus irrelevant contexts. The study employed different context compositions for training, including pairs of query-relevant documents (Dg), combinations of relevant and randomly sampled documents (Dgr), combinations of only randomly sampled documents (Dr), and contexts with two copies of a relevant document (Dgg). In this study, Llama-2-7b was selected as the base model. The base LM generator without fine-tuning is referred to as M_b, and the model fine-tuned with different contexts is referred to as M_g, M_r, M_gr, and M_gg . The models were fine-tuned using several QA and reading comprehension datasets, including ASQA, HotpotQA, NarrativeQA, NQ, SQuAD, TriviaQA, and TruthfulQA.
Following the training process, all trained models were evaluated on validation sets with D_g, D_r, D_gr, and D_∅, where D_∅ indicates inference without retrieval.
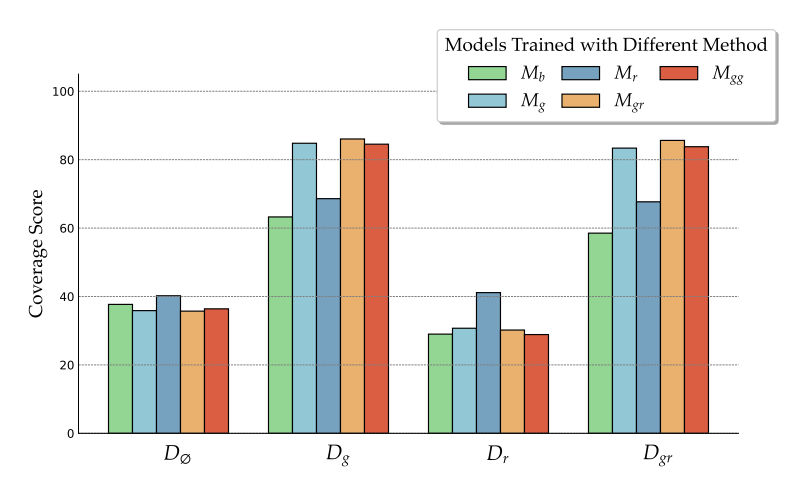
The results demonstrate that models trained with a mix of relevant and random documents (M_gr) perform best when provided with either gold or mixed contexts. This finding suggests that incorporating both relevant and random contexts during training can enhance the generator's robustness to irrelevant information while ensuring effective utilization of relevant contexts.
Conclusion
In the final installment of the "Understanding RAG" series, we reviewed key findings from "Searching for Best Practices in Retrieval-Augmented Generation." While the study suggests effective strategies like chunk sizes of 256 and 512 tokens, LLM-Embedder for embedding, and specific reranking and generation methods, it's clear that the best approach depends on your specific use case. The right combination of techniques—retrieval methods, embedding strategies, or summarization techniques—should be tailored to meet your application's unique needs and goals, and you should run robust evaluations to figure out what works best for you.
Maxim is an evaluation platform for testing and evaluating LLM applications. Test your RAG performance with Maxim.