 ***
For more details, see the [Agno documentation](https://github.com/agno-agi/agno) and the
[Maxim Python SDK documentation](https://www.getmaxim.ai/docs/introduction/overview).
## Resources
***
For more details, see the [Agno documentation](https://github.com/agno-agi/agno) and the
[Maxim Python SDK documentation](https://www.getmaxim.ai/docs/introduction/overview).
## Resources
 ***
For more details, see the [Anthropic Python SDK documentation](https://docs.anthropic.com/en/home) and the [Maxim Python SDK documentation](https://www.getmaxim.ai/docs/introduction/overview).
## Resources
***
For more details, see the [Anthropic Python SDK documentation](https://docs.anthropic.com/en/home) and the [Maxim Python SDK documentation](https://www.getmaxim.ai/docs/introduction/overview).
## Resources
 ***
For more details, see the [CrewAI documentation](https://docs.crewai.com/) and the [Maxim Python SDK documentation](https://getmaxim.ai/docs).
## Resources
***
For more details, see the [CrewAI documentation](https://docs.crewai.com/) and the [Maxim Python SDK documentation](https://getmaxim.ai/docs).
## Resources
 ***
For more details, see the [Maxim Python SDK documentation](https://www.getmaxim.ai/docs/sdk/python/integrations/gemini/gemini).
## Resources
***
For more details, see the [Maxim Python SDK documentation](https://www.getmaxim.ai/docs/sdk/python/integrations/gemini/gemini).
## Resources
 LLM Response for Tesla's stock price:
```text
Based on the historical price data, Tesla's stock price has been quite volatile over the last 3 months. The stock price has fluctuated between a high of $362.89 and a low of $275.35.
The stock started the 3-month period at around $282.16 and initially declined to $275.35. Then it started to rise, reaching a peak of $362.89. However, the stock price has been declining since then and is currently trading at around $325.59.
The overall trend of the stock price over the last 3 months is slightly positive, with the stock gaining about 15%. However, the stock's volatility and recent decline suggest that investors should exercise caution and keep a close eye on the stock's performance.
It's also important to consider other factors such as the company's financial health, industry trends, and overall market conditions when making investment decisions.
```
LLM Response for Tesla's stock price:
```text
Based on the historical price data, Tesla's stock price has been quite volatile over the last 3 months. The stock price has fluctuated between a high of $362.89 and a low of $275.35.
The stock started the 3-month period at around $282.16 and initially declined to $275.35. Then it started to rise, reaching a peak of $362.89. However, the stock price has been declining since then and is currently trading at around $325.59.
The overall trend of the stock price over the last 3 months is slightly positive, with the stock gaining about 15%. However, the stock's volatility and recent decline suggest that investors should exercise caution and keep a close eye on the stock's performance.
It's also important to consider other factors such as the company's financial health, industry trends, and overall market conditions when making investment decisions.
```
 Stock Comparison Plot:
Stock Comparison Plot:
 ## Maxim Observability
## Maxim Observability
 ## Conclusion
We've built a powerful, AI-driven stock market analysis tool that demonstrates the incredible potential of combining fast LLM inference with function calling. The system understands natural language, fetches real-time data, creates beautiful visualizations, and provides intelligent analysis - all from simple English queries.
## Resources
## Conclusion
We've built a powerful, AI-driven stock market analysis tool that demonstrates the incredible potential of combining fast LLM inference with function calling. The system understands natural language, fetches real-time data, creates beautiful visualizations, and provides intelligent analysis - all from simple English queries.
## Resources
{messages.map((m) => (
);
}
```
## 11. Visualize in Maxim
All requests, responses, and streaming events are automatically traced and can be viewed in your
[Maxim dashboard](https://app.getmaxim.ai/).
{m.role}: {m.content}
))}
 ***
For more details, see the
[Maxim JS SDK documentation](https://www.npmjs.com/package/@maximai/maxim-js) and the
[Vercel AI SDK documentation](https://sdk.vercel.ai/docs).
# Reuse Parts of Prompts using Maxim Prompt Partials
Source: https://www.getmaxim.ai/docs/cookbooks/platform-features/prompt-partials
This cookbook demonstrates how to use Maxim's Prompt Partials feature to create reusable prompt components that maintain consistency across multiple prompts and reduce repetition.
export const MaximPlayer = ({url}) => {
return ;
};
Prompt Partials are reusable snippets of prompt content that can be included across different prompts. They help you:
* **Maintain Consistency**: Ensure uniform tone and style across all your AI agents
* **Reduce Repetition**: Write common prompt elements once and reuse everywhere
* **Centralized Management**: Update shared content in one place and apply changes globally
***
For more details, see the
[Maxim JS SDK documentation](https://www.npmjs.com/package/@maximai/maxim-js) and the
[Vercel AI SDK documentation](https://sdk.vercel.ai/docs).
# Reuse Parts of Prompts using Maxim Prompt Partials
Source: https://www.getmaxim.ai/docs/cookbooks/platform-features/prompt-partials
This cookbook demonstrates how to use Maxim's Prompt Partials feature to create reusable prompt components that maintain consistency across multiple prompts and reduce repetition.
export const MaximPlayer = ({url}) => {
return ;
};
Prompt Partials are reusable snippets of prompt content that can be included across different prompts. They help you:
* **Maintain Consistency**: Ensure uniform tone and style across all your AI agents
* **Reduce Repetition**: Write common prompt elements once and reuse everywhere
* **Centralized Management**: Update shared content in one place and apply changes globally
 ### Define the Partial Content
**Example: Tone and Response Structure Partial**
```
Name: tone-and-structure
Title: Tone and Response Structure Guidelines
Content:
Tone Guidelines:
Use warm and approachable language. Avoid sounding robotic or overly formal.
Keep messages concise but complete - no walls of text.
Response Structure:
- Start with a friendly acknowledgment (e.g., "Sure, happy to help!")
- Give the core information clearly in short sentences or bullet points
- End with an offer for further assistance if appropriate
```
### Publish the Partial
1. Click **Publish Version**
2. Add a description: "Prompt partial for tone and response structure"
3. Click **Create Version**
Your prompt partial is now ready to use across multiple prompts!
### Define the Partial Content
**Example: Tone and Response Structure Partial**
```
Name: tone-and-structure
Title: Tone and Response Structure Guidelines
Content:
Tone Guidelines:
Use warm and approachable language. Avoid sounding robotic or overly formal.
Keep messages concise but complete - no walls of text.
Response Structure:
- Start with a friendly acknowledgment (e.g., "Sure, happy to help!")
- Give the core information clearly in short sentences or bullet points
- End with an offer for further assistance if appropriate
```
### Publish the Partial
1. Click **Publish Version**
2. Add a description: "Prompt partial for tone and response structure"
3. Click **Create Version**
Your prompt partial is now ready to use across multiple prompts!
 ## Step 3: Using Prompt Partials in Your Prompts
### Basic Syntax
To include a prompt partial in your prompt, use the following syntax:
```
{{partials.partial-name.version}}
```
### Version Options
```
{{partials.tone-and-structure.v1}} # Use specific version 1
{{partials.tone-and-structure.v2}} # Use specific version 2
{{partials.tone-and-structure.latest}} # Always use latest published version
```
### Implementation Example
**HR Agent Prompt (After Using Partials):**
```
You are an HR assistant helping employees with workplace questions and policies.
{{partials.tone-and-structure.latest}}
Specific HR Guidelines:
- Always refer to company policies when answering policy questions
- For sensitive matters, suggest speaking with HR directly
- Maintain confidentiality in all interactions
- Provide accurate information about benefits and procedures
[Rest of HR-specific instructions...]
```
**Customer Support Agent Prompt (After Using Partials):**
```
You are a customer support agent for a medical shop, helping customers with their inquiries.
{{partials.tone-and-structure.latest}}
Specific Customer Support Guidelines:
- Always verify customer identity for account-related queries
- Provide clear information about products and services
- Escalate complex medical questions to qualified staff
- Follow up to ensure customer satisfaction
[Rest of customer support-specific instructions...]
```
## Step 4: Advanced Prompt Partial Patterns
### Multiple Partials in One Prompt
```
You are a financial advisor chatbot.
{{partials.tone-and-structure.latest}}
{{partials.compliance-guidelines.latest}}
{{partials.financial-disclaimers.latest}}
[Specific financial advisor instructions...]
```
## Step 5: Managing Partial Versions
### Version Control Best Practices
```
Version Strategy:
v1.0 - Initial release
v1.1 - Minor updates (typos, small improvements)
v2.0 - Major changes (structural modifications)
```
Prompt Partials are a powerful feature for maintaining consistency and reducing duplication across your AI agents.
# Creating Custom Evaluators in Maxim via SDK
Source: https://www.getmaxim.ai/docs/cookbooks/sdk/sdk_custom_evaluator
This cookbook demonstrates how to create custom evaluators for Maxim test runs using the Python SDK. You'll learn to build AI-powered evaluators, programmatic evaluators, and integrate them with hosted datasets to comprehensively evaluate your prompts and agents from your coding environment.
## Prerequisites
Before getting started, ensure you have:
* A Maxim account with API access
* Python environment (Google Colab or local setup)
* A published and deployed prompt in Maxim
* A hosted dataset in your Maxim workspace
* Custom evaluator prompts (for AI evaluators) published and deployed in Maxim
## Setting Up Environment
### 1. Install Maxim Python SDK
```python
pip install maxim-py
```
### 2. Import Required Modules
```python
from typing import Dict, Optional
from maxim import Maxim
import json
from maxim.evaluators import BaseEvaluator
from maxim.models import (
LocalEvaluatorResultParameter,
LocalEvaluatorReturn,
ManualData,
PassFailCriteria,
QueryBuilder
)
from maxim.models.evaluator import (
PassFailCriteriaForTestrunOverall,
PassFailCriteriaOnEachEntry,
)
```
### 3. Configure API Keys and IDs
```python
# For Google Colab users
from google.colab import userdata
API_KEY: str = userdata.get("MAXIM_API_KEY") or ""
WORKSPACE_ID: str = userdata.get("MAXIM_WORKSPACE_ID") or ""
DATASET_ID: str = userdata.get("DATASET_ID") or ""
PROMPT_ID: str = userdata.get("PROMPT_ID") or ""
# For VS Code users, use environment variables:
# import os
# API_KEY = os.getenv("MAXIM_API_KEY")
# WORKSPACE_ID = os.getenv("MAXIM_WORKSPACE_ID")
# DATASET_ID = os.getenv("DATASET_ID")
# PROMPT_ID = os.getenv("PROMPT_ID")
```
**Getting Your Keys:**
* **API Key**: Maxim Settings → API Keys → Create new API key
* **Workspace ID**: Click workspace dropdown → Copy workspace ID
* **Dataset ID**: Go to Datasets → Select dataset → Copy ID from hamburger menu
* **Prompt ID**: Go to Single Prompts → Select prompt → Copy prompt version ID
### 4. Initialize Maxim
```python
maxim = Maxim({
"api_key": API_KEY,
"prompt_management": True # Required for fetching evaluator prompts
})
```
## Step 1: Create AI-Powered Custom Evaluators
### Quality Evaluator
This evaluator uses an AI prompt to score response quality on a scale of 1-5:
```python
class AIQualityEvaluator(BaseEvaluator):
"""
Evaluates response quality using AI judgment.
Scores between 1-5 based on how well the response answers the prompt.
"""
def evaluate(self, result: LocalEvaluatorResultParameter, data: ManualData) -> Dict[str, LocalEvaluatorReturn]:
# Extract input prompt and model output
prompt = data["Input"]
response = result.output
# Get the quality evaluator prompt from Maxim
prompt_quality = self._get_quality_evaluator_prompt()
# Run evaluation
evaluation_response = prompt_quality.run(
f"prompt: {prompt} \n output: {response}"
)
print(f"Quality evaluation response: {evaluation_response}")
# Parse JSON response
content = json.loads(evaluation_response.choices[0].message.content)
return {
"qualityScore": LocalEvaluatorReturn(
score=content['score'],
reasoning=content['reasoning']
)
}
def _get_quality_evaluator_prompt(self):
"""Fetch the quality evaluator prompt from Maxim"""
print("Getting your quality evaluator prompt...")
# Define deployment rules (must match your deployed prompt)
env = "prod"
tenantId = 222
rule = (QueryBuilder()
.and_()
.deployment_var("env", env)
.deployment_var("tenant", tenantId)
.build())
# Replace with your actual quality evaluator prompt ID
return maxim.get_prompt("your_quality_evaluator_prompt_id", rule)
```
**Quality Evaluator Prompt Example:**
Your quality evaluator prompt should return JSON in this format:
```json
{
"score": 4,
"reasoning": "The response is concise and accurate, capturing key details from the input."
}
```
### Safety Evaluator
This evaluator checks if responses contain unsafe content:
```python
class AISafetyEvaluator(BaseEvaluator):
"""
Evaluates if the response contains any unsafe content.
Returns True if safe, False if unsafe.
"""
def evaluate(self, result: LocalEvaluatorResultParameter, data: ManualData) -> Dict[str, LocalEvaluatorReturn]:
response = result.output
# Get safety evaluator prompt
prompt_safety = self._get_safety_evaluator_prompt()
# Run safety evaluation
evaluation_response = prompt_safety.run(response)
print("Safety Evaluation Response:")
print(evaluation_response)
# Parse response
content = json.loads(evaluation_response.choices[0].message.content)
# Convert numeric safety score to boolean
safe = content['safe'] == 1
return {
"safetyCheck": LocalEvaluatorReturn(
score=safe,
reasoning=content['reasoning']
)
}
def _get_safety_evaluator_prompt(self):
"""Fetch the safety evaluator prompt from Maxim"""
print("Getting your safety evaluator prompt...")
# Define deployment rules
env = "prod-2"
tenantId = 111
rule = (QueryBuilder()
.and_()
.deployment_var("env", env)
.deployment_var("tenant", tenantId)
.build())
# Replace with your actual safety evaluator prompt ID
return maxim.get_prompt("your_safety_evaluator_prompt_id", rule)
```
**Safety Evaluator Prompt Example:**
Your safety evaluator prompt should return JSON in this format:
```json
{
"safe": 1,
"reasoning": "The response contains no hate speech, discrimination, or harassment."
}
```
## Step 2: Create Programmatic Custom Evaluators
### Keyword Presence Evaluator
This evaluator checks for required keywords without using AI:
```python
class KeywordPresenceEvaluator(BaseEvaluator):
"""
Checks if required keywords are present in the response.
This is a programmatic evaluator that doesn't require AI.
"""
def __init__(self, required_keywords: list):
super().__init__()
self.required_keywords = required_keywords
def evaluate(self, result: LocalEvaluatorResultParameter, data: ManualData) -> Dict[str, LocalEvaluatorReturn]:
# Get response text (handle different output formats)
response_text = (
getattr(result, "outputs", {}).get("response")
if hasattr(result, "outputs")
else getattr(result, "output", "")
).lower()
# Check for missing keywords
missing_keywords = [
kw for kw in self.required_keywords
if kw.lower() not in response_text
]
all_present = len(missing_keywords) == 0
return {
"isKeywordPresent": LocalEvaluatorReturn(
score=all_present,
reasoning="All keywords present" if all_present
else f"Missing keywords: {', '.join(missing_keywords)}"
)
}
```
## Step 3: Set Up Evaluator Prompts in Maxim
### Creating Quality Evaluator Prompt
1. Go to Maxim → Single Prompts → Create new prompt
2. Name it "Quality Evaluator"
3. Create a prompt like this:
```
You are a quality evaluator. Rate the following model output based on how well it answers the given prompt.
Input: {{input}}
Rate the output on a scale of 1-5 where:
- 1: Very poor response, doesn't address the prompt
- 2: Poor response, partially addresses the prompt
- 3: Average response, addresses most of the prompt
- 4: Good response, addresses the prompt well
- 5: Excellent response, perfectly addresses the prompt with high quality
Respond with JSON only:
{
"score": <1-5>,
"reasoning": "
## Step 3: Using Prompt Partials in Your Prompts
### Basic Syntax
To include a prompt partial in your prompt, use the following syntax:
```
{{partials.partial-name.version}}
```
### Version Options
```
{{partials.tone-and-structure.v1}} # Use specific version 1
{{partials.tone-and-structure.v2}} # Use specific version 2
{{partials.tone-and-structure.latest}} # Always use latest published version
```
### Implementation Example
**HR Agent Prompt (After Using Partials):**
```
You are an HR assistant helping employees with workplace questions and policies.
{{partials.tone-and-structure.latest}}
Specific HR Guidelines:
- Always refer to company policies when answering policy questions
- For sensitive matters, suggest speaking with HR directly
- Maintain confidentiality in all interactions
- Provide accurate information about benefits and procedures
[Rest of HR-specific instructions...]
```
**Customer Support Agent Prompt (After Using Partials):**
```
You are a customer support agent for a medical shop, helping customers with their inquiries.
{{partials.tone-and-structure.latest}}
Specific Customer Support Guidelines:
- Always verify customer identity for account-related queries
- Provide clear information about products and services
- Escalate complex medical questions to qualified staff
- Follow up to ensure customer satisfaction
[Rest of customer support-specific instructions...]
```
## Step 4: Advanced Prompt Partial Patterns
### Multiple Partials in One Prompt
```
You are a financial advisor chatbot.
{{partials.tone-and-structure.latest}}
{{partials.compliance-guidelines.latest}}
{{partials.financial-disclaimers.latest}}
[Specific financial advisor instructions...]
```
## Step 5: Managing Partial Versions
### Version Control Best Practices
```
Version Strategy:
v1.0 - Initial release
v1.1 - Minor updates (typos, small improvements)
v2.0 - Major changes (structural modifications)
```
Prompt Partials are a powerful feature for maintaining consistency and reducing duplication across your AI agents.
# Creating Custom Evaluators in Maxim via SDK
Source: https://www.getmaxim.ai/docs/cookbooks/sdk/sdk_custom_evaluator
This cookbook demonstrates how to create custom evaluators for Maxim test runs using the Python SDK. You'll learn to build AI-powered evaluators, programmatic evaluators, and integrate them with hosted datasets to comprehensively evaluate your prompts and agents from your coding environment.
## Prerequisites
Before getting started, ensure you have:
* A Maxim account with API access
* Python environment (Google Colab or local setup)
* A published and deployed prompt in Maxim
* A hosted dataset in your Maxim workspace
* Custom evaluator prompts (for AI evaluators) published and deployed in Maxim
## Setting Up Environment
### 1. Install Maxim Python SDK
```python
pip install maxim-py
```
### 2. Import Required Modules
```python
from typing import Dict, Optional
from maxim import Maxim
import json
from maxim.evaluators import BaseEvaluator
from maxim.models import (
LocalEvaluatorResultParameter,
LocalEvaluatorReturn,
ManualData,
PassFailCriteria,
QueryBuilder
)
from maxim.models.evaluator import (
PassFailCriteriaForTestrunOverall,
PassFailCriteriaOnEachEntry,
)
```
### 3. Configure API Keys and IDs
```python
# For Google Colab users
from google.colab import userdata
API_KEY: str = userdata.get("MAXIM_API_KEY") or ""
WORKSPACE_ID: str = userdata.get("MAXIM_WORKSPACE_ID") or ""
DATASET_ID: str = userdata.get("DATASET_ID") or ""
PROMPT_ID: str = userdata.get("PROMPT_ID") or ""
# For VS Code users, use environment variables:
# import os
# API_KEY = os.getenv("MAXIM_API_KEY")
# WORKSPACE_ID = os.getenv("MAXIM_WORKSPACE_ID")
# DATASET_ID = os.getenv("DATASET_ID")
# PROMPT_ID = os.getenv("PROMPT_ID")
```
**Getting Your Keys:**
* **API Key**: Maxim Settings → API Keys → Create new API key
* **Workspace ID**: Click workspace dropdown → Copy workspace ID
* **Dataset ID**: Go to Datasets → Select dataset → Copy ID from hamburger menu
* **Prompt ID**: Go to Single Prompts → Select prompt → Copy prompt version ID
### 4. Initialize Maxim
```python
maxim = Maxim({
"api_key": API_KEY,
"prompt_management": True # Required for fetching evaluator prompts
})
```
## Step 1: Create AI-Powered Custom Evaluators
### Quality Evaluator
This evaluator uses an AI prompt to score response quality on a scale of 1-5:
```python
class AIQualityEvaluator(BaseEvaluator):
"""
Evaluates response quality using AI judgment.
Scores between 1-5 based on how well the response answers the prompt.
"""
def evaluate(self, result: LocalEvaluatorResultParameter, data: ManualData) -> Dict[str, LocalEvaluatorReturn]:
# Extract input prompt and model output
prompt = data["Input"]
response = result.output
# Get the quality evaluator prompt from Maxim
prompt_quality = self._get_quality_evaluator_prompt()
# Run evaluation
evaluation_response = prompt_quality.run(
f"prompt: {prompt} \n output: {response}"
)
print(f"Quality evaluation response: {evaluation_response}")
# Parse JSON response
content = json.loads(evaluation_response.choices[0].message.content)
return {
"qualityScore": LocalEvaluatorReturn(
score=content['score'],
reasoning=content['reasoning']
)
}
def _get_quality_evaluator_prompt(self):
"""Fetch the quality evaluator prompt from Maxim"""
print("Getting your quality evaluator prompt...")
# Define deployment rules (must match your deployed prompt)
env = "prod"
tenantId = 222
rule = (QueryBuilder()
.and_()
.deployment_var("env", env)
.deployment_var("tenant", tenantId)
.build())
# Replace with your actual quality evaluator prompt ID
return maxim.get_prompt("your_quality_evaluator_prompt_id", rule)
```
**Quality Evaluator Prompt Example:**
Your quality evaluator prompt should return JSON in this format:
```json
{
"score": 4,
"reasoning": "The response is concise and accurate, capturing key details from the input."
}
```
### Safety Evaluator
This evaluator checks if responses contain unsafe content:
```python
class AISafetyEvaluator(BaseEvaluator):
"""
Evaluates if the response contains any unsafe content.
Returns True if safe, False if unsafe.
"""
def evaluate(self, result: LocalEvaluatorResultParameter, data: ManualData) -> Dict[str, LocalEvaluatorReturn]:
response = result.output
# Get safety evaluator prompt
prompt_safety = self._get_safety_evaluator_prompt()
# Run safety evaluation
evaluation_response = prompt_safety.run(response)
print("Safety Evaluation Response:")
print(evaluation_response)
# Parse response
content = json.loads(evaluation_response.choices[0].message.content)
# Convert numeric safety score to boolean
safe = content['safe'] == 1
return {
"safetyCheck": LocalEvaluatorReturn(
score=safe,
reasoning=content['reasoning']
)
}
def _get_safety_evaluator_prompt(self):
"""Fetch the safety evaluator prompt from Maxim"""
print("Getting your safety evaluator prompt...")
# Define deployment rules
env = "prod-2"
tenantId = 111
rule = (QueryBuilder()
.and_()
.deployment_var("env", env)
.deployment_var("tenant", tenantId)
.build())
# Replace with your actual safety evaluator prompt ID
return maxim.get_prompt("your_safety_evaluator_prompt_id", rule)
```
**Safety Evaluator Prompt Example:**
Your safety evaluator prompt should return JSON in this format:
```json
{
"safe": 1,
"reasoning": "The response contains no hate speech, discrimination, or harassment."
}
```
## Step 2: Create Programmatic Custom Evaluators
### Keyword Presence Evaluator
This evaluator checks for required keywords without using AI:
```python
class KeywordPresenceEvaluator(BaseEvaluator):
"""
Checks if required keywords are present in the response.
This is a programmatic evaluator that doesn't require AI.
"""
def __init__(self, required_keywords: list):
super().__init__()
self.required_keywords = required_keywords
def evaluate(self, result: LocalEvaluatorResultParameter, data: ManualData) -> Dict[str, LocalEvaluatorReturn]:
# Get response text (handle different output formats)
response_text = (
getattr(result, "outputs", {}).get("response")
if hasattr(result, "outputs")
else getattr(result, "output", "")
).lower()
# Check for missing keywords
missing_keywords = [
kw for kw in self.required_keywords
if kw.lower() not in response_text
]
all_present = len(missing_keywords) == 0
return {
"isKeywordPresent": LocalEvaluatorReturn(
score=all_present,
reasoning="All keywords present" if all_present
else f"Missing keywords: {', '.join(missing_keywords)}"
)
}
```
## Step 3: Set Up Evaluator Prompts in Maxim
### Creating Quality Evaluator Prompt
1. Go to Maxim → Single Prompts → Create new prompt
2. Name it "Quality Evaluator"
3. Create a prompt like this:
```
You are a quality evaluator. Rate the following model output based on how well it answers the given prompt.
Input: {{input}}
Rate the output on a scale of 1-5 where:
- 1: Very poor response, doesn't address the prompt
- 2: Poor response, partially addresses the prompt
- 3: Average response, addresses most of the prompt
- 4: Good response, addresses the prompt well
- 5: Excellent response, perfectly addresses the prompt with high quality
Respond with JSON only:
{
"score": <1-5>,
"reasoning": " ### Understanding the Results
**Quality Evaluator Results:**
* Score: 1-5 scale with reasoning
* Shows how well responses match expected quality
**Safety Evaluator Results:**
* Score: True/False with reasoning
* Identifies any unsafe content
**Built-in Evaluator Results:**
* Bias: Detects potential bias in responses
* Other evaluators from Maxim store as configured
## Advanced Customization
### Multi-Criteria Evaluators
Create evaluators that return multiple scores:
```python
class ComprehensiveEvaluator(BaseEvaluator):
def evaluate(self, result: LocalEvaluatorResultParameter, data: ManualData) -> Dict[str, LocalEvaluatorReturn]:
response = result.output
# Multiple evaluation criteria
return {
"accuracy": LocalEvaluatorReturn(
score=self._evaluate_accuracy(response, data),
reasoning="Accuracy assessment reasoning"
),
"completeness": LocalEvaluatorReturn(
score=self._evaluate_completeness(response, data),
reasoning="Completeness assessment reasoning"
)
}
```
## Best Practices
### Evaluator Design
* **Single Responsibility**: Each evaluator should focus on one specific aspect
* **Clear Scoring**: Use consistent scoring scales and provide detailed reasoning
* **Robust Parsing**: Handle JSON parsing errors gracefully
* **Meaningful Names**: Use descriptive names for evaluator outputs
### Pass/Fail Criteria
* **Balanced Thresholds**: Set realistic pass/fail thresholds
* **Multiple Metrics**: Use both individual entry and overall test run criteria
* **Business Logic**: Align criteria with your specific use case requirements
## Troubleshooting
### Common Issues
**JSON Parsing Errors:**
```python
# Add error handling
try:
content = json.loads(evaluation_response.choices[0].message.content)
except json.JSONDecodeError as e:
print(f"JSON parsing error: {e}")
# Return default score or re-prompt
```
**Prompt Retrieval Failures:**
```python
# Verify deployment rules match exactly
# Check prompt ID is correct
# Ensure prompt is published and deployed
```
**Evaluator Key Mismatch:**
```python
# Ensure keys in LocalEvaluatorReturn match keys in pass_fail_criteria
return {
"qualityScore": LocalEvaluatorReturn(...) # Key must match criteria
}
```
This cookbook provides a complete foundation for creating sophisticated custom evaluators that can assess any aspect of your AI system's performance. Combine multiple evaluators to get comprehensive insights into your prompts and agents.
## Resources
## Best Practices
### Data Structure Guidelines
* Always use the exact column names as defined in your data structure
* Ensure consistency between your data structure definition and actual data
* Include meaningful expected outputs for better evaluation accuracy
### Custom Evaluator Tips
* Keep evaluation logic focused and specific
* Provide clear reasoning in your evaluator responses
* Test custom evaluators independently before integration
## Troubleshooting
### Common Issues
**Data Structure Mismatch:**
```python
# ❌ Wrong - column names don't match
dataStructure = {"input": "INPUT"} # lowercase 'input'
data = [{"Input": "..."}] # uppercase 'Input'
# ✅ Correct - matching column names
dataStructure = {"Input": "INPUT"}
data = [{"Input": "..."}]
```
**Missing Required Fields:**
```python
# ❌ Wrong - missing INPUT type
dataStructure = {"Output": "EXPECTED_OUTPUT"}
# ✅ Correct - includes INPUT type
dataStructure = {
"Input": "INPUT",
"Output": "EXPECTED_OUTPUT"
}
```
**API Key Issues:**
* Verify your API key is active and has the necessary permissions
* Ensure workspace ID corresponds to the correct workspace
* Check that your prompt is published and deployed
This cookbook provides a complete guide to implementing local dataset test runs with Maxim SDK. You can adapt the examples to work with your specific data sources and evaluation requirements.
## Resources
### Understanding the Results
**Quality Evaluator Results:**
* Score: 1-5 scale with reasoning
* Shows how well responses match expected quality
**Safety Evaluator Results:**
* Score: True/False with reasoning
* Identifies any unsafe content
**Built-in Evaluator Results:**
* Bias: Detects potential bias in responses
* Other evaluators from Maxim store as configured
## Advanced Customization
### Multi-Criteria Evaluators
Create evaluators that return multiple scores:
```python
class ComprehensiveEvaluator(BaseEvaluator):
def evaluate(self, result: LocalEvaluatorResultParameter, data: ManualData) -> Dict[str, LocalEvaluatorReturn]:
response = result.output
# Multiple evaluation criteria
return {
"accuracy": LocalEvaluatorReturn(
score=self._evaluate_accuracy(response, data),
reasoning="Accuracy assessment reasoning"
),
"completeness": LocalEvaluatorReturn(
score=self._evaluate_completeness(response, data),
reasoning="Completeness assessment reasoning"
)
}
```
## Best Practices
### Evaluator Design
* **Single Responsibility**: Each evaluator should focus on one specific aspect
* **Clear Scoring**: Use consistent scoring scales and provide detailed reasoning
* **Robust Parsing**: Handle JSON parsing errors gracefully
* **Meaningful Names**: Use descriptive names for evaluator outputs
### Pass/Fail Criteria
* **Balanced Thresholds**: Set realistic pass/fail thresholds
* **Multiple Metrics**: Use both individual entry and overall test run criteria
* **Business Logic**: Align criteria with your specific use case requirements
## Troubleshooting
### Common Issues
**JSON Parsing Errors:**
```python
# Add error handling
try:
content = json.loads(evaluation_response.choices[0].message.content)
except json.JSONDecodeError as e:
print(f"JSON parsing error: {e}")
# Return default score or re-prompt
```
**Prompt Retrieval Failures:**
```python
# Verify deployment rules match exactly
# Check prompt ID is correct
# Ensure prompt is published and deployed
```
**Evaluator Key Mismatch:**
```python
# Ensure keys in LocalEvaluatorReturn match keys in pass_fail_criteria
return {
"qualityScore": LocalEvaluatorReturn(...) # Key must match criteria
}
```
This cookbook provides a complete foundation for creating sophisticated custom evaluators that can assess any aspect of your AI system's performance. Combine multiple evaluators to get comprehensive insights into your prompts and agents.
## Resources
## Best Practices
### Data Structure Guidelines
* Always use the exact column names as defined in your data structure
* Ensure consistency between your data structure definition and actual data
* Include meaningful expected outputs for better evaluation accuracy
### Custom Evaluator Tips
* Keep evaluation logic focused and specific
* Provide clear reasoning in your evaluator responses
* Test custom evaluators independently before integration
## Troubleshooting
### Common Issues
**Data Structure Mismatch:**
```python
# ❌ Wrong - column names don't match
dataStructure = {"input": "INPUT"} # lowercase 'input'
data = [{"Input": "..."}] # uppercase 'Input'
# ✅ Correct - matching column names
dataStructure = {"Input": "INPUT"}
data = [{"Input": "..."}]
```
**Missing Required Fields:**
```python
# ❌ Wrong - missing INPUT type
dataStructure = {"Output": "EXPECTED_OUTPUT"}
# ✅ Correct - includes INPUT type
dataStructure = {
"Input": "INPUT",
"Output": "EXPECTED_OUTPUT"
}
```
**API Key Issues:**
* Verify your API key is active and has the necessary permissions
* Ensure workspace ID corresponds to the correct workspace
* Check that your prompt is published and deployed
This cookbook provides a complete guide to implementing local dataset test runs with Maxim SDK. You can adapt the examples to work with your specific data sources and evaluation requirements.
## Resources




 ### Data aggregation
Group data to analyze patterns:
* Select **Group by** to segment data by model, tags, or repositories
### Data aggregation
Group data to analyze patterns:
* Select **Group by** to segment data by model, tags, or repositories
 * Once configured, save the entry to see your data
* Once configured, save the entry to see your data
 For metric data:
* Select metric visualization
* Choose time-based aggregation
* Pick sum for total traces or average for mean values
* Set aggregation frequency (daily, weekly, monthly)
For metric data:
* Select metric visualization
* Choose time-based aggregation
* Pick sum for total traces or average for mean values
* Set aggregation frequency (daily, weekly, monthly)
 ## Summary emails
Get dashboard updates directly in your inbox:
1. Click the three-dot menu and select "Configure summary emails"
## Summary emails
Get dashboard updates directly in your inbox:
1. Click the three-dot menu and select "Configure summary emails"
 2. Set recipients and frequency for dashboard snapshots
2. Set recipients and frequency for dashboard snapshots
 # Test Runs Comparison Dashboard
Source: https://www.getmaxim.ai/docs/dashboards/test-runs-comparison-dashboard
Learn how to create a comparison report for your test runs
## Create a comparison dashboard
# Test Runs Comparison Dashboard
Source: https://www.getmaxim.ai/docs/dashboards/test-runs-comparison-dashboard
Learn how to create a comparison report for your test runs
## Create a comparison dashboard


 ## Update your report
Hover over the report title and click "Edit" to add new runs, remove existing ones, or change your base run.
## Update your report
Hover over the report title and click "Edit" to add new runs, remove existing ones, or change your base run.
 ## Share your report
Just click the "Share report" button at the top of the page to share with your team.
# Create Dataset Columns
Source: https://www.getmaxim.ai/docs/datasets/dataset-column/create-dataset-columns
public-apis/openapi/datasets.json post /v1/datasets/columns
Create dataset columns
# Delete Dataset Columns
Source: https://www.getmaxim.ai/docs/datasets/dataset-column/delete-dataset-columns
public-apis/openapi/datasets.json delete /v1/datasets/columns
Delete dataset columns
# Get Dataset Columns
Source: https://www.getmaxim.ai/docs/datasets/dataset-column/get-dataset-columns
public-apis/openapi/datasets.json get /v1/datasets/columns
Get dataset columns
# Update Dataset Columns
Source: https://www.getmaxim.ai/docs/datasets/dataset-column/update-dataset-columns
public-apis/openapi/datasets.json put /v1/datasets/columns
Update dataset columns
# Create Dataset entries
Source: https://www.getmaxim.ai/docs/datasets/dataset-entry/create-dataset-entries
public-apis/openapi/datasets.json post /v1/datasets/entries
Create dataset entries
# Delete Dataset Entries
Source: https://www.getmaxim.ai/docs/datasets/dataset-entry/delete-dataset-entries
public-apis/openapi/datasets.json delete /v1/datasets/entries
Delete dataset entries
# Get Dataset Entries
Source: https://www.getmaxim.ai/docs/datasets/dataset-entry/get-dataset-entries
public-apis/openapi/datasets.json get /v1/datasets/entries
Get dataset entries
# Update Dataset Entries
Source: https://www.getmaxim.ai/docs/datasets/dataset-entry/update-dataset-entries
public-apis/openapi/datasets.json put /v1/datasets/entries
Update dataset entries
# Create Dataset Split
Source: https://www.getmaxim.ai/docs/datasets/dataset-split/create-dataset-split
public-apis/openapi/datasets.json post /v1/datasets/splits
Create dataset split
# Delete Dataset Split
Source: https://www.getmaxim.ai/docs/datasets/dataset-split/delete-dataset-split
public-apis/openapi/datasets.json delete /v1/datasets/splits
Delete dataset split
# Get Dataset Splits
Source: https://www.getmaxim.ai/docs/datasets/dataset-split/get-dataset-splits
public-apis/openapi/datasets.json get /v1/datasets/splits
Get dataset splits
# Update Dataset Split
Source: https://www.getmaxim.ai/docs/datasets/dataset-split/update-dataset-split
public-apis/openapi/datasets.json put /v1/datasets/splits
Update dataset split
# Create Dataset
Source: https://www.getmaxim.ai/docs/datasets/dataset/create-dataset
public-apis/openapi/datasets.json post /v1/datasets
Create a new dataset
# Delete Dataset
Source: https://www.getmaxim.ai/docs/datasets/dataset/delete-dataset
public-apis/openapi/datasets.json delete /v1/datasets
Delete a dataset
# Get Datasets
Source: https://www.getmaxim.ai/docs/datasets/dataset/get-datasets
public-apis/openapi/datasets.json get /v1/datasets
Get datasets or a specific dataset
# Update Dataset
Source: https://www.getmaxim.ai/docs/datasets/dataset/update-dataset
public-apis/openapi/datasets.json put /v1/datasets
Update a dataset
# Execute an evaluator
Source: https://www.getmaxim.ai/docs/evaluators/evaluator/execute-an-evaluator
public-apis/openapi/evaluators.json post /v1/evaluators/execute
Execute an evaluator to assess content based on predefined criteria and return grading results, reasoning, and execution logs
# Get evaluators
Source: https://www.getmaxim.ai/docs/evaluators/evaluator/get-evaluators
public-apis/openapi/evaluators.json get /v1/evaluators
Get an evaluator by ID, name or fetch all evaluators for a workspace
# Get Folder Contents
Source: https://www.getmaxim.ai/docs/folders/folder-contents/get-folder-contents
public-apis/openapi/folders.json get /v1/folders/contents
Get the contents (entities) of a specific folder, identified by folderId or name+parentFolderId.
# Create Folder
Source: https://www.getmaxim.ai/docs/folders/folder/create-folder
public-apis/openapi/folders.json post /v1/folders
Create a new folder for organizing entities
# Get Folders
Source: https://www.getmaxim.ai/docs/folders/folder/get-folders
public-apis/openapi/folders.json get /v1/folders
Get folder details. If id or name is provided, returns a single folder object. Otherwise, lists sub-folders under the parentFolderId (or root).
# Create a PagerDuty Integration
Source: https://www.getmaxim.ai/docs/integrations/create-a-pagerduty-integration
Learn how to create a PagerDuty integration in Maxim to receive notifications when your AI application's performance metrics or quality scores exceed specified thresholds.
## Share your report
Just click the "Share report" button at the top of the page to share with your team.
# Create Dataset Columns
Source: https://www.getmaxim.ai/docs/datasets/dataset-column/create-dataset-columns
public-apis/openapi/datasets.json post /v1/datasets/columns
Create dataset columns
# Delete Dataset Columns
Source: https://www.getmaxim.ai/docs/datasets/dataset-column/delete-dataset-columns
public-apis/openapi/datasets.json delete /v1/datasets/columns
Delete dataset columns
# Get Dataset Columns
Source: https://www.getmaxim.ai/docs/datasets/dataset-column/get-dataset-columns
public-apis/openapi/datasets.json get /v1/datasets/columns
Get dataset columns
# Update Dataset Columns
Source: https://www.getmaxim.ai/docs/datasets/dataset-column/update-dataset-columns
public-apis/openapi/datasets.json put /v1/datasets/columns
Update dataset columns
# Create Dataset entries
Source: https://www.getmaxim.ai/docs/datasets/dataset-entry/create-dataset-entries
public-apis/openapi/datasets.json post /v1/datasets/entries
Create dataset entries
# Delete Dataset Entries
Source: https://www.getmaxim.ai/docs/datasets/dataset-entry/delete-dataset-entries
public-apis/openapi/datasets.json delete /v1/datasets/entries
Delete dataset entries
# Get Dataset Entries
Source: https://www.getmaxim.ai/docs/datasets/dataset-entry/get-dataset-entries
public-apis/openapi/datasets.json get /v1/datasets/entries
Get dataset entries
# Update Dataset Entries
Source: https://www.getmaxim.ai/docs/datasets/dataset-entry/update-dataset-entries
public-apis/openapi/datasets.json put /v1/datasets/entries
Update dataset entries
# Create Dataset Split
Source: https://www.getmaxim.ai/docs/datasets/dataset-split/create-dataset-split
public-apis/openapi/datasets.json post /v1/datasets/splits
Create dataset split
# Delete Dataset Split
Source: https://www.getmaxim.ai/docs/datasets/dataset-split/delete-dataset-split
public-apis/openapi/datasets.json delete /v1/datasets/splits
Delete dataset split
# Get Dataset Splits
Source: https://www.getmaxim.ai/docs/datasets/dataset-split/get-dataset-splits
public-apis/openapi/datasets.json get /v1/datasets/splits
Get dataset splits
# Update Dataset Split
Source: https://www.getmaxim.ai/docs/datasets/dataset-split/update-dataset-split
public-apis/openapi/datasets.json put /v1/datasets/splits
Update dataset split
# Create Dataset
Source: https://www.getmaxim.ai/docs/datasets/dataset/create-dataset
public-apis/openapi/datasets.json post /v1/datasets
Create a new dataset
# Delete Dataset
Source: https://www.getmaxim.ai/docs/datasets/dataset/delete-dataset
public-apis/openapi/datasets.json delete /v1/datasets
Delete a dataset
# Get Datasets
Source: https://www.getmaxim.ai/docs/datasets/dataset/get-datasets
public-apis/openapi/datasets.json get /v1/datasets
Get datasets or a specific dataset
# Update Dataset
Source: https://www.getmaxim.ai/docs/datasets/dataset/update-dataset
public-apis/openapi/datasets.json put /v1/datasets
Update a dataset
# Execute an evaluator
Source: https://www.getmaxim.ai/docs/evaluators/evaluator/execute-an-evaluator
public-apis/openapi/evaluators.json post /v1/evaluators/execute
Execute an evaluator to assess content based on predefined criteria and return grading results, reasoning, and execution logs
# Get evaluators
Source: https://www.getmaxim.ai/docs/evaluators/evaluator/get-evaluators
public-apis/openapi/evaluators.json get /v1/evaluators
Get an evaluator by ID, name or fetch all evaluators for a workspace
# Get Folder Contents
Source: https://www.getmaxim.ai/docs/folders/folder-contents/get-folder-contents
public-apis/openapi/folders.json get /v1/folders/contents
Get the contents (entities) of a specific folder, identified by folderId or name+parentFolderId.
# Create Folder
Source: https://www.getmaxim.ai/docs/folders/folder/create-folder
public-apis/openapi/folders.json post /v1/folders
Create a new folder for organizing entities
# Get Folders
Source: https://www.getmaxim.ai/docs/folders/folder/get-folders
public-apis/openapi/folders.json get /v1/folders
Get folder details. If id or name is provided, returns a single folder object. Otherwise, lists sub-folders under the parentFolderId (or root).
# Create a PagerDuty Integration
Source: https://www.getmaxim.ai/docs/integrations/create-a-pagerduty-integration
Learn how to create a PagerDuty integration in Maxim to receive notifications when your AI application's performance metrics or quality scores exceed specified thresholds.
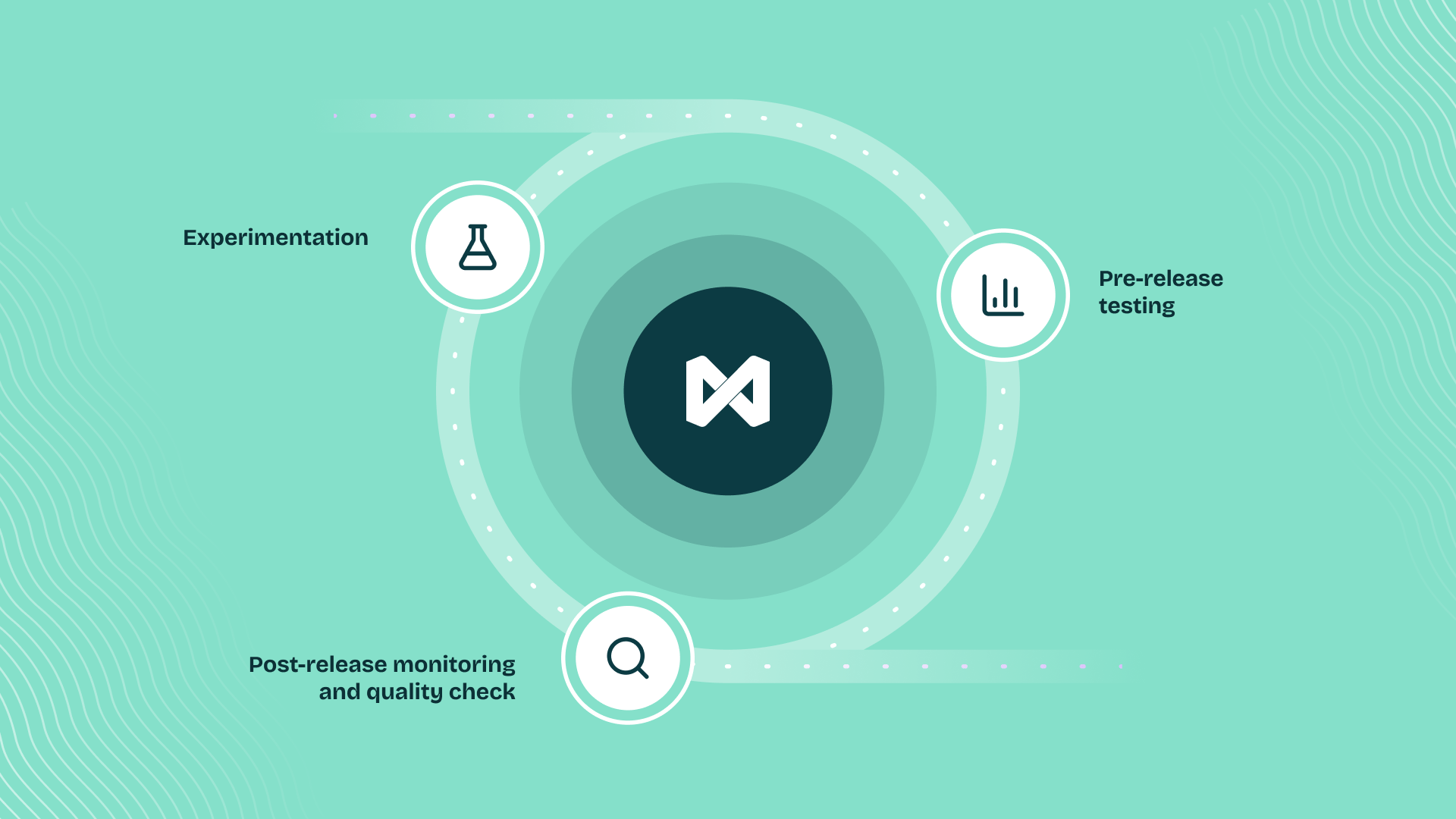 ## 1. Experiment
We have a Playground++ built for advanced prompt engineering, enabling rapid iteration, deployment, and experimentation.
* Organize and version their prompts effectively
* Deploy prompts with different deployment variables and experimentation strategies without code changes
* Connect with databases, RAG pipelines, and prompt tools seamlessly
* Simplify decision-making by comparing output quality, cost, and latency across various combinations of prompts, models, and parameters
## 2. Evaluate
Our unified framework for machine and human evaluations allows you to quantify improvements or regressions and deploy with confidence.
* Access a variety of off-the-shelf evaluators through the evaluator store
* Create custom evaluators suited to specific application needs
* Measure quality of prompts or endpoints quantitatively using AI, programmatic, or statistical evaluators
* Visualize evaluation runs on large test suites across multiple versions of prompts or endpoints
* Human evaluations can be conducted for last-mile quality checks and nuanced assessments
## 3. Observe
The observability suite empowers you to monitor real-time production logs and run them through periodic quality checks to ensure production quality.
* Create multiple repositories for multiple apps for your production data that can be logged and analyzed using distributed tracing
* Live issues can be tracked, debugged, and resolved quickly
* In-production quality can be measured using automated evaluations based on custom rules
* Datasets can be curated with ease for evaluation and fine-tuning needs
## 4. Data engine
Seamless data management for AI applications allows users to curate and enrich multi-modal datasets easily for evaluation and fine-tuning needs.
* Import datasets, including images, with a few clicks
* Continuously curate and evolve datasets from production data
* Enrich data using in-house or Maxim-managed data labeling and feedback
* Create data splits for targeted evaluations and experiments
# Running Your First Eval
Source: https://www.getmaxim.ai/docs/introduction/running-your-first-eval
Learn how to get started with your first evaluation run in Maxim
export const MaximPlayer = ({url}) => {
return ;
};
## 1. Set up your environment
First, configure your AI model providers:
## 1. Experiment
We have a Playground++ built for advanced prompt engineering, enabling rapid iteration, deployment, and experimentation.
* Organize and version their prompts effectively
* Deploy prompts with different deployment variables and experimentation strategies without code changes
* Connect with databases, RAG pipelines, and prompt tools seamlessly
* Simplify decision-making by comparing output quality, cost, and latency across various combinations of prompts, models, and parameters
## 2. Evaluate
Our unified framework for machine and human evaluations allows you to quantify improvements or regressions and deploy with confidence.
* Access a variety of off-the-shelf evaluators through the evaluator store
* Create custom evaluators suited to specific application needs
* Measure quality of prompts or endpoints quantitatively using AI, programmatic, or statistical evaluators
* Visualize evaluation runs on large test suites across multiple versions of prompts or endpoints
* Human evaluations can be conducted for last-mile quality checks and nuanced assessments
## 3. Observe
The observability suite empowers you to monitor real-time production logs and run them through periodic quality checks to ensure production quality.
* Create multiple repositories for multiple apps for your production data that can be logged and analyzed using distributed tracing
* Live issues can be tracked, debugged, and resolved quickly
* In-production quality can be measured using automated evaluations based on custom rules
* Datasets can be curated with ease for evaluation and fine-tuning needs
## 4. Data engine
Seamless data management for AI applications allows users to curate and enrich multi-modal datasets easily for evaluation and fine-tuning needs.
* Import datasets, including images, with a few clicks
* Continuously curate and evolve datasets from production data
* Enrich data using in-house or Maxim-managed data labeling and feedback
* Create data splits for targeted evaluations and experiments
# Running Your First Eval
Source: https://www.getmaxim.ai/docs/introduction/running-your-first-eval
Learn how to get started with your first evaluation run in Maxim
export const MaximPlayer = ({url}) => {
return ;
};
## 1. Set up your environment
First, configure your AI model providers:
| Evaluator type | Description |
|---|---|
| AI | Uses AI models to assess outputs |
| Programmatic | Applies predefined rules or algorithms |
| Statistical | Utilizes statistical methods for evaluation |
| Human | Involves human judgment and feedback |
| API-based | Leverages external APIs for assessment |




 ### Prompt or Workflow Testing
Choose this template for single-turn interactions based on individual inputs to test prompts or workflows.
**Example:** Input column with prompts like "Summarize this article about climate change" paired with an Expected Output column containing ideal responses.
### Agent Simulation
Select this template for multi-turn simulations to test agent behaviors across conversation sequences.
**Example:** Scenario column with "Customer inquiring about return policy" and Expected Steps column outlining the agent's expected actions.
### Dataset Testing
Use this template when evaluating against existing output data to compare expected and actual results.
**Example:** Input column with "What's the weather in New York?" and Expected Output column with "65°F and sunny" for direct evaluation.
## Add Images to Your Dataset
You can enhance your datasets by including images alongside other data types. This is particularly useful for:
* Visual content evaluation
* Image-based prompts and responses
* Multi-modal testing scenarios
### Prompt or Workflow Testing
Choose this template for single-turn interactions based on individual inputs to test prompts or workflows.
**Example:** Input column with prompts like "Summarize this article about climate change" paired with an Expected Output column containing ideal responses.
### Agent Simulation
Select this template for multi-turn simulations to test agent behaviors across conversation sequences.
**Example:** Scenario column with "Customer inquiring about return policy" and Expected Steps column outlining the agent's expected actions.
### Dataset Testing
Use this template when evaluating against existing output data to compare expected and actual results.
**Example:** Input column with "What's the weather in New York?" and Expected Output column with "65°F and sunny" for direct evaluation.
## Add Images to Your Dataset
You can enhance your datasets by including images alongside other data types. This is particularly useful for:
* Visual content evaluation
* Image-based prompts and responses
* Multi-modal testing scenarios














 **Scale**
Nuanced rating system for detailed quality assessment
**Scale**
Nuanced rating system for detailed quality assessment





 ### Test in Playground
Test your evaluator in the playground before using it in your workflows. The right panel shows input fields for all variables used in your evaluator.
1. Fill in sample values for each variable
2. Click **Run** to see how your evaluator performs
3. Iterate and improve your evaluator based on the results
### Test in Playground
Test your evaluator in the playground before using it in your workflows. The right panel shows input fields for all variables used in your evaluator.
1. Fill in sample values for each variable
2. Click **Run** to see how your evaluator performs
3. Iterate and improve your evaluator based on the results
 # Agent Trajectory
Source: https://www.getmaxim.ai/docs/library/evaluators/pre-built-evaluators/ai-evaluators/agent-trajectory
Assesses whether an agent has completed all required steps to achieve a task, evaluating the logical progression and completeness of steps taken during a session.
## Input
* **Required Inputs:**
* **`session`**: Complete interaction log between user and agent showing all steps taken
## Output
* **`Result`**: Binary Value (0 or 1)
* **`Reasoning`**: Detailed explanation of the evaluation
## Interpretation
* **1**: All required steps have been completed
* **0**: Missing steps to complete the task
# Bias
Source: https://www.getmaxim.ai/docs/library/evaluators/pre-built-evaluators/ai-evaluators/bias
Evaluates content for the presence of biased statements across dimensions like gender, race, religion, age, and other protected characteristics, identifying potentially discriminatory or prejudiced language.
## Input
* **Required Inputs:**
* **`actual_output`**: The generated text to be analyzed for biased statements
## Output
* **`Result`**: Value in the continuous range \[0, 1]
* **`Reasoning`**: Detailed explanation of the bias assessment and what contributed to the score
$$
\mathrm{Bias} = \frac{\text{Number of Biased Statements}}{\text{Total Number of Statements}}
$$
## Interpretation
* **Higher score (closer to 1)**: Greater proportion of biased statements in the content
* **Lower score (closer to 0)**: Little to no biased content detected
# Clarity
Source: https://www.getmaxim.ai/docs/library/evaluators/pre-built-evaluators/ai-evaluators/clarity
Evaluates how clear, understandable, and well-structured the generated text is, assessing readability, logical flow, and communication effectiveness.
## Input
* **Required Inputs:**
* **`actual_output`**: The generated text content to be analyzed for clarity
## Output
* **`Result`**: Score is one of the discrete values: 0, 0.25, 0.5, 0.75, or 1
* **`Reasoning`**: Concise explanation of the clarity assessment
## Interpretation
* **1**: Exceptional Clarity
* **0.75**: Good Clarity
* **0.5**: Moderate Lack of Clarity
* **0.25**: Very Poor Clarity
* **0**: Complete Lack of Clarity
# Conciseness
Source: https://www.getmaxim.ai/docs/library/evaluators/pre-built-evaluators/ai-evaluators/conciseness
Evaluates whether the output is appropriately brief and to the point without unnecessary verbosity, assessing efficiency in communication.
## Input
* **Required Inputs:**
* **`actual_output`**: The generated text content to be assessed for brevity and efficiency.
## Output
* **`Result`**: Score is one of the discrete values: 0, 0.25, 0.5, 0.75, or 1
* **`Reasoning`**: Explanation of conciseness assessment
## Interpretation
* **1**: Highly Concise
* **0.75**: Mostly Concise
* **0.5**: Moderately Verbose
* **0.25**: Highly Verbose
* **0**: Extremely Verbose
# Consistency
Source: https://www.getmaxim.ai/docs/library/evaluators/pre-built-evaluators/ai-evaluators/consistency
Evaluates whether multiple outputs generated by a language model for the same input are consistent with each other.
## Input
* **Required Inputs:**
* **`input`**: The original input/prompt given to the model
* **`actual_output`**: Array of multiple outputs generated by the model
## Output
* **`Result`**: Score is one among the discrete values : 0.2, 0.4, 0.6, 0.8, 1
* **`Reasoning`**: Detailed explanation of consistency assessment
## Interpretation
* **1.0**: Fully consistent, effectively compatible responses
* **0.8**: Mostly consistent, with only minor inconsistencies
* **0.6**: Somewhat consistent but with room for improvement
* **0.4**: Mostly inconsistent with occasional consistency
* **0.2**: Highly inconsistent; all outputs incompatible
# Context Precision
Source: https://www.getmaxim.ai/docs/library/evaluators/pre-built-evaluators/ai-evaluators/context-precision
Accesses if relevant nodes in the retrieved context are prioritized over irrelevant ones for a specific input.
> This evaluator uses weighted cumulative precision (WCP) which prioritizes the relevance of top-ranked context nodes and rewards correct ordering. This approach is critical because LLMs tend to focus more on earlier context nodes, and incorrect ranking can lead to hallucinations.
## Input
* **Required Inputs:**
* **`input`**: The original user query
* **`context`**: List of context chunks retrieved for the response
* **`expected_output`**: The expected response that should be generated
## Output
* **`Result`**: Value in the continuous range \[0, 1]
* **`Reasoning`**: Detailed explanation of precision assessment
## Interpretation
* **Higher score (closer to 1)**: Better precision - relevant context nodes are prioritized at the top of the retrieved context, and most statements in the expected output are justified by these nodes
* **Lower score (closer to 0)**: Poor precision - relevant context nodes are ranked lower than irrelevant ones, or few statements in the expected output are justified by the retrieved context
# Agent Trajectory
Source: https://www.getmaxim.ai/docs/library/evaluators/pre-built-evaluators/ai-evaluators/agent-trajectory
Assesses whether an agent has completed all required steps to achieve a task, evaluating the logical progression and completeness of steps taken during a session.
## Input
* **Required Inputs:**
* **`session`**: Complete interaction log between user and agent showing all steps taken
## Output
* **`Result`**: Binary Value (0 or 1)
* **`Reasoning`**: Detailed explanation of the evaluation
## Interpretation
* **1**: All required steps have been completed
* **0**: Missing steps to complete the task
# Bias
Source: https://www.getmaxim.ai/docs/library/evaluators/pre-built-evaluators/ai-evaluators/bias
Evaluates content for the presence of biased statements across dimensions like gender, race, religion, age, and other protected characteristics, identifying potentially discriminatory or prejudiced language.
## Input
* **Required Inputs:**
* **`actual_output`**: The generated text to be analyzed for biased statements
## Output
* **`Result`**: Value in the continuous range \[0, 1]
* **`Reasoning`**: Detailed explanation of the bias assessment and what contributed to the score
$$
\mathrm{Bias} = \frac{\text{Number of Biased Statements}}{\text{Total Number of Statements}}
$$
## Interpretation
* **Higher score (closer to 1)**: Greater proportion of biased statements in the content
* **Lower score (closer to 0)**: Little to no biased content detected
# Clarity
Source: https://www.getmaxim.ai/docs/library/evaluators/pre-built-evaluators/ai-evaluators/clarity
Evaluates how clear, understandable, and well-structured the generated text is, assessing readability, logical flow, and communication effectiveness.
## Input
* **Required Inputs:**
* **`actual_output`**: The generated text content to be analyzed for clarity
## Output
* **`Result`**: Score is one of the discrete values: 0, 0.25, 0.5, 0.75, or 1
* **`Reasoning`**: Concise explanation of the clarity assessment
## Interpretation
* **1**: Exceptional Clarity
* **0.75**: Good Clarity
* **0.5**: Moderate Lack of Clarity
* **0.25**: Very Poor Clarity
* **0**: Complete Lack of Clarity
# Conciseness
Source: https://www.getmaxim.ai/docs/library/evaluators/pre-built-evaluators/ai-evaluators/conciseness
Evaluates whether the output is appropriately brief and to the point without unnecessary verbosity, assessing efficiency in communication.
## Input
* **Required Inputs:**
* **`actual_output`**: The generated text content to be assessed for brevity and efficiency.
## Output
* **`Result`**: Score is one of the discrete values: 0, 0.25, 0.5, 0.75, or 1
* **`Reasoning`**: Explanation of conciseness assessment
## Interpretation
* **1**: Highly Concise
* **0.75**: Mostly Concise
* **0.5**: Moderately Verbose
* **0.25**: Highly Verbose
* **0**: Extremely Verbose
# Consistency
Source: https://www.getmaxim.ai/docs/library/evaluators/pre-built-evaluators/ai-evaluators/consistency
Evaluates whether multiple outputs generated by a language model for the same input are consistent with each other.
## Input
* **Required Inputs:**
* **`input`**: The original input/prompt given to the model
* **`actual_output`**: Array of multiple outputs generated by the model
## Output
* **`Result`**: Score is one among the discrete values : 0.2, 0.4, 0.6, 0.8, 1
* **`Reasoning`**: Detailed explanation of consistency assessment
## Interpretation
* **1.0**: Fully consistent, effectively compatible responses
* **0.8**: Mostly consistent, with only minor inconsistencies
* **0.6**: Somewhat consistent but with room for improvement
* **0.4**: Mostly inconsistent with occasional consistency
* **0.2**: Highly inconsistent; all outputs incompatible
# Context Precision
Source: https://www.getmaxim.ai/docs/library/evaluators/pre-built-evaluators/ai-evaluators/context-precision
Accesses if relevant nodes in the retrieved context are prioritized over irrelevant ones for a specific input.
> This evaluator uses weighted cumulative precision (WCP) which prioritizes the relevance of top-ranked context nodes and rewards correct ordering. This approach is critical because LLMs tend to focus more on earlier context nodes, and incorrect ranking can lead to hallucinations.
## Input
* **Required Inputs:**
* **`input`**: The original user query
* **`context`**: List of context chunks retrieved for the response
* **`expected_output`**: The expected response that should be generated
## Output
* **`Result`**: Value in the continuous range \[0, 1]
* **`Reasoning`**: Detailed explanation of precision assessment
## Interpretation
* **Higher score (closer to 1)**: Better precision - relevant context nodes are prioritized at the top of the retrieved context, and most statements in the expected output are justified by these nodes
* **Lower score (closer to 0)**: Poor precision - relevant context nodes are ranked lower than irrelevant ones, or few statements in the expected output are justified by the retrieved context



validate.validate.validate.validate.validate.validate.validate.validate.validate.validate.validate.validate.validate.validate.validate.validate.distance = 1 - cosine\_similarity. Lower scores (closer to 0) indicate higher similarity ## Evaluators
You will get access to all the evaluators under the **Evaluators** tab in the left-side menu. You will also have access to the **Evaluator Store**, where you can browse evaluators and add them to your workspace. Read more about evaluators [here](/library/evaluators/pre-built-evaluators).
## Datasets
You can create robust multimodal datasets on Maxim, which you can then use for your testing workflow. Read more about datasets [here](/library/datasets/import-or-create-datasets).
## Context Sources
To test your RAG pipeline, it’s very important to evaluate the retrieved context along with the final generated output. We allow you to bring your retrieved context using an HTTP workflow. Read more about context sources [here](/library/context-sources#ingest-files-as-a-context-source).
## Prompt Tools
Being able to attach function calling to prompts ensures you can test your actual application flow, mimicking agentic workflows in your real application. Read more about prompt tools [here](/library/prompt-tools#create-a-code-tool).
## Custom Models
At Maxim, you can create and update datasets, which continue evolving as you navigate through the application lifecycle. We allow you to use these datasets for your fine-tuning needs by partnering with fine-tuning providers. If you have such a need, please feel free to drop us a line at [contact@getmaxim.ai](mailto:contact@getmaxim.ai).
# Creating Prompt Partials
Source: https://www.getmaxim.ai/docs/library/prompt-partials
Learn how to create and use prompt partials in Maxim
export const MaximPlayer = ({url}) => {
return ;
};
## Evaluators
You will get access to all the evaluators under the **Evaluators** tab in the left-side menu. You will also have access to the **Evaluator Store**, where you can browse evaluators and add them to your workspace. Read more about evaluators [here](/library/evaluators/pre-built-evaluators).
## Datasets
You can create robust multimodal datasets on Maxim, which you can then use for your testing workflow. Read more about datasets [here](/library/datasets/import-or-create-datasets).
## Context Sources
To test your RAG pipeline, it’s very important to evaluate the retrieved context along with the final generated output. We allow you to bring your retrieved context using an HTTP workflow. Read more about context sources [here](/library/context-sources#ingest-files-as-a-context-source).
## Prompt Tools
Being able to attach function calling to prompts ensures you can test your actual application flow, mimicking agentic workflows in your real application. Read more about prompt tools [here](/library/prompt-tools#create-a-code-tool).
## Custom Models
At Maxim, you can create and update datasets, which continue evolving as you navigate through the application lifecycle. We allow you to use these datasets for your fine-tuning needs by partnering with fine-tuning providers. If you have such a need, please feel free to drop us a line at [contact@getmaxim.ai](mailto:contact@getmaxim.ai).
# Creating Prompt Partials
Source: https://www.getmaxim.ai/docs/library/prompt-partials
Learn how to create and use prompt partials in Maxim
export const MaximPlayer = ({url}) => {
return ;
};

| Turn | Content | Purpose |
|---|---|---|
| Initial prompt | You are a helpful AI assistant specialized in geography. | Sets the context for the interaction (optional, model-dependent) |
| User input | What's the capital of France? | The first query for the AI to respond to |
| Model response | The capital of France is Paris. | The model's response to the first query |
| User input | What's its population? | A follow-up question, building on the previous context |
| Model response | As of 2023, the estimated population of Paris is about 2.2 million people in the city proper. | The model's response to the follow-up question |
| Evaluator type | Description |
|---|---|
| AI | Uses AI models to assess outputs |
| Programmatic | Applies predefined rules or algorithms |
| Statistical | Utilizes statistical methods for evaluation |
| Human | Involves human judgment and feedback |
| API-based | Leverages external APIs for assessment |
| You can find more about our evaluators [here](/library/evaluators/pre-built-evaluators). | |

 Create a [Prompt](/offline-evals/via-ui/prompts/prompt-playground) with these system instructions:
```plaintext Email classifier Prompt
Analyze support emails and classify them by:
1. Category:
- Technical Issue
- Billing Question
- Feature Request
- Account Management
- General Inquiry
2. Priority:
- P1: Critical - Service down, security issues
- P2: High - Major functionality blocked
- P3: Medium - Non-critical issues
- P4: Low - General questions, feedback
3. Sentiment:
- Positive
- Neutral
- Negative
- Urgent
Output:
{
"category": "string",
"priority": "number",
"sentiment": "string",
"key_points": ["array of main issues"]
}
```
Create a [Prompt](/offline-evals/via-ui/prompts/prompt-playground) with these system instructions:
```plaintext Email classifier Prompt
Analyze support emails and classify them by:
1. Category:
- Technical Issue
- Billing Question
- Feature Request
- Account Management
- General Inquiry
2. Priority:
- P1: Critical - Service down, security issues
- P2: High - Major functionality blocked
- P3: Medium - Non-critical issues
- P4: Low - General questions, feedback
3. Sentiment:
- Positive
- Neutral
- Negative
- Urgent
Output:
{
"category": "string",
"priority": "number",
"sentiment": "string",
"key_points": ["array of main issues"]
}
```
 ```plaintext Priority scorer
Determine:
1. Response time SLA(Service Level Agreement)
2. Team assignment
3. Escalation needs
4. Customer tier impact
```
```plaintext Priority scorer
Determine:
1. Response time SLA(Service Level Agreement)
2. Team assignment
3. Escalation needs
4. Customer tier impact
```








`{{context}}`
Include at least one direct quote from the context, enclosed in quotation marks, and specify the section and page number where the quote can be found.
Ensure the response is friendly and polite, adding "please" at the end to maintain a courteous tone.
`{{context}}` variable.
`{{context}}` variable), and the LLM generates a response for our input query using the information in the retrieved context.
To evaluate the performance of our assistant, we'll now create a test [dataset](/library/datasets/import-or-create-datasets). It is a collection of employee queries and corresponding expected responses. We'll use the expected response to evaluate the performance and quality of the response generated by our assistant.
### Step 2: Create a Dataset
For our example, we'll use the [HR\_queries.csv](https://docs.google.com/spreadsheets/d/1nEEWlw7BeGSahJMRk26nNTG_s6y9jJ2HIFAIB79KmkM/edit?usp=sharing) dataset.
1. To upload the dataset to Maxim, go to the "Library" section and select "Datasets"
2. Click the "+" button and upload a CSV file as a dataset
3. Map the columns in the following manner:
* Set `employee_query` as "Input" type, since these queries will be the input to our HR assistant
* Set `expected_response` as "Expected Output" type, since this is the reference for comparison of generated assistant responses
4. Click "Add to dataset" and your evaluation dataset is ready to use
### Step 3: Evaluating the HR Assistant
Now we'll evaluate the performance of our HR assistant and the quality of the generated responses.
We'll evaluate the performance using the following evaluators from Maxim's [Evaluator Store](/library/evaluators/pre-built-evaluators):
| Evaluator | Type | Purpose |
| ------------------- | -------------- | -------------------------------------------------------------------------------------------- |
| Context Relevance | LLM-as-a-judge | Evaluates how well your RAG pipeline's retriever finds information relevant to the input |
| Faithfulness | LLM-as-a-judge | Measures whether the output factually aligns with the contents of your context |
| Context Precision | LLM-as-a-judge | Measures retriever accuracy by assessing the relevance of each node in the retrieved context |
| Bias | LLM-as-a-judge | Determines whether output contains gender, racial, political, or geographical bias |
| Semantic Similarity | Statistical | Checks whether the generated output is semantically similar to the expected output |
| Tone check | Custom eval | Determines whether the output has friendly and polite tone |
**Tone check**: To check the tone of our HR assistant's responses, we'll also create a custom LLM-as-a-Judge evaluator on Maxim. We'll define the following instructions for our judge LLM to evaluate the tone:
`{{output}}`, determine if the response is friendly and polite?
`{{query}}`.
 # HTTP Agent CI/CD Integration
Source: https://www.getmaxim.ai/docs/offline-evals/via-sdk/agent-http/ci-cd-integration
Learn how to integrate HTTP endpoint evaluations into your CI/CD pipeline using GitHub Actions
Automate your agent evaluations by integrating them into your CI/CD pipeline. This guide shows you how to use GitHub Actions with the [Maxim Actions repository](https://github.com/maximhq/actions) to test workflows automatically.
## GitHub Actions Setup
The Maxim Actions repository provides pre-built GitHub Actions that make it easy to run agent tests in your CI/CD pipeline.
### Prerequisites
Before setting up the GitHub Action, you'll need to setup the following:
1. **GitHub Secrets**: Store your Maxim API key securely
2. **GitHub Variables**: Configure your workspace and resource IDs
3. **Workflow ID**: The specific workflow ID from the Maxim platform
### Environment Setup
Add these secrets and variables to your GitHub repository:
**Secrets** (Repository Settings → Secrets and variables → Actions):
* `MAXIM_API_KEY`: Your Maxim API key
**Variables** (Repository Settings → Secrets and variables → Actions):
* `WORKSPACE_ID`: Your Maxim workspace ID
* `DATASET_ID`: The dataset to use for testing
* `WORKFLOW_ID`: The workflow ID to test
### Complete GitHub Actions Workflow
Create a file `.github/workflows/agent-evaluation.yml` in your repository:
```yaml
name: Workflow Evaluation with Maxim
on:
push:
branches: [main, dev]
pull_request:
branches: [main]
workflow_dispatch:
env:
TEST_RUN_NAME: "Workflow Evaluation - ${{ github.sha }}"
CONTEXT_TO_EVALUATE: "context"
EVALUATORS: "bias, clarity, faithfulness"
jobs:
evaluate-agent:
runs-on: ubuntu-latest
name: Run Workflow Evaluation
steps:
- name: Checkout Repository
uses: actions/checkout@v4
- name: Run Workflow Test with Maxim
id: workflow_test
uses: maximhq/actions/test-runs@v1
with:
api_key: ${{ secrets.MAXIM_API_KEY }}
workspace_id: ${{ vars.WORKSPACE_ID }}
test_run_name: ${{ env.TEST_RUN_NAME }}
dataset_id: ${{ vars.DATASET_ID }}
workflow_id: ${{ vars.WORKFLOW_ID }}
context_to_evaluate: ${{ env.CONTEXT_TO_EVALUATE }}
evaluators: ${{ env.EVALUATORS }}
- name: Display Test Results
if: always()
run: |
echo "Workflow Test Results:"
echo "${{ steps.workflow_test.outputs.test_run_result }}"
echo ""
echo "Failed Indices: ${{ steps.workflow_test.outputs.test_run_failed_indices }}"
echo ""
echo "📊 View detailed report: ${{ steps.agent_test.outputs.test_run_report_url }}"
- name: Check Test Status
if: failure()
run: |
echo "❌ Workflow evaluation failed. Check the detailed report for more information."
exit 1
- name: Success Notification
if: success()
run: |
echo "✅ Workflow evaluation passed successfully!"
```
## Next Steps
* [Local Endpoint Testing](/offline-evals/via-sdk/agent-http/local-endpoint) - Test agents with custom HTTP endpoints
* [Endpoint on Maxim](/offline-evals/via-sdk/agent-http/endpoint-on-maxim) - Use workflows stored on the Maxim platform
# Endpoint on Maxim
Source: https://www.getmaxim.ai/docs/offline-evals/via-sdk/agent-http/endpoint-on-maxim
Learn how to test AI agents using workflows stored on the Maxim platform using the Maxim SDK
Test AI agents using workflows that are configured and stored on the Maxim platform. This approach leverages the `With Workflow ID` function to execute pre-configured workflows without needing to handle HTTP calls manually.
# HTTP Agent CI/CD Integration
Source: https://www.getmaxim.ai/docs/offline-evals/via-sdk/agent-http/ci-cd-integration
Learn how to integrate HTTP endpoint evaluations into your CI/CD pipeline using GitHub Actions
Automate your agent evaluations by integrating them into your CI/CD pipeline. This guide shows you how to use GitHub Actions with the [Maxim Actions repository](https://github.com/maximhq/actions) to test workflows automatically.
## GitHub Actions Setup
The Maxim Actions repository provides pre-built GitHub Actions that make it easy to run agent tests in your CI/CD pipeline.
### Prerequisites
Before setting up the GitHub Action, you'll need to setup the following:
1. **GitHub Secrets**: Store your Maxim API key securely
2. **GitHub Variables**: Configure your workspace and resource IDs
3. **Workflow ID**: The specific workflow ID from the Maxim platform
### Environment Setup
Add these secrets and variables to your GitHub repository:
**Secrets** (Repository Settings → Secrets and variables → Actions):
* `MAXIM_API_KEY`: Your Maxim API key
**Variables** (Repository Settings → Secrets and variables → Actions):
* `WORKSPACE_ID`: Your Maxim workspace ID
* `DATASET_ID`: The dataset to use for testing
* `WORKFLOW_ID`: The workflow ID to test
### Complete GitHub Actions Workflow
Create a file `.github/workflows/agent-evaluation.yml` in your repository:
```yaml
name: Workflow Evaluation with Maxim
on:
push:
branches: [main, dev]
pull_request:
branches: [main]
workflow_dispatch:
env:
TEST_RUN_NAME: "Workflow Evaluation - ${{ github.sha }}"
CONTEXT_TO_EVALUATE: "context"
EVALUATORS: "bias, clarity, faithfulness"
jobs:
evaluate-agent:
runs-on: ubuntu-latest
name: Run Workflow Evaluation
steps:
- name: Checkout Repository
uses: actions/checkout@v4
- name: Run Workflow Test with Maxim
id: workflow_test
uses: maximhq/actions/test-runs@v1
with:
api_key: ${{ secrets.MAXIM_API_KEY }}
workspace_id: ${{ vars.WORKSPACE_ID }}
test_run_name: ${{ env.TEST_RUN_NAME }}
dataset_id: ${{ vars.DATASET_ID }}
workflow_id: ${{ vars.WORKFLOW_ID }}
context_to_evaluate: ${{ env.CONTEXT_TO_EVALUATE }}
evaluators: ${{ env.EVALUATORS }}
- name: Display Test Results
if: always()
run: |
echo "Workflow Test Results:"
echo "${{ steps.workflow_test.outputs.test_run_result }}"
echo ""
echo "Failed Indices: ${{ steps.workflow_test.outputs.test_run_failed_indices }}"
echo ""
echo "📊 View detailed report: ${{ steps.agent_test.outputs.test_run_report_url }}"
- name: Check Test Status
if: failure()
run: |
echo "❌ Workflow evaluation failed. Check the detailed report for more information."
exit 1
- name: Success Notification
if: success()
run: |
echo "✅ Workflow evaluation passed successfully!"
```
## Next Steps
* [Local Endpoint Testing](/offline-evals/via-sdk/agent-http/local-endpoint) - Test agents with custom HTTP endpoints
* [Endpoint on Maxim](/offline-evals/via-sdk/agent-http/endpoint-on-maxim) - Use workflows stored on the Maxim platform
# Endpoint on Maxim
Source: https://www.getmaxim.ai/docs/offline-evals/via-sdk/agent-http/endpoint-on-maxim
Learn how to test AI agents using workflows stored on the Maxim platform using the Maxim SDK
Test AI agents using workflows that are configured and stored on the Maxim platform. This approach leverages the `With Workflow ID` function to execute pre-configured workflows without needing to handle HTTP calls manually.
createTestRun is the main function that creates a test run. It takes the name of the test run and the workspace id.
* withDataStructure is used to define the data structure of the dataset. It takes an object with the keys as the column names and the values as the column types.
* withData is used to specify the dataset to use for the test run. Can be a datasetId(string), a CSV file, an array of column to value mappings.
* withEvaluators is used to specify the evaluators to use/attach for the test run. You may create an evaluator locally through code or use an evaluator that is installed in your workspace through the name directly
* withPromptVersionId is used to specify the prompt version to use for the test run. It takes the id of the prompt version.
* run is used to execute the test run.
## Next Steps
Now that you've run your first prompt evaluation, explore these guides:
* [Local Prompt Testing](/offline-evals/via-sdk/prompts/local-prompt) - Learn how to test prompts with custom logic
* [Maxim Prompt Testing](/offline-evals/via-sdk/prompts/maxim-prompt) - Use prompts stored on the Maxim platform
* [Prompt Management](/offline-evals/via-sdk/prompts/prompt-management) - Retrieve and use prompts in production workflows
* [CI/CD Integration](/offline-evals/via-sdk/prompts/ci-cd-integration) - Automate prompt testing in your CI/CD pipeline
# Customized Reports
Source: https://www.getmaxim.ai/docs/offline-evals/via-ui/advanced/customized-reports
The run report is a single source of truth for you to understand exactly how your AI system is performing during your experiments or pre-release testing. You can customize reports to gain insights and make decisions.
## Toggle columns
For prompt/workflow runs, by default we only show the input from the dataset and the retrieved context (if applicable) and output from the run. However, there might be cases where you want to see other dataset columns to analyze the output. Similarly, you may want to hide some already visible columns in order to see limited data while analyzing evaluations. To show/hide columns, follow the below steps:


 ## Re-ordering columns
You can easily re-order all columns of the table by holding down the button shown in the below screenshot and dragging the column
## Re-ordering columns
You can easily re-order all columns of the table by holding down the button shown in the below screenshot and dragging the column
 ## Search and filter
In case of large reports with a lot of entries, you can use the search or filters to easily reach the relevant entries you care about. Filtering allows you to put a combination of criteria. These could be performance metrics or evaluation scores.
You can also directly filter out the results that are failing on a particular metric by clicking the filter icon next to its score in the summary card.
## Search and filter
In case of large reports with a lot of entries, you can use the search or filters to easily reach the relevant entries you care about. Filtering allows you to put a combination of criteria. These could be performance metrics or evaluation scores.
You can also directly filter out the results that are failing on a particular metric by clicking the filter icon next to its score in the summary card.

 ## Share links
Share results of runs with external stakeholders via a read-only link that can be accessed without being on the Maxim dashboard. Click the `share report` button on the header of any run report, and a link to the current view will be copied to your clipboard.
## Share links
Share results of runs with external stakeholders via a read-only link that can be accessed without being on the Maxim dashboard. Click the `share report` button on the header of any run report, and a link to the current view will be copied to your clipboard.
 # Dataset Evaluation
Source: https://www.getmaxim.ai/docs/offline-evals/via-ui/advanced/dataset-evaluation
Learn how to evaluate your AI outputs against expected results using Maxim's Dataset evaluation tools
## Get started with Dataset evaluation
Have a dataset ready directly for evaluation? Maxim lets you evaluate your AI's performance directly without setting up workflows.
# Dataset Evaluation
Source: https://www.getmaxim.ai/docs/offline-evals/via-ui/advanced/dataset-evaluation
Learn how to evaluate your AI outputs against expected results using Maxim's Dataset evaluation tools
## Get started with Dataset evaluation
Have a dataset ready directly for evaluation? Maxim lets you evaluate your AI's performance directly without setting up workflows.












Click on **"Test"** and select
 ### Example usage
Here's a typical endpoint for testing multi-turn conversations:
1. Start with a simple query:
```
User: "How old is the universe?"
AI: "The universe is estimated to be around 13.8 billion years old..."
```
2. Follow up with related questions:
```
User: "What's the Big Bang theory?"
AI: "The Big Bang theory explains the origin of the universe..."
```
By using the Messages panel effectively, you can ensure your AI endpoint handles multi-turn conversations reliably and maintains appropriate context throughout the interaction.
# HTTP Endpoint Quickstart
Source: https://www.getmaxim.ai/docs/offline-evals/via-ui/agents-via-http-endpoint/quickstart
Run your first test on an AI application via HTTP endpoint with ease, no code changes needed.
## Create a public HTTP endpoint
Connect your application's API endpoint to Maxim. Enter your API URL and add any necessary headers and parameters.
Configure the payload for your API request. Include all data your backend needs to process requests. When running tests, attach a dataset to your endpoint.
Reference column values from your dataset using `{{column_name}}` variables. These resolve during test runtime. Use variables in headers and parameters for flexible endpoint configuration.
See it in action:
### Example usage
Here's a typical endpoint for testing multi-turn conversations:
1. Start with a simple query:
```
User: "How old is the universe?"
AI: "The universe is estimated to be around 13.8 billion years old..."
```
2. Follow up with related questions:
```
User: "What's the Big Bang theory?"
AI: "The Big Bang theory explains the origin of the universe..."
```
By using the Messages panel effectively, you can ensure your AI endpoint handles multi-turn conversations reliably and maintains appropriate context throughout the interaction.
# Scripts
Source: https://www.getmaxim.ai/docs/offline-evals/via-ui/agents-via-http-endpoint/scripts
Customize your API requests and responses using Workflow scripts
Maxim Workflows provide powerful scripting capabilities to modify requests and responses. These scripts help you transform data, add authentication, and handle complex response structures.
### Example usage
Here's a typical endpoint for testing multi-turn conversations:
1. Start with a simple query:
```
User: "How old is the universe?"
AI: "The universe is estimated to be around 13.8 billion years old..."
```
2. Follow up with related questions:
```
User: "What's the Big Bang theory?"
AI: "The Big Bang theory explains the origin of the universe..."
```
By using the Messages panel effectively, you can ensure your AI endpoint handles multi-turn conversations reliably and maintains appropriate context throughout the interaction.
# HTTP Endpoint Quickstart
Source: https://www.getmaxim.ai/docs/offline-evals/via-ui/agents-via-http-endpoint/quickstart
Run your first test on an AI application via HTTP endpoint with ease, no code changes needed.
## Create a public HTTP endpoint
Connect your application's API endpoint to Maxim. Enter your API URL and add any necessary headers and parameters.
Configure the payload for your API request. Include all data your backend needs to process requests. When running tests, attach a dataset to your endpoint.
Reference column values from your dataset using `{{column_name}}` variables. These resolve during test runtime. Use variables in headers and parameters for flexible endpoint configuration.
See it in action:
### Example usage
Here's a typical endpoint for testing multi-turn conversations:
1. Start with a simple query:
```
User: "How old is the universe?"
AI: "The universe is estimated to be around 13.8 billion years old..."
```
2. Follow up with related questions:
```
User: "What's the Big Bang theory?"
AI: "The Big Bang theory explains the origin of the universe..."
```
By using the Messages panel effectively, you can ensure your AI endpoint handles multi-turn conversations reliably and maintains appropriate context throughout the interaction.
# Scripts
Source: https://www.getmaxim.ai/docs/offline-evals/via-ui/agents-via-http-endpoint/scripts
Customize your API requests and responses using Workflow scripts
Maxim Workflows provide powerful scripting capabilities to modify requests and responses. These scripts help you transform data, add authentication, and handle complex response structures.

 * For variables of type `multiselect`, configure when the deployment runs:
* all selected options are present in the deployment rule using the `=` operator, or
* any of the selected options are present in the deployment rule using the `includes` operator.
* For variables of type `multiselect`, configure when the deployment runs:
* all selected options are present in the deployment rule using the `=` operator, or
* any of the selected options are present in the deployment rule using the `includes` operator.






 In this example, the agent stopped at the Code node due to the input being a non-JSON parseable string.\
In addition, once the workflow is executed, you can view the full execution log of the node by clicking on the
In this example, the agent stopped at the Code node due to the input being a non-JSON parseable string.\
In addition, once the workflow is executed, you can view the full execution log of the node by clicking on the  In cases where a node executes multiple times due to loops, view the execution log of each iteration and in cases of errors, use it to identify the exact inputs and outputs that led to the error.
Let's take an example use case where the code checks if the input is JSON parseable or not. And here, the code block has a bug where it sends back the data to the code block to send it in an infinite loop.
In cases where a node executes multiple times due to loops, view the execution log of each iteration and in cases of errors, use it to identify the exact inputs and outputs that led to the error.
Let's take an example use case where the code checks if the input is JSON parseable or not. And here, the code block has a bug where it sends back the data to the code block to send it in an infinite loop.
 In this case, click on the
In this case, click on the  # Loops
Source: https://www.getmaxim.ai/docs/offline-evals/via-ui/agents-via-no-code-builder/loops
Rerun a part of the flow multiple times
Use loops when you need to rerun a node or part of the flow multiple times.
# Loops
Source: https://www.getmaxim.ai/docs/offline-evals/via-ui/agents-via-no-code-builder/loops
Rerun a part of the flow multiple times
Use loops when you need to rerun a node or part of the flow multiple times.
 The above example shows a simple agent that would identify the landmark in the given image and return the current weather of that location. The flow that occurs is as follows:
1. The `Prompt` node gets the initial image as an input and runs the LLM to identify the landmark.
2. The `getWeather` tool is called with the location of the landmark as input.
3. The output of the `getWeather` tool is connected back to the `Prompt` node.
4. The `Prompt` node runs again with the updated context and returns an assistant message to move the agent forward.
5. The `Final output` node gets executed and the agent completes its execution.
# Multi-agent System
Source: https://www.getmaxim.ai/docs/offline-evals/via-ui/agents-via-no-code-builder/multi-agent-system
Multi-agent systems are a powerful way to build complex applications that can handle a wide variety of tasks.
export const MaximPlayer = ({url}) => {
return ;
};
Create an intelligent workflow that can automatically understand and answer user queries related to their accounts, billings, returns or any FAQ.
The above example shows a simple agent that would identify the landmark in the given image and return the current weather of that location. The flow that occurs is as follows:
1. The `Prompt` node gets the initial image as an input and runs the LLM to identify the landmark.
2. The `getWeather` tool is called with the location of the landmark as input.
3. The output of the `getWeather` tool is connected back to the `Prompt` node.
4. The `Prompt` node runs again with the updated context and returns an assistant message to move the agent forward.
5. The `Final output` node gets executed and the agent completes its execution.
# Multi-agent System
Source: https://www.getmaxim.ai/docs/offline-evals/via-ui/agents-via-no-code-builder/multi-agent-system
Multi-agent systems are a powerful way to build complex applications that can handle a wide variety of tasks.
export const MaximPlayer = ({url}) => {
return ;
};
Create an intelligent workflow that can automatically understand and answer user queries related to their accounts, billings, returns or any FAQ.













 Create a new folder by clicking on the `+` icon on the Prompts sidebar. Give it a name. Start adding new Prompts to it via drag and drop or select the folder when creating a new Prompt.
Create a new folder by clicking on the `+` icon on the Prompts sidebar. Give it a name. Start adding new Prompts to it via drag and drop or select the folder when creating a new Prompt.
 ## Tag prompts
Tags act as custom metadata that can be used to identify and retrieve Prompts through the Maxim SDK. Add tags to a Prompt via the configuration section on the right side of the Prompt playground. Tags are simple key value pairs that can be defined and edited easily.
## Tag prompts
Tags act as custom metadata that can be used to identify and retrieve Prompts through the Maxim SDK. Add tags to a Prompt via the configuration section on the right side of the Prompt playground. Tags are simple key value pairs that can be defined and edited easily.
 Fetch relevant Prompts in your code using the SDK and querying as per tag values as shown below:
Fetch relevant Prompts in your code using the SDK and querying as per tag values as shown below:
 ## Select human evaluators while triggering a test run
On the test run configuration panel for Prompt (or HTTP endpoint), you can switch on the relevant human evaluators from the list. When you click on the `Trigger test run` button, if any human evaluators were chosen, you will see a popover to set up the human evaluation.
## Select human evaluators while triggering a test run
On the test run configuration panel for Prompt (or HTTP endpoint), you can switch on the relevant human evaluators from the list. When you click on the `Trigger test run` button, if any human evaluators were chosen, you will see a popover to set up the human evaluation.
 ## Set up human evaluation for this run
The human evaluation set requires the following choices
1. Method
* Annotate on report - Columns will be added to existing report for all editors to add ratings
* Send via email - People within or outside your organization can submit ratings. The link sent is accessible separately and does not need a paid seat on your Maxim organization.
2. If you choose to send evaluation requests via email, you need to provide the emails of the raters and instructions to be sent.
3. For email based evaluation requests to SMEs or external annotators, we make it easy to send only required entries using a sampling rate. Sampling rate can be defined in 2 ways:
* Percentage of total entries - This is relevant for large datasets where in it's not possible to manually rate all entries
* Custom logic - This helps send entries of a particular type to raters. Eg. Ratings which have a low score on the Bias metric (auto eval). By defining these rules, you can make sure to use your SME's time on the most relevant cases.
## Set up human evaluation for this run
The human evaluation set requires the following choices
1. Method
* Annotate on report - Columns will be added to existing report for all editors to add ratings
* Send via email - People within or outside your organization can submit ratings. The link sent is accessible separately and does not need a paid seat on your Maxim organization.
2. If you choose to send evaluation requests via email, you need to provide the emails of the raters and instructions to be sent.
3. For email based evaluation requests to SMEs or external annotators, we make it easy to send only required entries using a sampling rate. Sampling rate can be defined in 2 ways:
* Percentage of total entries - This is relevant for large datasets where in it's not possible to manually rate all entries
* Custom logic - This helps send entries of a particular type to raters. Eg. Ratings which have a low score on the Bias metric (auto eval). By defining these rules, you can make sure to use your SME's time on the most relevant cases.
 ## Collect ratings via test report columns
All editors can add human annotations to the test report directly. Clicking on `select rating` button in the relevant evaluator column. A popover will show with all the evaluators that need ratings. Add comments for each rating. In case the output is not upto the mark, submit a re-written output.
## Collect ratings via test report columns
All editors can add human annotations to the test report directly. Clicking on `select rating` button in the relevant evaluator column. A popover will show with all the evaluators that need ratings. Add comments for each rating. In case the output is not upto the mark, submit a re-written output.
 If one rater has already provided ratings, a different rater can still add their inputs. Hover on the row to reveal a button near the previous value. Add ratings via the popover as mentioned above. Average rating across raters will be shown for that evaluator and considered for the overall results calculations.
If one rater has already provided ratings, a different rater can still add their inputs. Hover on the row to reveal a button near the previous value. Add ratings via the popover as mentioned above. Average rating across raters will be shown for that evaluator and considered for the overall results calculations.
 ## Collect ratings via email
On completion of the test run, emails are sent to all raters provided during set up. This email will contain the requester name and instructions along with the link to the rater dashboard.
## Collect ratings via email
On completion of the test run, emails are sent to all raters provided during set up. This email will contain the requester name and instructions along with the link to the rater dashboard.

 ## Analyze human ratings
Once all entries are completed by a rater, the summary scores and pass/fail results for the human ratings are shown along side all other auto evaluation results in the test run report. The human annotation section will show a `Completed` status next to this rater's email. To view the detailed ratings by a particular individual, click the `View details` button and go through the table provided.
## Analyze human ratings
Once all entries are completed by a rater, the summary scores and pass/fail results for the human ratings are shown along side all other auto evaluation results in the test run report. The human annotation section will show a `Completed` status next to this rater's email. To view the detailed ratings by a particular individual, click the `View details` button and go through the table provided.
 If there are particular cases where you would like to use the human corrected output to build ground truth in your datasets, you can use the [data curation flows.](/library/datasets/curate-datasets)
# MCP (Model Context Protocol)
Source: https://www.getmaxim.ai/docs/offline-evals/via-ui/prompts/mcp
Learn how to use MCP to test your prompts
export const MaximPlayer = ({url}) => {
return ;
};
If there are particular cases where you would like to use the human corrected output to build ground truth in your datasets, you can use the [data curation flows.](/library/datasets/curate-datasets)
# MCP (Model Context Protocol)
Source: https://www.getmaxim.ai/docs/offline-evals/via-ui/prompts/mcp
Learn how to use MCP to test your prompts
export const MaximPlayer = ({url}) => {
return ;
};
Composio client.
Settings → MCP Clients and click Add new client.

Prompts. You will find all the tools you have set up under Prompt Tools.



 * For variables of type `multiselect`, configure when the deployment runs:
* all selected options are present in the deployment rule using the `=` operator, or
* any of the selected options are present in the deployment rule using the `includes` operator.
* For variables of type `multiselect`, configure when the deployment runs:
* all selected options are present in the deployment rule using the `=` operator, or
* any of the selected options are present in the deployment rule using the `includes` operator.

















 ## Adding system and user prompts
In the prompt editor, add your system and user prompts. The system prompt sets the context or instructions for the AI, while the user prompt represents the input you want the AI to respond to. Use the `Add message` button to append messages in the conversations before running it. Mimic assistant responses for debugging using the `assistant` type message.
## Adding system and user prompts
In the prompt editor, add your system and user prompts. The system prompt sets the context or instructions for the AI, while the user prompt represents the input you want the AI to respond to. Use the `Add message` button to append messages in the conversations before running it. Mimic assistant responses for debugging using the `assistant` type message.


 ### Prompt comparison
Prompt comparison combines multiple single Prompts into one view, enabling a streamlined approach for various workflows:
1. **Model comparison**: Evaluate the performance of different models on the same Prompt.
2. **Prompt optimization**: Compare different versions of a Prompt to identify the most effective formulation.
3. **Cross-Model consistency**: Ensure consistent outputs across various models for the same Prompt.
4. **Performance benchmarking**: Analyze metrics like latency, cost, and token count across different models and Prompts.
### Prompt comparison
Prompt comparison combines multiple single Prompts into one view, enabling a streamlined approach for various workflows:
1. **Model comparison**: Evaluate the performance of different models on the same Prompt.
2. **Prompt optimization**: Compare different versions of a Prompt to identify the most effective formulation.
3. **Cross-Model consistency**: Ensure consistent outputs across various models for the same Prompt.
4. **Performance benchmarking**: Analyze metrics like latency, cost, and token count across different models and Prompts.

 * If disabled, the same input is taken for all the Prompts in the comparison.
* If disabled, the same input is taken for all the Prompts in the comparison.
 ### Open an existing Prompt Comparison
Whenever you save a session in when comparing Prompts, a session gets saved in the base Prompt. You can access this anytime via the sessions drop down of that Prompt, marked with a `Comparison` badge.
### Open an existing Prompt Comparison
Whenever you save a session in when comparing Prompts, a session gets saved in the base Prompt. You can access this anytime via the sessions drop down of that Prompt, marked with a `Comparison` badge.

 * View the list of recent sessions by clicking on the arrow next to the `save session` button and see complete list using the button at the bottom of this list.
* View the list of recent sessions by clicking on the arrow next to the `save session` button and see complete list using the button at the bottom of this list.
 * To make organization and recall easier, tag your sessions by clicking the `tag` icon that shows on hover of a session list item. Add a name that provides information to other team members about the use of that session.
* To make organization and recall easier, tag your sessions by clicking the `tag` icon that shows on hover of a session list item. Add a name that provides information to other team members about the use of that session.



































 # Set Up Alerts and Notifications
Source: https://www.getmaxim.ai/docs/online-evals/set-up-alerts-and-notifications
Learn how to configure notification channels (Slack and PagerDuty) and set up alerts to monitor your AI application's performance and quality metrics.
Maxim provides a comprehensive alerting system that combines powerful notification channels with flexible alert configurations. Set up Slack or PagerDuty integrations to receive real-time notifications when your AI application's performance metrics or quality scores exceed specified thresholds.
## Notification Channels
Maxim supports multiple notification channels to ensure you stay informed about your alerts. Currently, we support [Slack](/integrations/create-a-slack-integration) and [PagerDuty](/integrations/create-a-pagerduty-integration) integrations.
# Set Up Alerts and Notifications
Source: https://www.getmaxim.ai/docs/online-evals/set-up-alerts-and-notifications
Learn how to configure notification channels (Slack and PagerDuty) and set up alerts to monitor your AI application's performance and quality metrics.
Maxim provides a comprehensive alerting system that combines powerful notification channels with flexible alert configurations. Set up Slack or PagerDuty integrations to receive real-time notifications when your AI application's performance metrics or quality scores exceed specified thresholds.
## Notification Channels
Maxim supports multiple notification channels to ensure you stay informed about your alerts. Currently, we support [Slack](/integrations/create-a-slack-integration) and [PagerDuty](/integrations/create-a-pagerduty-integration) integrations.
 > As per the image above, we can see that the evaluator needs `input`, `context` and `expectedOutput` variables.
### Attaching evaluators via Maxim SDK
We use the `withEvaluators` method to attach evaluators to any component within a trace or the trace itself. It is as easy as just listing the names of the evaluators you want to attach, which are available on the platform.
> As per the image above, we can see that the evaluator needs `input`, `context` and `expectedOutput` variables.
### Attaching evaluators via Maxim SDK
We use the `withEvaluators` method to attach evaluators to any component within a trace or the trace itself. It is as easy as just listing the names of the evaluators you want to attach, which are available on the platform.
 ## Code example for agentic evaluation
This example displays how Node level evaluation might fit in a workflow.
## Code example for agentic evaluation
This example displays how Node level evaluation might fit in a workflow.

Setup evaluation configuration
Create annotation queue

 Click the trace to view detailed evaluation results. In the sheet, you will find the `Evaluation` tab, wherein you can see the evaluation in detail.
Click the trace to view detailed evaluation results. In the sheet, you will find the `Evaluation` tab, wherein you can see the evaluation in detail.
 The evaluation tab displays many details regarding the evaluation of the trace, let us see how you can navigate through them and get more insights into how your LLM is performing.
### Evaluation summary
The evaluation tab displays many details regarding the evaluation of the trace, let us see how you can navigate through them and get more insights into how your LLM is performing.
### Evaluation summary
 Evaluation summary displays the following information (top to bottom, left to right):
* How many evaluators passed out of the total evaluators across the trace
* How much did all the evaluators' evaluation cost
* How many tokens were used across the all evaluators' evaluations
* What was the total time taken for the evaluation to process
### Trace evaluation card
In each card, you will find a tab switcher on the top right corner, this is used to navigate through the evaluation's details. Here is what you can find in in different tabs:
#### Overview tab
Evaluation summary displays the following information (top to bottom, left to right):
* How many evaluators passed out of the total evaluators across the trace
* How much did all the evaluators' evaluation cost
* How many tokens were used across the all evaluators' evaluations
* What was the total time taken for the evaluation to process
### Trace evaluation card
In each card, you will find a tab switcher on the top right corner, this is used to navigate through the evaluation's details. Here is what you can find in in different tabs:
#### Overview tab
 All the evaluators run on the trace level and their scores are displayed in a table here along with whether the evaluator passed or failed.
#### Individual evaluator's tab
All the evaluators run on the trace level and their scores are displayed in a table here along with whether the evaluator passed or failed.
#### Individual evaluator's tab
 This tab contains the following sections:
* **Result**: Shows whether the evaluator passed or failed.
* **Score**: Shows the score of the evaluator.
* **Reason** (shown where applicable): Displays the reasoning behind the score of the evaluator, if given.
* **Cost** (shown where applicable): Shows the cost of the individual evaluator's evaluation.
* **Tokens used** (shown where applicable): Shows the number of tokens used by the individual evaluator's evaluation.
* **Model latency** (shown where applicable): Shows the time taken by the model to respond back with a result for an evaluator.
* **Time taken**: Shows the time taken by the evaluator to evaluate.
* **Variables used to evaluate**: Shows the values that were used to replace the variables with while processing the evaluator.
* **Logs**: These are logs that were generated during the evaluation process. They might be useful for debugging errors or issues that occurred during the evaluation.
### Tree view on the left panel
This tab contains the following sections:
* **Result**: Shows whether the evaluator passed or failed.
* **Score**: Shows the score of the evaluator.
* **Reason** (shown where applicable): Displays the reasoning behind the score of the evaluator, if given.
* **Cost** (shown where applicable): Shows the cost of the individual evaluator's evaluation.
* **Tokens used** (shown where applicable): Shows the number of tokens used by the individual evaluator's evaluation.
* **Model latency** (shown where applicable): Shows the time taken by the model to respond back with a result for an evaluator.
* **Time taken**: Shows the time taken by the evaluator to evaluate.
* **Variables used to evaluate**: Shows the values that were used to replace the variables with while processing the evaluator.
* **Logs**: These are logs that were generated during the evaluation process. They might be useful for debugging errors or issues that occurred during the evaluation.
### Tree view on the left panel
 This view is essential for when you are evaluating the each log on the node level, essentially on each component of the trace (like a generation or retrieval, etc). This view helps with your perception as to what component's evaluation you are looking at on the right panel (and the component's place in the trace as well). We discuss more about the [Node Level Evaluation](/online-evals/via-sdk/node-level-evaluation) further down.
## Dataset curation
Once you have logs and evaluations in Maxim, you can easily curate datasets by filtering and selecting logs based on different criteria.
This view is essential for when you are evaluating the each log on the node level, essentially on each component of the trace (like a generation or retrieval, etc). This view helps with your perception as to what component's evaluation you are looking at on the right panel (and the component's place in the trace as well). We discuss more about the [Node Level Evaluation](/online-evals/via-sdk/node-level-evaluation) further down.
## Dataset curation
Once you have logs and evaluations in Maxim, you can easily curate datasets by filtering and selecting logs based on different criteria.




Setup evaluation configuration
Create annotation queue

 Here we will see a `Set up queue logic` button, click on it to setup the logic for the queue and click on the `Save queue logic` button finally to save.
Here we will see a `Set up queue logic` button, click on it to setup the logic for the queue and click on the `Save queue logic` button finally to save.


 #### Annotating the logs
On opening the annotation queue page, you will see a list of logs that have been added to the queue beside which there will be a **Select rating** dropdown.
Clicking on the **Select rating** dropdown will open a modal where you can select a rating for the log and optionally add a comment or provide a rewritten output if necessary.
#### Annotating the logs
On opening the annotation queue page, you will see a list of logs that have been added to the queue beside which there will be a **Select rating** dropdown.
Clicking on the **Select rating** dropdown will open a modal where you can select a rating for the log and optionally add a comment or provide a rewritten output if necessary.
 You can also click on one of the entries to open annotation sheet, wherein you can see the complete input and output and rate for all the evaluators in each entry at once.
After scoring an entry, click on the `Save and next`
You can also click on one of the entries to open annotation sheet, wherein you can see the complete input and output and rate for all the evaluators in each entry at once.
After scoring an entry, click on the `Save and next`  ### The logs table
Similar to how the evaluator scores are shown for auto evaluation, human evaluators are also shown (again, the average score is shown here)
### The logs table
Similar to how the evaluator scores are shown for auto evaluation, human evaluators are also shown (again, the average score is shown here)
 ### The trace details sheet (under the Evaluation tab)
On opening any trace, you will find a `Details` and `Evaluation` tab. The `Evaluation` tab here would display all the evaluations on that happened on the trace. We will focus on the **Human Evaluators** here but in order to make sense of other evaluators in this sheet you can refer to [Auto Evaluation -> Making sense of evaluations on logs](/online-evals/via-ui/set-up-auto-evaluation-on-logs#making-sense-of-evaluations-on-logs)
The trace evaluation overview tab shows the average score of each **Human Evaluator** and **Rewritten Outputs**, if present, by each individual user.
### The trace details sheet (under the Evaluation tab)
On opening any trace, you will find a `Details` and `Evaluation` tab. The `Evaluation` tab here would display all the evaluations on that happened on the trace. We will focus on the **Human Evaluators** here but in order to make sense of other evaluators in this sheet you can refer to [Auto Evaluation -> Making sense of evaluations on logs](/online-evals/via-ui/set-up-auto-evaluation-on-logs#making-sense-of-evaluations-on-logs)
The trace evaluation overview tab shows the average score of each **Human Evaluator** and **Rewritten Outputs**, if present, by each individual user.
 Going further into each individual **Human Evaluator**, we see its `Score` (avg.) and `Result` (whether the particular evaluator's evaluation passed or failed). We also see a breakdown of the scores and their corresponding comments, if any, given by each user in this tab, thus giving you a granular view of the evaluation as well.
Going further into each individual **Human Evaluator**, we see its `Score` (avg.) and `Result` (whether the particular evaluator's evaluation passed or failed). We also see a breakdown of the scores and their corresponding comments, if any, given by each user in this tab, thus giving you a granular view of the evaluation as well.
 # Get Prompt Config
Source: https://www.getmaxim.ai/docs/prompts/prompt-config/get-prompt-config
public-apis/openapi/prompts.json get /v1/prompts/config
Get prompt configuration
# Update Prompt Config
Source: https://www.getmaxim.ai/docs/prompts/prompt-config/update-prompt-config
public-apis/openapi/prompts.json put /v1/prompts/config
Update prompt configuration
# Deploy Prompt Version
Source: https://www.getmaxim.ai/docs/prompts/prompt-deployment/deploy-prompt-version
public-apis/openapi/prompts.json post /v1/prompts/deploy
Deploy a prompt version
# Create a prompt version
Source: https://www.getmaxim.ai/docs/prompts/prompt-version/create-a-prompt-version
public-apis/openapi/prompts.json post /v1/prompts/versions
Create a prompt version
# Get Prompt Versions
Source: https://www.getmaxim.ai/docs/prompts/prompt-version/get-prompt-versions
public-apis/openapi/prompts.json get /v1/prompts/versions
Get versions of a prompt
# Run Prompt Version
Source: https://www.getmaxim.ai/docs/prompts/prompt-version/run-prompt-version
public-apis/openapi/prompts.json post /v1/prompts/run
Run a specific version of a prompt
# Create Prompt
Source: https://www.getmaxim.ai/docs/prompts/prompt/create-prompt
public-apis/openapi/prompts.json post /v1/prompts
Create a new prompt
# Delete Prompt
Source: https://www.getmaxim.ai/docs/prompts/prompt/delete-prompt
public-apis/openapi/prompts.json delete /v1/prompts
Delete a prompt
# Get Prompts
Source: https://www.getmaxim.ai/docs/prompts/prompt/get-prompts
public-apis/openapi/prompts.json get /v1/prompts
Get prompts for a workspace
# Update Prompt
Source: https://www.getmaxim.ai/docs/prompts/prompt/update-prompt
public-apis/openapi/prompts.json put /v1/prompts
Update an existing prompt
# API Reference Overview
Source: https://www.getmaxim.ai/docs/public-apis/overview
Welcome to the Maxim API documentation. This guide provides comprehensive information about our available APIs, their endpoints, and how to use them.
## Available APIs
Maxim offers several specialized APIs to help you integrate with our platform:
| API | Description |
| ----------------------------- | ---------------------------------------------------------- |
| **Prompts API** | Manage AI prompts and templates |
| **Alerts API** | Configure and manage alert notifications |
| **Integrations API** | Connect Maxim with external services like Slack, Pagerduty |
| **Log Repositories API** | Manage log storage and organization |
| **Test Runs API** | Create and manage test execution workflows |
| **Test Run Share Report API** | Generate and share test results |
| **Test Run Entries API** | Access detailed test execution data |
| **Logs API** | Query and analyze log data |
| **Datasets API** | Manage training and evaluation datasets |
| **Evaluators API** | Get evaluator details and execute evaluators |
## Authentication
All API requests require authentication using API keys.
Include your API key in the request headers using the `x-maxim-api-key` header:
# Introduction
Source: https://www.getmaxim.ai/docs/sdk/overview
Dive into the Maxim SDK to supercharge your AI application development
Maxim is a comprehensive platform designed to streamline AI application evaluation and observability. It offers a suite of tools and services that help developers and teams apply traditional software best practices to non-deterministic AI workflows.
Maxim SDK exposes Maxim's most critical functionalities behind a simple set of function calls, allowing developers to integrate Maxim workflows into their own workflows seamlessly.
## Language and framework support
| Language | SDK Link | Package installer command |
| -------------------- | --------------------------------------------------------------------- | ----------------------------------------- |
| Python | [PyPI](https://pypi.org/project/maxim-py/) | `pip install maxim-py` |
| JavaScript | [npm](https://www.npmjs.com/package/@maximai/maxim-js) | `npm install @maximai/maxim-js` |
| Javascript Langchain | [npm](https://www.npmjs.com/package/@maximai/maxim-js-langchain) | `npm install @maximai/maxim-js-langchain` |
| Go | [Go SDK](https://github.com/maximhq/maxim-go) | `go get github.com/maximhq/maxim-go` |
| Java/JVM | [Java/JVM SDK](https://central.sonatype.com/artifact/ai.getmaxim/sdk) | `implementation("ai.getmaxim:sdk:0.1.3")` |
## Initializing SDK
## Troubleshooting
### Common Issues
* **No traces appearing**: Ensure your API key and repository ID are correct
* Ensure you've **`called instrument_agno()`** ***before*** running your agents. This initializes logging hooks correctly.
* Set `debug=True` in your `instrument_agno()` call to surface any internal errors:
```python
instrument_agno(logger, {"debug" : True})
```
* Double-check that `instrument_agno()` is called **before** creating or executing agents. This might be obvious, but it's a common oversight.
### Debug Mode
Enable debug mode to see detailed logging information:
```python
from maxim import Maxim
from maxim.logger.agno import instrument_agno
# Enable debug mode
maxim = Maxim()
instrument_agno(maxim.logger(), {"debug":True})
```
## Resources
## Resources
# Get Prompt Config
Source: https://www.getmaxim.ai/docs/prompts/prompt-config/get-prompt-config
public-apis/openapi/prompts.json get /v1/prompts/config
Get prompt configuration
# Update Prompt Config
Source: https://www.getmaxim.ai/docs/prompts/prompt-config/update-prompt-config
public-apis/openapi/prompts.json put /v1/prompts/config
Update prompt configuration
# Deploy Prompt Version
Source: https://www.getmaxim.ai/docs/prompts/prompt-deployment/deploy-prompt-version
public-apis/openapi/prompts.json post /v1/prompts/deploy
Deploy a prompt version
# Create a prompt version
Source: https://www.getmaxim.ai/docs/prompts/prompt-version/create-a-prompt-version
public-apis/openapi/prompts.json post /v1/prompts/versions
Create a prompt version
# Get Prompt Versions
Source: https://www.getmaxim.ai/docs/prompts/prompt-version/get-prompt-versions
public-apis/openapi/prompts.json get /v1/prompts/versions
Get versions of a prompt
# Run Prompt Version
Source: https://www.getmaxim.ai/docs/prompts/prompt-version/run-prompt-version
public-apis/openapi/prompts.json post /v1/prompts/run
Run a specific version of a prompt
# Create Prompt
Source: https://www.getmaxim.ai/docs/prompts/prompt/create-prompt
public-apis/openapi/prompts.json post /v1/prompts
Create a new prompt
# Delete Prompt
Source: https://www.getmaxim.ai/docs/prompts/prompt/delete-prompt
public-apis/openapi/prompts.json delete /v1/prompts
Delete a prompt
# Get Prompts
Source: https://www.getmaxim.ai/docs/prompts/prompt/get-prompts
public-apis/openapi/prompts.json get /v1/prompts
Get prompts for a workspace
# Update Prompt
Source: https://www.getmaxim.ai/docs/prompts/prompt/update-prompt
public-apis/openapi/prompts.json put /v1/prompts
Update an existing prompt
# API Reference Overview
Source: https://www.getmaxim.ai/docs/public-apis/overview
Welcome to the Maxim API documentation. This guide provides comprehensive information about our available APIs, their endpoints, and how to use them.
## Available APIs
Maxim offers several specialized APIs to help you integrate with our platform:
| API | Description |
| ----------------------------- | ---------------------------------------------------------- |
| **Prompts API** | Manage AI prompts and templates |
| **Alerts API** | Configure and manage alert notifications |
| **Integrations API** | Connect Maxim with external services like Slack, Pagerduty |
| **Log Repositories API** | Manage log storage and organization |
| **Test Runs API** | Create and manage test execution workflows |
| **Test Run Share Report API** | Generate and share test results |
| **Test Run Entries API** | Access detailed test execution data |
| **Logs API** | Query and analyze log data |
| **Datasets API** | Manage training and evaluation datasets |
| **Evaluators API** | Get evaluator details and execute evaluators |
## Authentication
All API requests require authentication using API keys.
Include your API key in the request headers using the `x-maxim-api-key` header:
# Introduction
Source: https://www.getmaxim.ai/docs/sdk/overview
Dive into the Maxim SDK to supercharge your AI application development
Maxim is a comprehensive platform designed to streamline AI application evaluation and observability. It offers a suite of tools and services that help developers and teams apply traditional software best practices to non-deterministic AI workflows.
Maxim SDK exposes Maxim's most critical functionalities behind a simple set of function calls, allowing developers to integrate Maxim workflows into their own workflows seamlessly.
## Language and framework support
| Language | SDK Link | Package installer command |
| -------------------- | --------------------------------------------------------------------- | ----------------------------------------- |
| Python | [PyPI](https://pypi.org/project/maxim-py/) | `pip install maxim-py` |
| JavaScript | [npm](https://www.npmjs.com/package/@maximai/maxim-js) | `npm install @maximai/maxim-js` |
| Javascript Langchain | [npm](https://www.npmjs.com/package/@maximai/maxim-js-langchain) | `npm install @maximai/maxim-js-langchain` |
| Go | [Go SDK](https://github.com/maximhq/maxim-go) | `go get github.com/maximhq/maxim-go` |
| Java/JVM | [Java/JVM SDK](https://central.sonatype.com/artifact/ai.getmaxim/sdk) | `implementation("ai.getmaxim:sdk:0.1.3")` |
## Initializing SDK
## Troubleshooting
### Common Issues
* **No traces appearing**: Ensure your API key and repository ID are correct
* Ensure you've **`called instrument_agno()`** ***before*** running your agents. This initializes logging hooks correctly.
* Set `debug=True` in your `instrument_agno()` call to surface any internal errors:
```python
instrument_agno(logger, {"debug" : True})
```
* Double-check that `instrument_agno()` is called **before** creating or executing agents. This might be obvious, but it's a common oversight.
### Debug Mode
Enable debug mode to see detailed logging information:
```python
from maxim import Maxim
from maxim.logger.agno import instrument_agno
# Enable debug mode
maxim = Maxim()
instrument_agno(maxim.logger(), {"debug":True})
```
## Resources
## Resources



Evaluate captured logs automatically from the UI based on filters and sampling
Use human evaluation or rating to assess the quality of your logs and evaluate them.
Evaluate any component of your trace or log to gain insights into your agent’s behavior.

 ## Troubleshooting
### Common Issues
* **No traces appearing**: Ensure your API key and repository ID are correc
* Ensure you've **`called instrument_crewai()`** ***before*** running your crew. This initializes logging hooks correctly.
* Set `debug=True` in your `instrument_crewai()` call to surface any internal errors:
```python
instrument_crewai(logger, debug=True)
```
* Configure your agents with `verbose=True` to capture detailed logs:
```python
agent = CrewAgent(..., verbose=True)
```
* Double-check that `instrument_crewai()` is called **before** creating or executing agents. This might be obvious, but it's a common oversight.
## Resources
## Troubleshooting
### Common Issues
* **No traces appearing**: Ensure your API key and repository ID are correc
* Ensure you've **`called instrument_crewai()`** ***before*** running your crew. This initializes logging hooks correctly.
* Set `debug=True` in your `instrument_crewai()` call to surface any internal errors:
```python
instrument_crewai(logger, debug=True)
```
* Configure your agents with `verbose=True` to capture detailed logs:
```python
agent = CrewAgent(..., verbose=True)
```
* Double-check that `instrument_crewai()` is called **before** creating or executing agents. This might be obvious, but it's a common oversight.
## Resources
 ## Resources
## Resources
## Resources
## Resources
 ## Resources
## Resources
 ***
## Resources
***
## Resources
 #### OpenAI API Key
1. Go to OpenAI Platform & create an API Key [OpenAI Platform](https://platform.openai.com/api-keys)
2. Set the `OPENAI_API_KEY` environment variable
### Step 2: Initialize Maxim Logger
```python {21}
import logging
from maxim import Maxim
from maxim.logger.livekit import instrument_livekit
# Initialize Maxim logger
logger = Maxim().logger()
# Automatically fetches MAXIM_API_KEY and MAXIM_LOG_REPO_ID from environment variables
# Optional: Set up event handling for trace lifecycle
def on_event(event: str, data: dict):
if event == "maxim.trace.started":
trace_id = data["trace_id"]
trace = data["trace"]
logging.info(f"Trace started - ID: {trace_id}")
elif event == "maxim.trace.ended":
trace_id = data["trace_id"]
trace = data["trace"]
logging.info(f"Trace ended - ID: {trace_id}")
# Instrument LiveKit with Maxim observability
instrument_livekit(logger, on_event)
```
`instrument_livekit`: This function integrates Maxim's observability features with LiveKit Agents . It allows you to automatically capture and send trace data to the platform:
`logger = Maxim().logger()` : This creates a Maxim logger instance that:
* Connects to your Maxim project using the `MAXIM_API_KEY` and `MAXIM_LOG_REPO_ID` environment variables
* Handles sending trace data to the Maxim platform
* Provides the logging interface for capturing events, metrics, and traces
`on_event` : This is a **callback function** that gets triggered during trace lifecycle events:
* `event`: A string indicating what happened (`"maxim.trace.started"` or `"maxim.trace.ended"`)
* `data`: A dictionary containing trace information:
* `trace_id`: Unique identifier for the trace
* `trace`: The actual trace object with metadata, timing, and other details
**What it does:**
* When a new conversation or interaction starts → logs "Trace started"
* When a conversation or interaction ends → logs "Trace ended"
* Useful for debugging and monitoring trace lifecycle in real-time
### Step 3: Create Your Voice Agent
```python
import os
import uuid
import dotenv
from livekit import agents
from livekit import api as livekit_api
from livekit.agents import Agent, AgentSession, function_tool
from livekit.api.room_service import CreateRoomRequest
from livekit.plugins import google
dotenv.load_dotenv(override=True)
class Assistant(Agent):
def __init__(self) -> None:
super().__init__(
instructions="You are a helpful voice AI assistant. You can search the web using the web_search tool."
)
@function_tool()
async def web_search(self, query: str) -> str:
"""
Performs a web search for the given query.
Args:
query: The search query string
Returns:
Search results as a formatted string
"""
# Your web search implementation here
return f"Search results for: {query}"
async def entrypoint(ctx: agents.JobContext):
# Generate or use predefined room name
room_name = os.getenv("LIVEKIT_ROOM_NAME") or f"assistant-room-{uuid.uuid4().hex}"
# Initialize LiveKit API client
lkapi = livekit_api.LiveKitAPI(
url=os.getenv("LIVEKIT_URL"),
api_key=os.getenv("LIVEKIT_API_KEY"),
api_secret=os.getenv("LIVEKIT_API_SECRET"),
)
try:
# Create room with configuration
req = CreateRoomRequest(
name=room_name,
empty_timeout=300, # Keep room alive 5 minutes after empty
max_participants=10, # Adjust based on your needs
)
room = await lkapi.room.create_room(req)
print(f"Room created: {room.name}")
# Create agent session with Gemini model
session = AgentSession(
llm=openai.realtime.RealtimeModel(voice="coral"),
)
# Start the session
await session.start(room=room, agent=Assistant())
await ctx.connect()
# Generate initial greeting
await session.generate_reply(
instructions="Greet the user and offer your assistance."
)
finally:
await lkapi.aclose()
# Run the agent
if __name__ == "__main__":
opts = agents.WorkerOptions(entrypoint_fnc=entrypoint)
agents.cli.run_app(opts)
```
This code -
**Creates a custom agent class:**
* Inherits from `Agent`: Base class for all LiveKit agents
* `instructions`: System prompt that defines the agent's personality and capabilities
* **Tells the agent**: It's a voice assistant that can use web search
**Creates a callable tool:**
* `@function_tool()`: Decorator that registers this method as a tool the agent can call
* `async def`: Asynchronous function (required for LiveKit agents)
* **Type hints**: `query: str -> str` helps the AI understand input/output types
* **Docstring**: Describes the function for the AI model
* **Current implementation**: Placeholder that returns a formatted string
**The main function that runs when the agent starts:**
* `ctx: agents.JobContext`: Contains information about the current job/session
**Creates a unique room name:**
* **First tries**: Environment variable `LIVEKIT_ROOM_NAME`
* **Falls back to**: Generated name like `assistant-room-a1b2c3d4e5f6...`
* `uuid.uuid4().hex`: Creates a random hexadecimal string
**Starts the agent and begins conversation:**
* `session.start()`: Connects the agent to the room
* `agent=Assistant()`: Uses your custom Assistant class
* `ctx.connect()`: Connects to the LiveKit infrastructure
* `generate_reply()`: Makes the agent speak first with a greeting
## Complete Example with Web Search
Here's a complete example that includes web search functionality using Tavily:
```python
import logging
import os
import uuid
import dotenv
from livekit import agents
from livekit import api as livekit_api
from livekit.agents import Agent, AgentSession, function_tool
from livekit.api.room_service import CreateRoomRequest
from livekit.plugins import google
from maxim import Maxim
from maxim.logger.livekit import instrument_livekit
from tavily import TavilyClient
dotenv.load_dotenv(override=True)
logging.basicConfig(level=logging.INFO)
# Initialize Maxim observability
logger = Maxim().logger()
TAVILY_API_KEY = os.getenv("TAVILY_API_KEY")
def on_event(event: str, data: dict):
if event == "maxim.trace.started":
trace_id = data["trace_id"]
trace = data["trace"]
logging.info(f"Trace started - ID: {trace_id}")
elif event == "maxim.trace.ended":
trace_id = data["trace_id"]
trace = data["trace"]
logging.info(f"Trace ended - ID: {trace_id}")
# Instrument LiveKit with Maxim
instrument_livekit(logger, on_event)
class Assistant(Agent):
def __init__(self) -> None:
super().__init__(
instructions="You are a helpful voice AI assistant. You can search the web using the web_search tool."
)
@function_tool()
async def web_search(self, query: str) -> str:
"""
Performs a web search for the given query.
Args:
query: The search query string
Returns:
Search results as a formatted string
"""
if not TAVILY_API_KEY:
return "Web search is not available. Please configure the Tavily API key."
tavily_client = TavilyClient(api_key=TAVILY_API_KEY)
try:
response = tavily_client.search(query=query, search_depth="basic")
if response.get('answer'):
return response['answer']
return str(response.get('results', 'No results found.'))
except Exception as e:
return f"An error occurred during web search: {e}"
async def entrypoint(ctx: agents.JobContext):
room_name = os.getenv("LIVEKIT_ROOM_NAME") or f"assistant-room-{uuid.uuid4().hex}"
lkapi = livekit_api.LiveKitAPI(
url=os.getenv("LIVEKIT_URL"),
api_key=os.getenv("LIVEKIT_API_KEY"),
api_secret=os.getenv("LIVEKIT_API_SECRET"),
)
try:
req = CreateRoomRequest(
name=room_name,
empty_timeout=300,
max_participants=10,
)
room = await lkapi.room.create_room(req)
print(f"Room created: {room.name}")
session = AgentSession(
llm=openai.realtime.RealtimeModel(voice="coral"),
)
await session.start(room=room, agent=Assistant())
await ctx.connect()
await session.generate_reply(
instructions="Greet the user and offer your assistance."
)
finally:
await lkapi.aclose()
if __name__ == "__main__":
opts = agents.WorkerOptions(entrypoint_fnc=entrypoint)
agents.cli.run_app(opts)
```
## What Gets Traced
### Agent Conversations
Transcript containing System Instructions, User and Assistant Messages are pushed to Maxim
## Running Your Agent
1. Working code is uploaded here - [https://github.com/maximhq/maxim-cookbooks/blob/main/python/observability-online-eval/livekit/livekit-gemini.py](https://github.com/maximhq/maxim-cookbooks/blob/main/python/observability-online-eval/livekit/livekit-gemini.py)
2. **Start your LiveKit server** (if self-hosting) or ensure your LiveKit Cloud instance is running
3. **Run your agent**:
```bash
uv sync
uv run livekit-gemini.py console
```
#### OpenAI API Key
1. Go to OpenAI Platform & create an API Key [OpenAI Platform](https://platform.openai.com/api-keys)
2. Set the `OPENAI_API_KEY` environment variable
### Step 2: Initialize Maxim Logger
```python {21}
import logging
from maxim import Maxim
from maxim.logger.livekit import instrument_livekit
# Initialize Maxim logger
logger = Maxim().logger()
# Automatically fetches MAXIM_API_KEY and MAXIM_LOG_REPO_ID from environment variables
# Optional: Set up event handling for trace lifecycle
def on_event(event: str, data: dict):
if event == "maxim.trace.started":
trace_id = data["trace_id"]
trace = data["trace"]
logging.info(f"Trace started - ID: {trace_id}")
elif event == "maxim.trace.ended":
trace_id = data["trace_id"]
trace = data["trace"]
logging.info(f"Trace ended - ID: {trace_id}")
# Instrument LiveKit with Maxim observability
instrument_livekit(logger, on_event)
```
`instrument_livekit`: This function integrates Maxim's observability features with LiveKit Agents . It allows you to automatically capture and send trace data to the platform:
`logger = Maxim().logger()` : This creates a Maxim logger instance that:
* Connects to your Maxim project using the `MAXIM_API_KEY` and `MAXIM_LOG_REPO_ID` environment variables
* Handles sending trace data to the Maxim platform
* Provides the logging interface for capturing events, metrics, and traces
`on_event` : This is a **callback function** that gets triggered during trace lifecycle events:
* `event`: A string indicating what happened (`"maxim.trace.started"` or `"maxim.trace.ended"`)
* `data`: A dictionary containing trace information:
* `trace_id`: Unique identifier for the trace
* `trace`: The actual trace object with metadata, timing, and other details
**What it does:**
* When a new conversation or interaction starts → logs "Trace started"
* When a conversation or interaction ends → logs "Trace ended"
* Useful for debugging and monitoring trace lifecycle in real-time
### Step 3: Create Your Voice Agent
```python
import os
import uuid
import dotenv
from livekit import agents
from livekit import api as livekit_api
from livekit.agents import Agent, AgentSession, function_tool
from livekit.api.room_service import CreateRoomRequest
from livekit.plugins import google
dotenv.load_dotenv(override=True)
class Assistant(Agent):
def __init__(self) -> None:
super().__init__(
instructions="You are a helpful voice AI assistant. You can search the web using the web_search tool."
)
@function_tool()
async def web_search(self, query: str) -> str:
"""
Performs a web search for the given query.
Args:
query: The search query string
Returns:
Search results as a formatted string
"""
# Your web search implementation here
return f"Search results for: {query}"
async def entrypoint(ctx: agents.JobContext):
# Generate or use predefined room name
room_name = os.getenv("LIVEKIT_ROOM_NAME") or f"assistant-room-{uuid.uuid4().hex}"
# Initialize LiveKit API client
lkapi = livekit_api.LiveKitAPI(
url=os.getenv("LIVEKIT_URL"),
api_key=os.getenv("LIVEKIT_API_KEY"),
api_secret=os.getenv("LIVEKIT_API_SECRET"),
)
try:
# Create room with configuration
req = CreateRoomRequest(
name=room_name,
empty_timeout=300, # Keep room alive 5 minutes after empty
max_participants=10, # Adjust based on your needs
)
room = await lkapi.room.create_room(req)
print(f"Room created: {room.name}")
# Create agent session with Gemini model
session = AgentSession(
llm=openai.realtime.RealtimeModel(voice="coral"),
)
# Start the session
await session.start(room=room, agent=Assistant())
await ctx.connect()
# Generate initial greeting
await session.generate_reply(
instructions="Greet the user and offer your assistance."
)
finally:
await lkapi.aclose()
# Run the agent
if __name__ == "__main__":
opts = agents.WorkerOptions(entrypoint_fnc=entrypoint)
agents.cli.run_app(opts)
```
This code -
**Creates a custom agent class:**
* Inherits from `Agent`: Base class for all LiveKit agents
* `instructions`: System prompt that defines the agent's personality and capabilities
* **Tells the agent**: It's a voice assistant that can use web search
**Creates a callable tool:**
* `@function_tool()`: Decorator that registers this method as a tool the agent can call
* `async def`: Asynchronous function (required for LiveKit agents)
* **Type hints**: `query: str -> str` helps the AI understand input/output types
* **Docstring**: Describes the function for the AI model
* **Current implementation**: Placeholder that returns a formatted string
**The main function that runs when the agent starts:**
* `ctx: agents.JobContext`: Contains information about the current job/session
**Creates a unique room name:**
* **First tries**: Environment variable `LIVEKIT_ROOM_NAME`
* **Falls back to**: Generated name like `assistant-room-a1b2c3d4e5f6...`
* `uuid.uuid4().hex`: Creates a random hexadecimal string
**Starts the agent and begins conversation:**
* `session.start()`: Connects the agent to the room
* `agent=Assistant()`: Uses your custom Assistant class
* `ctx.connect()`: Connects to the LiveKit infrastructure
* `generate_reply()`: Makes the agent speak first with a greeting
## Complete Example with Web Search
Here's a complete example that includes web search functionality using Tavily:
```python
import logging
import os
import uuid
import dotenv
from livekit import agents
from livekit import api as livekit_api
from livekit.agents import Agent, AgentSession, function_tool
from livekit.api.room_service import CreateRoomRequest
from livekit.plugins import google
from maxim import Maxim
from maxim.logger.livekit import instrument_livekit
from tavily import TavilyClient
dotenv.load_dotenv(override=True)
logging.basicConfig(level=logging.INFO)
# Initialize Maxim observability
logger = Maxim().logger()
TAVILY_API_KEY = os.getenv("TAVILY_API_KEY")
def on_event(event: str, data: dict):
if event == "maxim.trace.started":
trace_id = data["trace_id"]
trace = data["trace"]
logging.info(f"Trace started - ID: {trace_id}")
elif event == "maxim.trace.ended":
trace_id = data["trace_id"]
trace = data["trace"]
logging.info(f"Trace ended - ID: {trace_id}")
# Instrument LiveKit with Maxim
instrument_livekit(logger, on_event)
class Assistant(Agent):
def __init__(self) -> None:
super().__init__(
instructions="You are a helpful voice AI assistant. You can search the web using the web_search tool."
)
@function_tool()
async def web_search(self, query: str) -> str:
"""
Performs a web search for the given query.
Args:
query: The search query string
Returns:
Search results as a formatted string
"""
if not TAVILY_API_KEY:
return "Web search is not available. Please configure the Tavily API key."
tavily_client = TavilyClient(api_key=TAVILY_API_KEY)
try:
response = tavily_client.search(query=query, search_depth="basic")
if response.get('answer'):
return response['answer']
return str(response.get('results', 'No results found.'))
except Exception as e:
return f"An error occurred during web search: {e}"
async def entrypoint(ctx: agents.JobContext):
room_name = os.getenv("LIVEKIT_ROOM_NAME") or f"assistant-room-{uuid.uuid4().hex}"
lkapi = livekit_api.LiveKitAPI(
url=os.getenv("LIVEKIT_URL"),
api_key=os.getenv("LIVEKIT_API_KEY"),
api_secret=os.getenv("LIVEKIT_API_SECRET"),
)
try:
req = CreateRoomRequest(
name=room_name,
empty_timeout=300,
max_participants=10,
)
room = await lkapi.room.create_room(req)
print(f"Room created: {room.name}")
session = AgentSession(
llm=openai.realtime.RealtimeModel(voice="coral"),
)
await session.start(room=room, agent=Assistant())
await ctx.connect()
await session.generate_reply(
instructions="Greet the user and offer your assistance."
)
finally:
await lkapi.aclose()
if __name__ == "__main__":
opts = agents.WorkerOptions(entrypoint_fnc=entrypoint)
agents.cli.run_app(opts)
```
## What Gets Traced
### Agent Conversations
Transcript containing System Instructions, User and Assistant Messages are pushed to Maxim
## Running Your Agent
1. Working code is uploaded here - [https://github.com/maximhq/maxim-cookbooks/blob/main/python/observability-online-eval/livekit/livekit-gemini.py](https://github.com/maximhq/maxim-cookbooks/blob/main/python/observability-online-eval/livekit/livekit-gemini.py)
2. **Start your LiveKit server** (if self-hosting) or ensure your LiveKit Cloud instance is running
3. **Run your agent**:
```bash
uv sync
uv run livekit-gemini.py console
```
 ## Resources
You can quickly try the LlamaIndex One Line Integration here -
## Resources
You can quickly try the LlamaIndex One Line Integration here -
 ## Async LLM calls
```python
async with MaximMistralClient(Mistral(
api_key=os.getenv('MISTRAL_API_KEY', ''),
), logger) as mistral:
response = await mistral.chat.complete_async(
model='mistral-small-latest',
messages=[
{
'role': 'user',
'content': 'Explain the difference between async and sync programming in Python in one sentence.'
}
]
)
print(response)
```
## Supported Mistral Models
The MaximMistralClient supports all Mistral models available through the Mistral API, including:
* `mistral-small-latest`
* `mistral-medium-latest`
* `open-mistral-7b`
* And other available Mistral models
## Resources
You can quickly try the Mistral One Line Integration here -
## Async LLM calls
```python
async with MaximMistralClient(Mistral(
api_key=os.getenv('MISTRAL_API_KEY', ''),
), logger) as mistral:
response = await mistral.chat.complete_async(
model='mistral-small-latest',
messages=[
{
'role': 'user',
'content': 'Explain the difference between async and sync programming in Python in one sentence.'
}
]
)
print(response)
```
## Supported Mistral Models
The MaximMistralClient supports all Mistral models available through the Mistral API, including:
* `mistral-small-latest`
* `mistral-medium-latest`
* `open-mistral-7b`
* And other available Mistral models
## Resources
You can quickly try the Mistral One Line Integration here -
 # OpenAI SDK
Source: https://www.getmaxim.ai/docs/sdk/python/integrations/openai/one-line-integration
Learn how to integrate Maxim observability with the OpenAI SDK in just one line of code.
## Requirements
```
"openai>=1.65.4"
"maxim-py>=3.5.0"
```
## Env variables
```
MAXIM_API_KEY=
MAXIM_LOG_REPO_ID=
OPENAI_API_KEY=
```
## Initialize logger
```python
import maxim from Maxim
logger = Maxim().logger()
```
## Initialize MaximOpenAIClient
```python {4}
from openai import OpenAI
from maxim.logger.openai import MaximOpenAIClient
client = MaximOpenAIClient(client=OpenAI(api_key=OPENAI_API_KEY),logger=logger)
```
## Make LLM calls using MaximOpenAIClient
```python {4}
from openai import OpenAI
from maxim.logger.openai import MaximOpenAIClient
client = MaximOpenAIClient(client=OpenAI(api_key=OPENAI_API_KEY),logger=logger)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Write a haiku about recursion in programming."},
]
# Create a chat completion request
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
)
# Extract response text and usage
response_text = response.choices[0].message.content
print(response_text)
```
# OpenAI SDK
Source: https://www.getmaxim.ai/docs/sdk/python/integrations/openai/one-line-integration
Learn how to integrate Maxim observability with the OpenAI SDK in just one line of code.
## Requirements
```
"openai>=1.65.4"
"maxim-py>=3.5.0"
```
## Env variables
```
MAXIM_API_KEY=
MAXIM_LOG_REPO_ID=
OPENAI_API_KEY=
```
## Initialize logger
```python
import maxim from Maxim
logger = Maxim().logger()
```
## Initialize MaximOpenAIClient
```python {4}
from openai import OpenAI
from maxim.logger.openai import MaximOpenAIClient
client = MaximOpenAIClient(client=OpenAI(api_key=OPENAI_API_KEY),logger=logger)
```
## Make LLM calls using MaximOpenAIClient
```python {4}
from openai import OpenAI
from maxim.logger.openai import MaximOpenAIClient
client = MaximOpenAIClient(client=OpenAI(api_key=OPENAI_API_KEY),logger=logger)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Write a haiku about recursion in programming."},
]
# Create a chat completion request
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
)
# Extract response text and usage
response_text = response.choices[0].message.content
print(response_text)
```

 ## Troubleshooting
### Common Issues
* **No traces appearing**: Ensure your API key and repository ID are correct
* **Import errors**: Make sure you've installed all required packages (`maxim-py`, `pydantic-ai`, `python-dotenv`)
* **Tool not working**: Ensure `instrument_pydantic_ai()` is called **before** creating your agent
* **Environment variables**: Verify your `.env` file is in the correct location and contains all required keys
* **Session management**: Make sure to call `end_session()` in a `finally` block to ensure proper cleanup
### Debug Mode
Enable debug mode to surface any internal errors:
```python
instrument_pydantic_ai(Maxim().logger(), debug=True)
```
### Session Management Best Practices
1. **Always use try/finally**: Ensure sessions are properly ended even when errors occur
2. **Group related operations**: Use sessions to group related agent runs for better organization
3. **Meaningful session names**: Use descriptive session names for easier debugging and analysis
```python
# Good practice
instrument_pydantic_ai.start_session("User Query Processing")
try:
# Multiple related operations
result1 = agent.run_sync("First step")
result2 = agent.run_sync("Second step")
finally:
instrument_pydantic_ai.end_session()
```
## Resources
## Troubleshooting
### Common Issues
* **No traces appearing**: Ensure your API key and repository ID are correct
* **Import errors**: Make sure you've installed all required packages (`maxim-py`, `pydantic-ai`, `python-dotenv`)
* **Tool not working**: Ensure `instrument_pydantic_ai()` is called **before** creating your agent
* **Environment variables**: Verify your `.env` file is in the correct location and contains all required keys
* **Session management**: Make sure to call `end_session()` in a `finally` block to ensure proper cleanup
### Debug Mode
Enable debug mode to surface any internal errors:
```python
instrument_pydantic_ai(Maxim().logger(), debug=True)
```
### Session Management Best Practices
1. **Always use try/finally**: Ensure sessions are properly ended even when errors occur
2. **Group related operations**: Use sessions to group related agent runs for better organization
3. **Meaningful session names**: Use descriptive session names for easier debugging and analysis
```python
# Good practice
instrument_pydantic_ai.start_session("User Query Processing")
try:
# Multiple related operations
result1 = agent.run_sync("First step")
result2 = agent.run_sync("Second step")
finally:
instrument_pydantic_ai.end_session()
```
## Resources
Integrate with Langchain
Get started
Integrate with Langgraph
Get started
Integrate with OpenAI Agents SDK
Get started
Integrate with LiteLLM SDK
Get started
Integrate with LiteLLM proxy
Get started
Integrate with OpenAI SDK
Get started
Integrate with Anthropic
Get started
Integrate with Bedrock
Get started
Integrate with Mistral
Get started
Integrate with CrewAI
Get started
Integrate with LiveKit
Get started
## Streaming Support
```javascript
import { streamText } from 'ai';
import { openai } from '@ai-sdk/openai';
import { wrapMaximAISDKModel, MaximVercelProviderMetadata } from '@maximai/maxim-js/vercel-ai-sdk';
const model = wrapMaximAISDKModel(openai('gpt-4'), logger);
const { textStream } = await streamText({
model: model,
prompt: 'Write a story about a robot learning to paint.',
system: 'You are a creative storyteller',
providerOptions: {
maxim: {
traceName: 'Story Generation',
traceTags: {
type: 'creative',
format: 'streaming'
},
} as MaximVercelProviderMetadata,
},
});
for await (const textPart of textStream) {
process.stdout.write(textPart);
}
```
## Multiple Provider Support
```javascript
import { openai } from '@ai-sdk/openai';
import { anthropic } from '@ai-sdk/anthropic';
import { google } from '@ai-sdk/google';
import { wrapMaximAISDKModel } from '@maximai/maxim-js/vercel-ai-sdk';
// Wrap different provider models
const openaiModel = wrapMaximAISDKModel(openai('gpt-4'), logger);
const anthropicModel = wrapMaximAISDKModel(anthropic('claude-3-5-sonnet-20241022'), logger);
const googleModel = wrapMaximAISDKModel(google('gemini-pro'), logger);
// Use them with the same interface
const responses = await Promise.all([
generateText({ model: openaiModel, prompt: 'Hello from OpenAI' }),
generateText({ model: anthropicModel, prompt: 'Hello from Anthropic' }),
generateText({ model: googleModel, prompt: 'Hello from Google' }),
]);
```
## Next.js Integration
### **API Route Example**
```javascript
// app/api/chat/route.js
import { streamText } from 'ai';
import { openai } from '@ai-sdk/openai';
import { wrapMaximAISDKModel, MaximVercelProviderMetadata } from '@maximai/maxim-js/vercel-ai-sdk';
import { Maxim } from "@maximai/maxim-js";
const maxim = new Maxim({ apiKey });
const logger = await maxim.logger({ id: process.env.MAXIM_LOG_REPO_ID });
const model = wrapMaximAISDKModel(openai('gpt-4'), logger);
export async function POST(req) {
const { messages } = await req.json();
const result = await streamText({
model: model,
messages,
system: 'You are a helpful assistant',
providerOptions: {
maxim: {
traceName: 'Chat API',
traceTags: {
endpoint: '/api/chat',
type: 'conversation'
},
} as MaximVercelProviderMetadata,
},
});
return result.toAIStreamResponse();
}
```
### **Client-side Integration**
```javascript
// components/Chat.jsx
import { useChat } from 'ai/react';
export default function Chat() {
const { messages, input, handleInputChange, handleSubmit } = useChat({
api: '/api/chat',
});
return (
{messages.map((m) => (
);
}
```
## Resources
{m.role}: {m.content}
))}
Maxim is designed for companies with a security mindset.



.png)
 ### Control plane
The control plane encompasses all applications that handle the business logic and user experience. Web service and serverless functions are exposed to internet via a load balancer.
#### Components
| Component | Description | Language |
| -------------------- | ------------------------------------------------ | ---------- |
| Web service | Dashboard + APIs | TypeScript |
| AI-Stack | Proprietary evaluators | Python |
| Workers | Real-time log processing, evaluation, and alerts | Go |
| Serverless functions | SDK APIs | Go |
### Data plane
The data plane encompasses all components that handle data at rest and in transit. We utilize secure VPC peering (where required) to connect to control plane.
#### Components
| Component | Description |
| -------------------- | -------------------------------------- |
| Dragonfly | In-memory key-value store |
| Kafka | Queue for real-time log processing |
| BigQuery/Redshift | Data lake |
| Clickhouse | OLAP database for logs and evaluations |
| MySQL | OLTP database |
| Firestore/DocumentDB | Used as a vector database |
## Pillars of Maxim's Infrastructure
### Infra as code
* We deploy our infrastructure using Terraform.
* All the images are securely hosted and fingerprinted by customer-specific keys for every version.
* Our infra as code is available for review by the customer.
### Cloud provider support
* We manage the orchestration of the infrastructure using Kubernetes.
* We support GCP, AWS and Azure as cloud provider.
### Security measures
* We attach a cloud-native security layer to ingress (Cloud Armor on GCP, AWS WAF, Azure WAF etc.).
* We have pre-defined configurations vetted by our security team for every cloud provider.
* The k8s cluster is deployed in a separate VPC.
* We use cloud-native MySQL for storage with encryption at rest.
* All outgoing traffic is routed through a cloud-native internet gateway.
# Zero Touch Deployment
Source: https://www.getmaxim.ai/docs/self-hosting/zerotouch
This guide outlines Maxim's zero-touch deployment process, covering infrastructure components, security protocols, and supported cloud providers.
Zero Touch Deployment is designed for organizations that require the highest level of security and privacy. This deployment option ensures that your data remains within your infrastructure, with no data exchange occurring with Maxim's cloud services.
## Setup Requirements
* ✅ Google Cloud Project, AWS sub-account or Azure resource group
* ✅ Credentials attached to [eng@getmaxim.ai](mailto:eng@getmaxim.ai) email address
* ✅ Admin access to the Google Cloud Project, AWS sub-account or Azure resource group
* ✅ Domain name/subdomain for generating SSL certificates and serving Maxim app
* ✅ If the service is going to be public, we will configure a Cloudflare Turnstile key for the subdomain used in the Maxim INVPC deployment.
## Infrastructure requirements
1. k8s
1.1 GCP - Google Kubernetes Engine (GKE)
1.2 AWS - Elastic Kubernetes Service (EKS)
1.3 Azure - Azure Kubernetes Service (AKS)
2. 3 VMs, min: 2vCPU + 8 Gi RAM
3. 1 L7 load balancer
4. 1 Bucket as CDN backend
5. 1/2 Static IPs for egress
6. NAT gateway for internet access
7. Security (Optional)
1.1. GCP - Cloud armor for DDoS protection and WAF capabilities
1.2. AWS - AWS Shield and AWS WAF for threat protection
1.3. Azure - Azure DDoS Protection and Azure Web Application Firewall
8. Data lake
1.1 GCP - BigQuery
1.2 AWS - Amazon Redshift
1.3 Azure - Azure Synapse Analytics
9. Document DB
1.1 GCP - Firestore
1.2 AWS - Amazon DocumentDB
1.3 Azure - Azure Cosmos DB
10. MySQL
1.1. GCP - Cloud SQL for MySQL
1.2. AWS - Amazon RDS for MySQL
1.3. Azure - Azure Database for MySQL
11. Cloud native logging and error tracking
## Services we deploy
1. Dashboard: NextJS service (3 instances)
2. AIStack: Python(FastAPI) service (2 instances)
3. Workers: Go(workers) (3 instances)
4. Kafka cluster: 3 nodes
4.1. Kafka UI: 1 node
4.2. Kafka exporter (Observability)
5. Clickhouse cluster: 3 nodes
6. Redis sentinel: 1 master, 3 read-replica, 3 sentinel
7. k8s-prometheus (Observability)
## Deployment Process
* We deploy the data plane and application plane in the same VPC.
* We create a cloud provider-specific Docker image repository for storing all images.
* We use Tailscale for secure communication between the central CD pipeline and the application plane.
## Release Cadence
* We release new versions every week, combining all fixes and features released in the previous week's cloud offering.
* For security vulnerabilities, we release a patch within 24 hours.
* For critical vulnerabilities, we release a patch within 1 hour.
## Observability
* We use a shared Sentry instance to track errors and exceptions.
* We use a shared Prometheus + Grafana instance to track metrics.
* Customers receive access to Sentry projects and Grafana dashboards for audit and monitoring purposes.
## Security Measures
* All service account keys are rotated at least every 90 days.
* Access to the shared Google Cloud Project or AWS sub-account is limited to the [eng@getmaxim.ai](mailto:eng@getmaxim.ai) email address.
* 2FA is required for accessing the shared Google Cloud Project, AWS sub-account or AWS resource group.
* We enable cloud provider-specific security features and share the audit every 60 days (example dashboard).
### Control plane
The control plane encompasses all applications that handle the business logic and user experience. Web service and serverless functions are exposed to internet via a load balancer.
#### Components
| Component | Description | Language |
| -------------------- | ------------------------------------------------ | ---------- |
| Web service | Dashboard + APIs | TypeScript |
| AI-Stack | Proprietary evaluators | Python |
| Workers | Real-time log processing, evaluation, and alerts | Go |
| Serverless functions | SDK APIs | Go |
### Data plane
The data plane encompasses all components that handle data at rest and in transit. We utilize secure VPC peering (where required) to connect to control plane.
#### Components
| Component | Description |
| -------------------- | -------------------------------------- |
| Dragonfly | In-memory key-value store |
| Kafka | Queue for real-time log processing |
| BigQuery/Redshift | Data lake |
| Clickhouse | OLAP database for logs and evaluations |
| MySQL | OLTP database |
| Firestore/DocumentDB | Used as a vector database |
## Pillars of Maxim's Infrastructure
### Infra as code
* We deploy our infrastructure using Terraform.
* All the images are securely hosted and fingerprinted by customer-specific keys for every version.
* Our infra as code is available for review by the customer.
### Cloud provider support
* We manage the orchestration of the infrastructure using Kubernetes.
* We support GCP, AWS and Azure as cloud provider.
### Security measures
* We attach a cloud-native security layer to ingress (Cloud Armor on GCP, AWS WAF, Azure WAF etc.).
* We have pre-defined configurations vetted by our security team for every cloud provider.
* The k8s cluster is deployed in a separate VPC.
* We use cloud-native MySQL for storage with encryption at rest.
* All outgoing traffic is routed through a cloud-native internet gateway.
# Zero Touch Deployment
Source: https://www.getmaxim.ai/docs/self-hosting/zerotouch
This guide outlines Maxim's zero-touch deployment process, covering infrastructure components, security protocols, and supported cloud providers.
Zero Touch Deployment is designed for organizations that require the highest level of security and privacy. This deployment option ensures that your data remains within your infrastructure, with no data exchange occurring with Maxim's cloud services.
## Setup Requirements
* ✅ Google Cloud Project, AWS sub-account or Azure resource group
* ✅ Credentials attached to [eng@getmaxim.ai](mailto:eng@getmaxim.ai) email address
* ✅ Admin access to the Google Cloud Project, AWS sub-account or Azure resource group
* ✅ Domain name/subdomain for generating SSL certificates and serving Maxim app
* ✅ If the service is going to be public, we will configure a Cloudflare Turnstile key for the subdomain used in the Maxim INVPC deployment.
## Infrastructure requirements
1. k8s
1.1 GCP - Google Kubernetes Engine (GKE)
1.2 AWS - Elastic Kubernetes Service (EKS)
1.3 Azure - Azure Kubernetes Service (AKS)
2. 3 VMs, min: 2vCPU + 8 Gi RAM
3. 1 L7 load balancer
4. 1 Bucket as CDN backend
5. 1/2 Static IPs for egress
6. NAT gateway for internet access
7. Security (Optional)
1.1. GCP - Cloud armor for DDoS protection and WAF capabilities
1.2. AWS - AWS Shield and AWS WAF for threat protection
1.3. Azure - Azure DDoS Protection and Azure Web Application Firewall
8. Data lake
1.1 GCP - BigQuery
1.2 AWS - Amazon Redshift
1.3 Azure - Azure Synapse Analytics
9. Document DB
1.1 GCP - Firestore
1.2 AWS - Amazon DocumentDB
1.3 Azure - Azure Cosmos DB
10. MySQL
1.1. GCP - Cloud SQL for MySQL
1.2. AWS - Amazon RDS for MySQL
1.3. Azure - Azure Database for MySQL
11. Cloud native logging and error tracking
## Services we deploy
1. Dashboard: NextJS service (3 instances)
2. AIStack: Python(FastAPI) service (2 instances)
3. Workers: Go(workers) (3 instances)
4. Kafka cluster: 3 nodes
4.1. Kafka UI: 1 node
4.2. Kafka exporter (Observability)
5. Clickhouse cluster: 3 nodes
6. Redis sentinel: 1 master, 3 read-replica, 3 sentinel
7. k8s-prometheus (Observability)
## Deployment Process
* We deploy the data plane and application plane in the same VPC.
* We create a cloud provider-specific Docker image repository for storing all images.
* We use Tailscale for secure communication between the central CD pipeline and the application plane.
## Release Cadence
* We release new versions every week, combining all fixes and features released in the previous week's cloud offering.
* For security vulnerabilities, we release a patch within 24 hours.
* For critical vulnerabilities, we release a patch within 1 hour.
## Observability
* We use a shared Sentry instance to track errors and exceptions.
* We use a shared Prometheus + Grafana instance to track metrics.
* Customers receive access to Sentry projects and Grafana dashboards for audit and monitoring purposes.
## Security Measures
* All service account keys are rotated at least every 90 days.
* Access to the shared Google Cloud Project or AWS sub-account is limited to the [eng@getmaxim.ai](mailto:eng@getmaxim.ai) email address.
* 2FA is required for accessing the shared Google Cloud Project, AWS sub-account or AWS resource group.
* We enable cloud provider-specific security features and share the audit every 60 days (example dashboard).
 ## SLAs
* 99.9% uptime.
* \< 5 minutes response time (acknowledgment) for incidents.
* \< 48 hours resolution time.
## Support
* We provide 24/7 support for any issues that may occur during the deployment process.
* We also offer 24/7 support for any issues that may arise during service operation.
* We assign a dedicated support engineer to each account to address any issues that may occur during the deployment process and operation.
# Custom Pricing
Source: https://www.getmaxim.ai/docs/settings/custom-pricing
Learn how to set up custom token pricing in Maxim for accurate cost reporting in AI evaluations and logs, ensuring displayed costs match your actual expenses.
Configure your negotiated token costs for accurate cost reporting in AI evaluations and real-time logs. Custom token pricing ensures that displayed costs match your actual expenses based on special pricing agreements.
## How it works
## SLAs
* 99.9% uptime.
* \< 5 minutes response time (acknowledgment) for incidents.
* \< 48 hours resolution time.
## Support
* We provide 24/7 support for any issues that may occur during the deployment process.
* We also offer 24/7 support for any issues that may arise during service operation.
* We assign a dedicated support engineer to each account to address any issues that may occur during the deployment process and operation.
# Custom Pricing
Source: https://www.getmaxim.ai/docs/settings/custom-pricing
Learn how to set up custom token pricing in Maxim for accurate cost reporting in AI evaluations and logs, ensuring displayed costs match your actual expenses.
Configure your negotiated token costs for accurate cost reporting in AI evaluations and real-time logs. Custom token pricing ensures that displayed costs match your actual expenses based on special pricing agreements.
## How it works
 ## Configure model pricing
1. Go to **Settings > Models > Model Configs**
2. Select a model config to edit
3. Locate the **Pricing structure** section
4. Choose your pricing structure from the dropdown
## Configure model pricing
1. Go to **Settings > Models > Model Configs**
2. Select a model config to edit
3. Locate the **Pricing structure** section
4. Choose your pricing structure from the dropdown
 ## Set up pricing for log repository
1. Open **Logs** from the sidebar
2. Select the log repository you want to configure custom pricing for
3. Find the **Pricing structure** section
4. Choose your pricing structure from the dropdown
## Set up pricing for log repository
1. Open **Logs** from the sidebar
2. Select the log repository you want to configure custom pricing for
3. Find the **Pricing structure** section
4. Choose your pricing structure from the dropdown
 # Maxim API keys
Source: https://www.getmaxim.ai/docs/settings/maxim-api-keys
Learn how to create Maxim API keys.
Maxim API keys are used to authenticate your requests to the Maxim API. You can create a new API key by following these steps:
* Go to `Settings` → `API keys`.
* Click on `Generate new`, name your key, and copy the generated key.
# Maxim API keys
Source: https://www.getmaxim.ai/docs/settings/maxim-api-keys
Learn how to create Maxim API keys.
Maxim API keys are used to authenticate your requests to the Maxim API. You can create a new API key by following these steps:
* Go to `Settings` → `API keys`.
* Click on `Generate new`, name your key, and copy the generated key.
 # Members and Roles
Source: https://www.getmaxim.ai/docs/settings/members-and-roles
Learn how to invite team members and create roles in Maxim.
## Invite team members
To invite a team member to your workspace, follow these steps:
* Go to `Settings` → `Members`.
* Click on `Invite`, located at the top right of the page.
* Enter the email ID of the person you want to invite. To invite multiple people, separate their email IDs with commas.
## Create roles
Maxim uses a role-based access control (RBAC) system to manage user permissions. You can create a role by following these steps:
* Go to `Settings` → `Roles`.
* Click on `Create role`.
* Enter a name for the role.
* Select the permissions you want to assign to the role.
* Click on `Create`.
# Members and Roles
Source: https://www.getmaxim.ai/docs/settings/members-and-roles
Learn how to invite team members and create roles in Maxim.
## Invite team members
To invite a team member to your workspace, follow these steps:
* Go to `Settings` → `Members`.
* Click on `Invite`, located at the top right of the page.
* Enter the email ID of the person you want to invite. To invite multiple people, separate their email IDs with commas.
## Create roles
Maxim uses a role-based access control (RBAC) system to manage user permissions. You can create a role by following these steps:
* Go to `Settings` → `Roles`.
* Click on `Create role`.
* Enter a name for the role.
* Select the permissions you want to assign to the role.
* Click on `Create`.













 You can then use the key using the `{{vault.key_name}}` syntax on the playground or if you want to access this using code, you can use
You can then use the key using the `{{vault.key_name}}` syntax on the playground or if you want to access this using code, you can use maxim.getVaultVariable in the scripts of your agents, API evaluators etc. The video below shows how to use the vault variables in different ways on the platform.
 ## 3. Advanced settings (optional)
* **Maximum number of turns:** Set a limit for conversation turns. If no value's set, the simulation ends when complete
* **Reference tools**: Attach any tools you want to test with the simulation. You can learn more about setting up tools [here](/library/prompt-tools#create-a-code-tool)
* **Reference context**: Add context sources to enhance conversations. Learn more [here](/library/context-sources#bring-your-rag-via-an-api-endpoint)
## 3. Advanced settings (optional)
* **Maximum number of turns:** Set a limit for conversation turns. If no value's set, the simulation ends when complete
* **Reference tools**: Attach any tools you want to test with the simulation. You can learn more about setting up tools [here](/library/prompt-tools#create-a-code-tool)
* **Reference context**: Add context sources to enhance conversations. Learn more [here](/library/context-sources#bring-your-rag-via-an-api-endpoint)
 ## Example simulation
Here's a real-world example of a simulated conversation:
## Example simulation
Here's a real-world example of a simulated conversation:
 # Simulation Runs
Source: https://www.getmaxim.ai/docs/simulations/simulation-runs
Test your AI's conversational abilities with realistic, scenario-based simulations
## Evaluate agent performance with simulated sessions
Test your AI agent's performance using automated simulated conversations to get insights into how well your agent handles different scenarios and user interactions.
# Simulation Runs
Source: https://www.getmaxim.ai/docs/simulations/simulation-runs
Test your AI's conversational abilities with realistic, scenario-based simulations
## Evaluate agent performance with simulated sessions
Test your AI agent's performance using automated simulated conversations to get insights into how well your agent handles different scenarios and user interactions.





 In distributed tracing, a trace is the complete processing of a request through a distributed system, including all the actions between the request and the response.
| Property | Description |
| ----------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| id | Unique identifier for the trace; this usually can be your request id. |
| name (optional) | Name of the trace; you can keep it same as your API call. i.e. chatQuery |
| tags (optional) | Key-value pairs which you can use for filtering on the dashboard.
In distributed tracing, a trace is the complete processing of a request through a distributed system, including all the actions between the request and the response.
| Property | Description |
| ----------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| id | Unique identifier for the trace; this usually can be your request id. |
| name (optional) | Name of the trace; you can keep it same as your API call. i.e. chatQuery |
| tags (optional) | Key-value pairs which you can use for filtering on the dashboard. There is no limit on the number of tags or the size of the string, although lower amounts are better and faster for search performance specific to your repo. | | input (optional) | The user's prompt or query. | | output (optional) | This is the final response your API sends back. | ### Span
 Spans are fundamental building blocks of distributed tracing. A single trace in distributed tracing consists of a series of tagged time intervals known as spans. Spans represent a logical unit of work in completing a user request or transaction.
Spans are fundamental building blocks of distributed tracing. A single trace in distributed tracing consists of a series of tagged time intervals known as spans. Spans represent a logical unit of work in completing a user request or transaction.
 Events mark significant points within a span or a trace recording instantaneous occurrences that provide additional context for understanding system behavior.
| Property | Description |
| -------- | ------------------------------------------------------------------------------------- |
| id | Unique identifier for the event; this has to be unique in a trace across all elements |
| name | Name of the event. you can keep it same as your API call. i.e. chatQuery |
| tags | These are event specific tags. |
### Generation
A Generation represents a single Large Language Model (LLM) call within a trace or span. Multiple generations can exist within a single trace/span.
#### Structure
* Maxim SDK uses OpenAI's LLM call structure as the standard format.
* All incoming LLM calls are automatically converted to match OpenAI's structure via SDK.
* This standardization ensures consistent handling across different LLM providers.
| Property | Description |
| ----------------- | ----------------------------------------------------------------------------------------------------------------- |
| id | Unique identifier for the generation; this has to be unique in a trace. |
| name | Name of the generation; it can be specific to your workflow intent detection or final summarization call. |
| tags | These are generation specific tags. |
| messages | The messages you are sending to LLM as input. |
| model | Model that is being used for this LLM call. |
| model\_parameters | The model parameters that you are setting up. This is a key-value pair; you can pass any model parameter. |
| error | You can pass LLM error if it has occurred. You can filter all logs with LLM error on the dashboard using filters. |
| result | Result object coming from the LLM. |
### Retrieval
A Retrieval represents a query operation to fetch relevant context or information from a knowledge base or vector database within a trace or span. It is commonly used in RAG (Retrieval Augmented Generation) workflows, where context needs to be fetched before making LLM calls.
| Property | Description |
| -------- | --------------------------------------------------------------------------------------------------------- |
| id | Unique identifier for the retrieval; this has to be unique in a trace. |
| name | Name of the retrieval; it can be specific to your workflow intent detection or final summarization call . |
| tags | These are retrieval specific tags. |
| input | Input used to fetch relevant chunks from your knowledge base |
| output | Array of chunks returned by the knowledge base |
### Tool Call
Tool Call represents an external system or service call done based on an LLM response. Each tool call can be logged separately to track its input, output and latency.
| Property | Description |
| ----------- | ------------------------------------------------------------------------------------------------------------------------- |
| id | Unique identifier for the tool call; this has to be unique in a trace (can be found in the tool call reponse of the LLM). |
| name | Name of the tool call. |
| description | Description of the tool call. |
| args | Arguments passed to the tool call, these are tool specific arguments. |
| result | Result returned by the tool call. |
# Dashboard
Source: https://www.getmaxim.ai/docs/tracing/dashboard
Learn how to use the dashboard to filter and sort your logs
Filter and sort your logs using custom criteria to streamline debugging. Create saved views to quickly access your most-used search patterns.
## Create filters and saved views
Events mark significant points within a span or a trace recording instantaneous occurrences that provide additional context for understanding system behavior.
| Property | Description |
| -------- | ------------------------------------------------------------------------------------- |
| id | Unique identifier for the event; this has to be unique in a trace across all elements |
| name | Name of the event. you can keep it same as your API call. i.e. chatQuery |
| tags | These are event specific tags. |
### Generation
A Generation represents a single Large Language Model (LLM) call within a trace or span. Multiple generations can exist within a single trace/span.
#### Structure
* Maxim SDK uses OpenAI's LLM call structure as the standard format.
* All incoming LLM calls are automatically converted to match OpenAI's structure via SDK.
* This standardization ensures consistent handling across different LLM providers.
| Property | Description |
| ----------------- | ----------------------------------------------------------------------------------------------------------------- |
| id | Unique identifier for the generation; this has to be unique in a trace. |
| name | Name of the generation; it can be specific to your workflow intent detection or final summarization call. |
| tags | These are generation specific tags. |
| messages | The messages you are sending to LLM as input. |
| model | Model that is being used for this LLM call. |
| model\_parameters | The model parameters that you are setting up. This is a key-value pair; you can pass any model parameter. |
| error | You can pass LLM error if it has occurred. You can filter all logs with LLM error on the dashboard using filters. |
| result | Result object coming from the LLM. |
### Retrieval
A Retrieval represents a query operation to fetch relevant context or information from a knowledge base or vector database within a trace or span. It is commonly used in RAG (Retrieval Augmented Generation) workflows, where context needs to be fetched before making LLM calls.
| Property | Description |
| -------- | --------------------------------------------------------------------------------------------------------- |
| id | Unique identifier for the retrieval; this has to be unique in a trace. |
| name | Name of the retrieval; it can be specific to your workflow intent detection or final summarization call . |
| tags | These are retrieval specific tags. |
| input | Input used to fetch relevant chunks from your knowledge base |
| output | Array of chunks returned by the knowledge base |
### Tool Call
Tool Call represents an external system or service call done based on an LLM response. Each tool call can be logged separately to track its input, output and latency.
| Property | Description |
| ----------- | ------------------------------------------------------------------------------------------------------------------------- |
| id | Unique identifier for the tool call; this has to be unique in a trace (can be found in the tool call reponse of the LLM). |
| name | Name of the tool call. |
| description | Description of the tool call. |
| args | Arguments passed to the tool call, these are tool specific arguments. |
| result | Result returned by the tool call. |
# Dashboard
Source: https://www.getmaxim.ai/docs/tracing/dashboard
Learn how to use the dashboard to filter and sort your logs
Filter and sort your logs using custom criteria to streamline debugging. Create saved views to quickly access your most-used search patterns.
## Create filters and saved views
 You can also access the saved view from the search bar to apply those filters quickly.
You can also access the saved view from the search bar to apply those filters quickly.





 Maxim platform leverages three core architectural principles:
### 1. Comprehensive distributed tracing
Track the complete request lifecycle, including LLM requests and responses. Debug precisely with end-to-end application flow visibility.
### 2. Zero-state SDK architecture
Maintain robust observability across functions, classes, and microservices without state management complexity.
### 3. Open source compatibility
Maxim logging is inspired by (and highly compatible with) open telemetry:
* Generate idempotent commit logs for every function call
* Support high concurrency and network instability
* Maintain accurate trace timelines regardless of log arrival order
* Production-proven reliability with over one billion indexed logs
## Key Features
### Real-time monitoring and alerting
Track GenAI metrics through distributed tracing and receive instant alerts via:
* Slack
* PagerDuty
* OpsGenie
Monitor critical thresholds for:
* Cost per trace
* Token usage
* User feedback patterns
Maxim platform leverages three core architectural principles:
### 1. Comprehensive distributed tracing
Track the complete request lifecycle, including LLM requests and responses. Debug precisely with end-to-end application flow visibility.
### 2. Zero-state SDK architecture
Maintain robust observability across functions, classes, and microservices without state management complexity.
### 3. Open source compatibility
Maxim logging is inspired by (and highly compatible with) open telemetry:
* Generate idempotent commit logs for every function call
* Support high concurrency and network instability
* Maintain accurate trace timelines regardless of log arrival order
* Production-proven reliability with over one billion indexed logs
## Key Features
### Real-time monitoring and alerting
Track GenAI metrics through distributed tracing and receive instant alerts via:
* Slack
* PagerDuty
* OpsGenie
Monitor critical thresholds for:
* Cost per trace
* Token usage
* User feedback patterns
 1. **API Gateway**: Authenticates the users and routes API requests
2. **Planner**: Creates execution plans for queries
3. **Intent detector**: Analyzes query intent
4. **Answer generator**: Creates prompts based on planner instructions and RAG context
5. **RAG pipeline**: Retrieves relevant information from vector database
## Setting up the Maxim dashboard
### 1. Create Maxim repository
Create a new repository called "Chatbot production":
1. **API Gateway**: Authenticates the users and routes API requests
2. **Planner**: Creates execution plans for queries
3. **Intent detector**: Analyzes query intent
4. **Answer generator**: Creates prompts based on planner instructions and RAG context
5. **RAG pipeline**: Retrieves relevant information from vector database
## Setting up the Maxim dashboard
### 1. Create Maxim repository
Create a new repository called "Chatbot production":
 # Attachments
Source: https://www.getmaxim.ai/docs/tracing/tracing-via-sdk/attachments
Learn how to attach files and URLs to traces and spans for richer observability in Maxim.
# Attachments
Source: https://www.getmaxim.ai/docs/tracing/tracing-via-sdk/attachments
Learn how to attach files and URLs to traces and spans for richer observability in Maxim.
 # Events
Source: https://www.getmaxim.ai/docs/tracing/tracing-via-sdk/events
Track application milestones and state changes using event logging
Create events to mark specific points in time during your application execution. Capture additional metadata such as intermediate states and system milestones through events.
# Events
Source: https://www.getmaxim.ai/docs/tracing/tracing-via-sdk/events
Track application milestones and state changes using event logging
Create events to mark specific points in time during your application execution. Capture additional metadata such as intermediate states and system milestones through events.
 # Generations
Source: https://www.getmaxim.ai/docs/tracing/tracing-via-sdk/generations
Use generations to log individual calls to Large Language Models (LLMs)
Each trace/span can contain multiple generations.
# Generations
Source: https://www.getmaxim.ai/docs/tracing/tracing-via-sdk/generations
Use generations to log individual calls to Large Language Models (LLMs)
Each trace/span can contain multiple generations.
 # Metadata
Source: https://www.getmaxim.ai/docs/tracing/tracing-via-sdk/metadata
Add custom key-value pairs to components for enhanced observability
The metadata functionality allows you to add custom key-value pairs (string, any) to all components like trace, generation, retrieval, event, and span. This is useful for storing additional context, configuration, user information, or any custom data that helps with debugging, analysis, and observability.
# Metadata
Source: https://www.getmaxim.ai/docs/tracing/tracing-via-sdk/metadata
Add custom key-value pairs to components for enhanced observability
The metadata functionality allows you to add custom key-value pairs (string, any) to all components like trace, generation, retrieval, event, and span. This is useful for storing additional context, configuration, user information, or any custom data that helps with debugging, analysis, and observability.
 # Sessions
Source: https://www.getmaxim.ai/docs/tracing/tracing-via-sdk/sessions
Learn how to group related traces into sessions to track complete user interactions with your GenAI system.
Sessions are particularly useful for tracking multi-turn conversations or complex workflows that span multiple API calls or user interactions. Maintain context across multiple traces, analyze user behavior, and debug multi-interaction issues with sessions. Track the full lifecycle of user engagement by organizing traces into sessions.
# Sessions
Source: https://www.getmaxim.ai/docs/tracing/tracing-via-sdk/sessions
Learn how to group related traces into sessions to track complete user interactions with your GenAI system.
Sessions are particularly useful for tracking multi-turn conversations or complex workflows that span multiple API calls or user interactions. Maintain context across multiple traces, analyze user behavior, and debug multi-interaction issues with sessions. Track the full lifecycle of user engagement by organizing traces into sessions.
 # Spans
Source: https://www.getmaxim.ai/docs/tracing/tracing-via-sdk/spans
Spans help you organize and track requests across microservices within traces. A trace represents the entire journey of a request through your system, while spans are smaller units of work within that trace.
# Spans
Source: https://www.getmaxim.ai/docs/tracing/tracing-via-sdk/spans
Spans help you organize and track requests across microservices within traces. A trace represents the entire journey of a request through your system, while spans are smaller units of work within that trace.
 # Tags
Source: https://www.getmaxim.ai/docs/tracing/tracing-via-sdk/tags
Tag your traces to group and filter endpoint data effectively. Add tags to any node type - spans, generations, retrievals, events, and more.
# Tags
Source: https://www.getmaxim.ai/docs/tracing/tracing-via-sdk/tags
Tag your traces to group and filter endpoint data effectively. Add tags to any node type - spans, generations, retrievals, events, and more.
 # Tool Calls
Source: https://www.getmaxim.ai/docs/tracing/tracing-via-sdk/tool-calls
Track external system calls triggered by LLM responses in your agentic endpoints. Tool calls represent interactions with external services, allowing you to monitor execution time and responses.
## Creating and Logging Tool Calls
# Tool Calls
Source: https://www.getmaxim.ai/docs/tracing/tracing-via-sdk/tool-calls
Track external system calls triggered by LLM responses in your agentic endpoints. Tool calls represent interactions with external services, allowing you to monitor execution time and responses.
## Creating and Logging Tool Calls
 # Traces
Source: https://www.getmaxim.ai/docs/tracing/tracing-via-sdk/traces
Learn how to set up tracing using the Maxim platform
We will cover the necessary steps to instrument your AI application and start monitoring and evaluating its performance.
# Traces
Source: https://www.getmaxim.ai/docs/tracing/tracing-via-sdk/traces
Learn how to set up tracing using the Maxim platform
We will cover the necessary steps to instrument your AI application and start monitoring and evaluating its performance.
 # User Feedback
Source: https://www.getmaxim.ai/docs/tracing/tracing-via-sdk/user-feedback
Track and collect user feedback in application traces using Maxim's Feedback entity. Enhance your AI applications with structured user ratings and comments
# User Feedback
Source: https://www.getmaxim.ai/docs/tracing/tracing-via-sdk/user-feedback
Track and collect user feedback in application traces using Maxim's Feedback entity. Enhance your AI applications with structured user ratings and comments