What is RAG? A comprehensive guide to retrieval-augmented generation in AI

What is a RAG?
Retrieval-augmented generation (RAG) is a process designed to enhance the output of a large language model (LLM) by incorporating information from an external, authoritative knowledge base. This approach ensures that the responses generated by the LLM are not solely dependent on the model's training data. Large Language Models are trained on extensive datasets and utilize billions of parameters to perform tasks such as answering questions, translating languages, and completing sentences. By using RAG, these models can tap into specific domains or an organization's internal knowledge base without needing to be retrained. This method is cost-effective and helps maintain the relevance, accuracy, and utility of the LLM's output in various contexts.
Why is Retrieval-Augmented Generation important?
Large language models (LLMs) are a critical component of artificial intelligence (AI) technologies, especially for intelligent chatbots and other natural language processing (NLP) applications. The primary goal is to create chatbots that can accurately answer user questions by referencing reliable knowledge sources. However, there are inherent challenges with LLM technology:
- Hallucinations: LLMs can present incorrect information if they do not have the right answer.
- Out-of-date responses: The static nature of LLM training data means the model might provide outdated or overly generic information instead of specific, current responses.
- Non-authoritative sources: Responses may be generated from unreliable sources.
- Terminology confusion: Different sources might use the same terms to refer to different things, leading to inaccurate responses.
RAG addresses these challenges by directing the LLM to retrieve relevant information from authoritative, pre-determined knowledge sources. This approach provides several benefits:
- Control over output: Organizations can better control the text generated by the LLM.
- Accurate responses: Users receive more accurate and relevant information.
- Transparency: Users gain insights into the sources used by the LLM to generate responses.
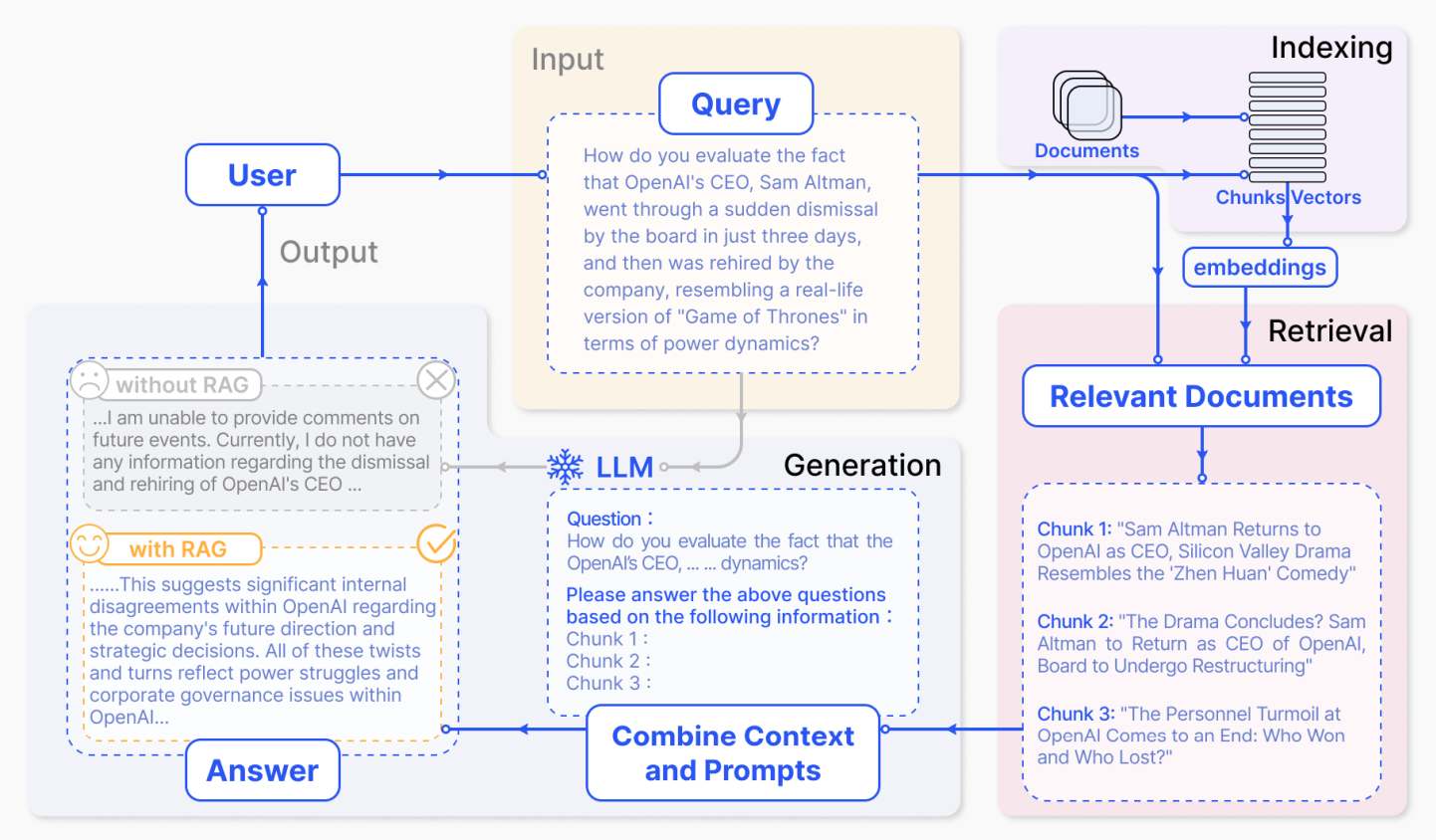
How Does Retrieval-Augmented Generation (RAG) work?
A basic Retrieval-Augmented Generation (RAG) framework comprises three main components: indexing, retrieval, and generation. This framework operates by first indexing data into vector representations. Upon receiving a user query, it retrieves the most relevant chunks of information based on their similarity to the query. Finally, these retrieved chunks are used to generate a well-informed response. This process ensures that the model's output is accurate, relevant, and contextually appropriate.
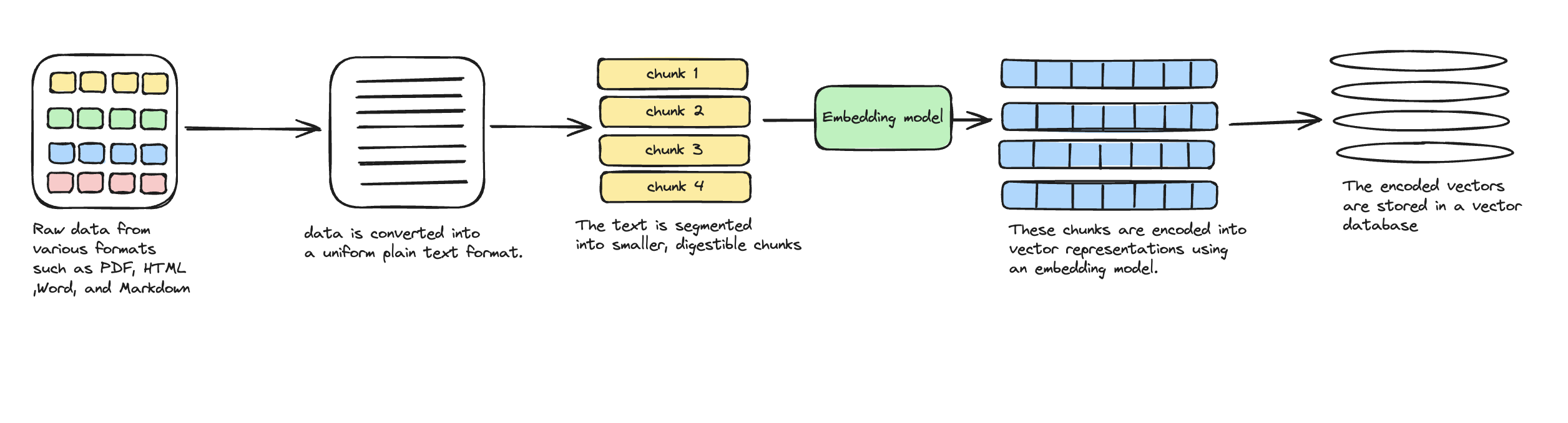
1. Indexing
Indexing is the initial phase where raw data is prepared and stored for retrieval:
- Data cleaning and extraction: Raw data from various formats such as PDF, HTML, Word, and Markdown is cleaned and extracted.
- Conversion to plain text: This data is converted into a uniform plain text format.
- Text segmentation: The text is segmented into smaller, digestible chunks to accommodate the context limitations of language models.
- Vector encoding: These chunks are encoded into vector representations using an embedding model.
- Storage in vector database: The encoded vectors are stored in a vector database, which is crucial for enabling efficient similarity searches in the retrieval phase.
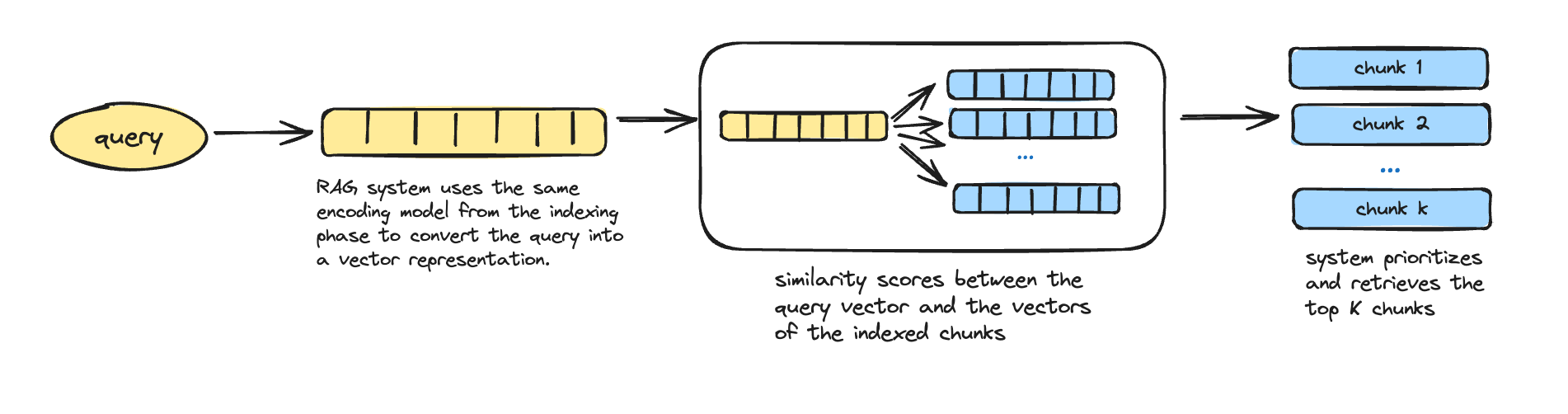
2. Retrieval
Retrieval is the phase where relevant data is fetched based on a user query:
- Query encoding: Upon receiving a user query, the RAG system uses the same encoding model from the indexing phase to convert the query into a vector representation.
- Similarity calculation: The system computes similarity scores between the query vector and the vectors of the indexed chunks.
- Chunk retrieval: The system prioritizes and retrieves the top K chunks that have the highest similarity scores to the query.
- Expanded context creation: These retrieved chunks are used to expand the context of the prompt that will be given to the language model.
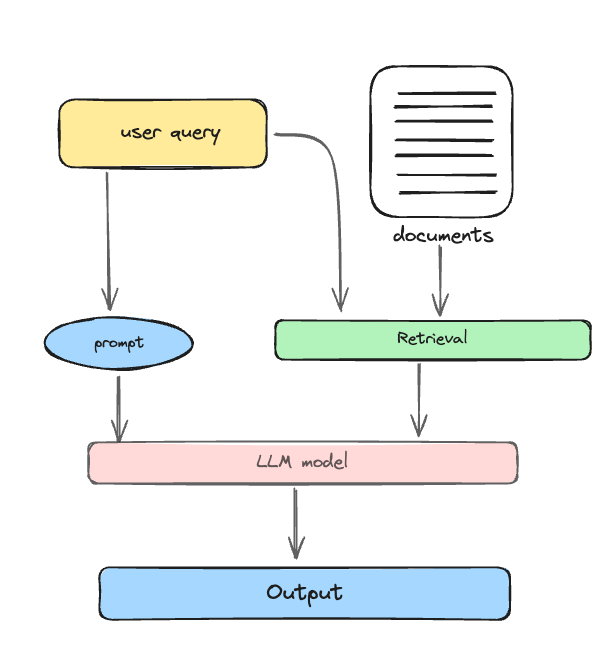
3. Generation
Generation is the final phase, where the response is created based on the retrieved information:
- Prompt synthesis: The user query and the selected documents (retrieved chunks) are synthesized into a coherent prompt.
- Response formulation: A large language model is tasked with formulating a response to the synthesized prompt.
- Task-specific criteria: The model may draw upon its inherent parametric knowledge or limit its response to the information within the provided documents, depending on the task-specific criteria.
- Multi-turn dialogue: For ongoing dialogues, the existing conversational history can be integrated into the prompt, enabling the model to engage in effective multi-turn interactions.

Drawbacks of basic Retrieval-Augmented Generation
Basic RAG faces challenges in retrieval precision, recall, and generating accurate, relevant responses. It struggles with integrating retrieved information coherently, often resulting in disjointed, redundant, or repetitive outputs. Additionally, determining the significance and maintaining consistency in the responses add to the complexity. The single retrieval approach often falls short, and there is a risk of over-reliance on the augmented data, leading to uninspired outputs.
Retrieval challenges
The retrieval phase in Basic RAG often struggles with the following:
- Precision and Recall: It frequently selects chunks of information that are misaligned with the query or irrelevant, and it can miss crucial information needed for a comprehensive response.
Generation difficulties
In the generation phase, Basic RAG can encounter:
- Hallucination: The model might produce content not supported by the retrieved context, creating fabricated or inaccurate information.
- Irrelevance, Toxicity, and Bias: The outputs can sometimes be off-topic, offensive, or biased, negatively impacting the quality and reliability of the responses.
Augmentation hurdles
When integrating retrieved information into responses, Baisc RAG faces:
- Disjointed or incoherent outputs: Combining the retrieved data with the task at hand can result in responses that lack coherence or flow.
- Redundancy: Similar information retrieved from multiple sources can lead to repetitive content in the responses.
- Significance and relevance: Determining the importance and relevance of different passages is challenging, as is maintaining stylistic and tonal consistency in the final output.
Complexity of information acquisition
- Single retrieval limitation: A single retrieval based on the original query often fails to provide enough context, necessitating more complex retrieval strategies.
- Over-reliance on augmented information: Generation models might depend too heavily on the retrieved content, leading to responses that merely echo this information without offering additional insight or synthesis.
Advanced Retrieval-Augmented Generation (RAG)
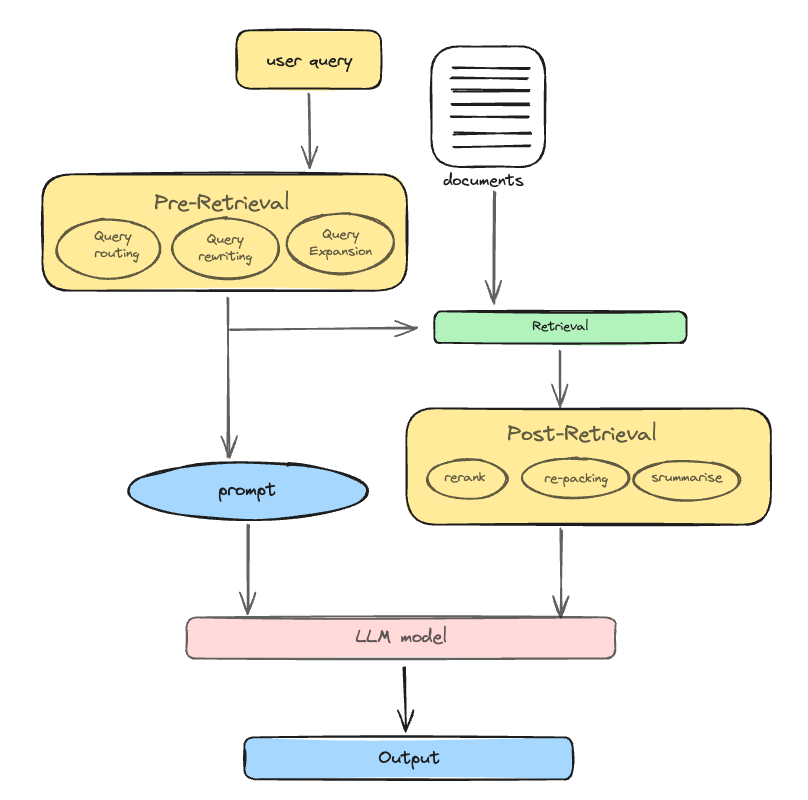
Advanced RAG builds on the basic RAG framework by addressing its limitations and enhancing retrieval quality through pre-retrieval and post-retrieval strategies. Here’s a detailed explanation:
1. Pre-retrieval process:
The pre-retrieval process aims to optimize both the indexing structure and the original query to ensure high-quality content retrieval.
Optimizing indexing:
- Enhancing data granularity: Breaking down data into smaller, more precise chunks to improve indexing accuracy.
- Optimizing index structures: Improving the structure of indexes to facilitate efficient and accurate retrieval.
- Adding metadata: Incorporating additional information like timestamps, authorship, and categorization to enhance context and relevance.
- Alignment optimization: Aligning data chunks to maintain context and continuity across segments.
- Mixed retrieval: Combining various retrieval techniques to improve overall search results.
Query optimization:
- Query rewriting: Rephrasing the user's original question to improve clarity and accuracy in retrieval.
- Query transformation: Altering the structure of the query to better match the indexed data.
- Query expansion: Adding related terms or synonyms to the query to capture a broader range of relevant results.
2. Post-retrieval process:
After retrieving relevant context, the post-retrieval process focuses on effectively integrating it with the query to generate accurate and focused responses.
Re-ranking chunks:
- Re-ranking: Prioritizing the retrieved information by relocating the most relevant content to the edges of the prompt. This method is implemented in frameworks like LlamaIndex, LangChain, and HayStack.
Context compressing:
- Mitigating information overload: Directly feeding all relevant documents into LLMs can lead to information overload, where key details are diluted by irrelevant content.
- Selecting essential information: Focusing on the most crucial parts of the retrieved content.
- Emphasizing critical sections: Highlighting the most important sections of the context.
- Shortening the context: Reducing the amount of information to be processed by the LLM to maintain focus on key details.
Conclusion
Retrieval-augmented generation (RAG) significantly improves the accuracy and relevance of responses from large language models (LLMs) by incorporating external, authoritative knowledge sources. It addresses common LLM challenges like misinformation and outdated data, enhancing control, transparency, and reliability in content generation. While basic RAG faces retrieval precision and response coherence issues with retrieval precision and response coherence, advanced strategies refine indexing, optimize queries, and integrate information more effectively. Ongoing advancements in RAG are crucial for enhancing AI-generated responses, building trust, and improving natural language processing interactions.
Maxim is an evaluation platform for testing and evaluating LLM applications. Test your RAG performance with Maxim before adding advanced RAG features.