Looking to quickly generate test data? Try our Synthetic Data Generation feature to create datasets for prompt testing or agent simulation without manual data entry.
Create Datasets Using Templates
Create Datasets quickly with predefined structures using our templates: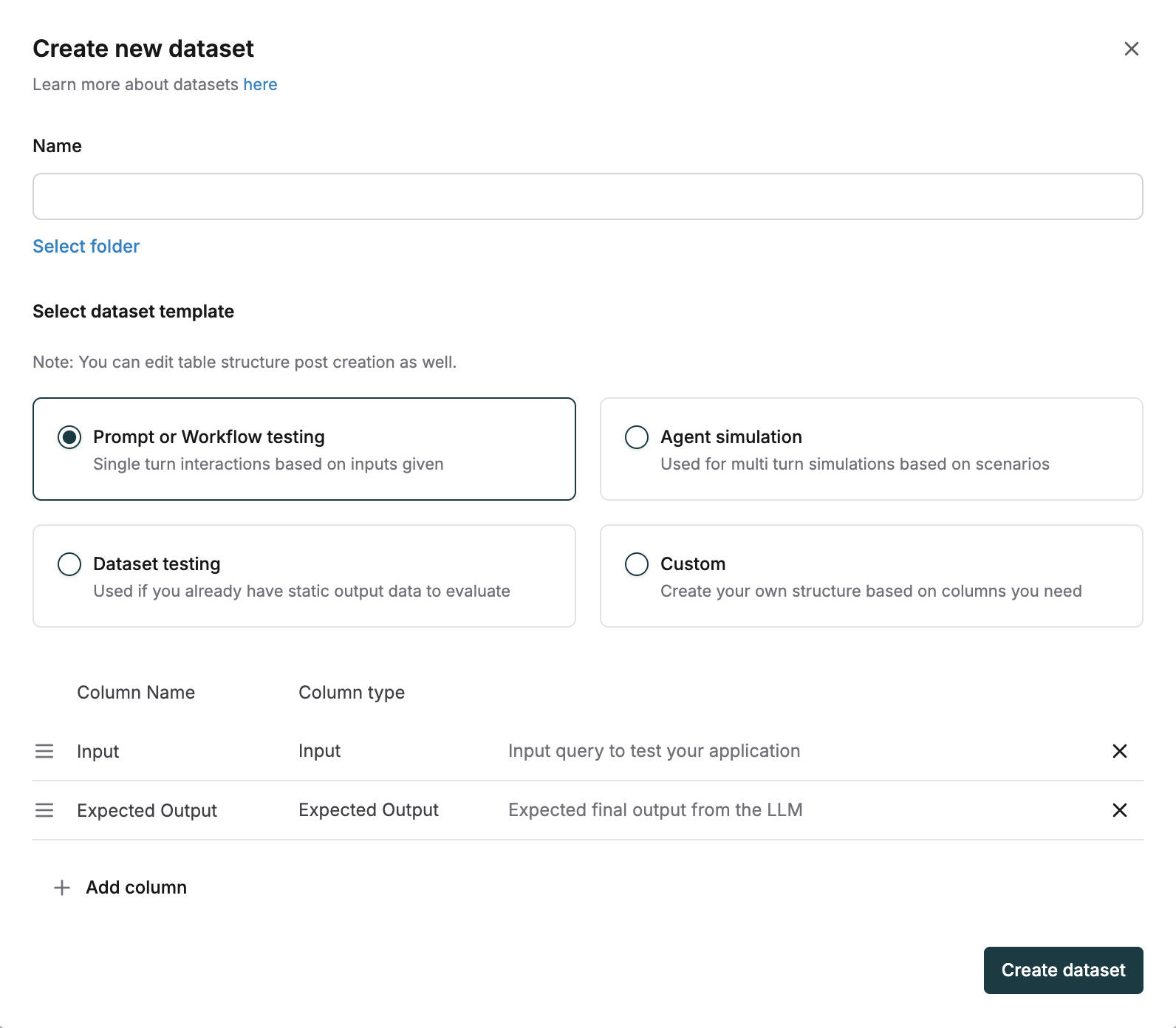
Prompt or Workflow Testing
Choose this template for single-turn interactions based on individual inputs to test prompts or workflows. Example: Input column with prompts like “Summarize this article about climate change” paired with an Expected Output column containing ideal responses.Agent Simulation
Select this template for multi-turn simulations to test agent behaviors across conversation sequences. Example: Scenario column with “Customer inquiring about return policy” and Expected Steps column outlining the agent’s expected actions.Dataset Testing
Use this template when evaluating against existing output data to compare expected and actual results. Example: Input column with “What’s the weather in New York?” and Expected Output column with “65°F and sunny” for direct evaluation.Create Datasets Using CSV
You can also import or create datasets in Maxim using CSV files.1
Create or Import a Dataset Using CSV
- Go to the Datasets section in the Library.
- Click on Upload CSV Dataset.
- Upload your CSV file.
- Map your columns with their respective types.
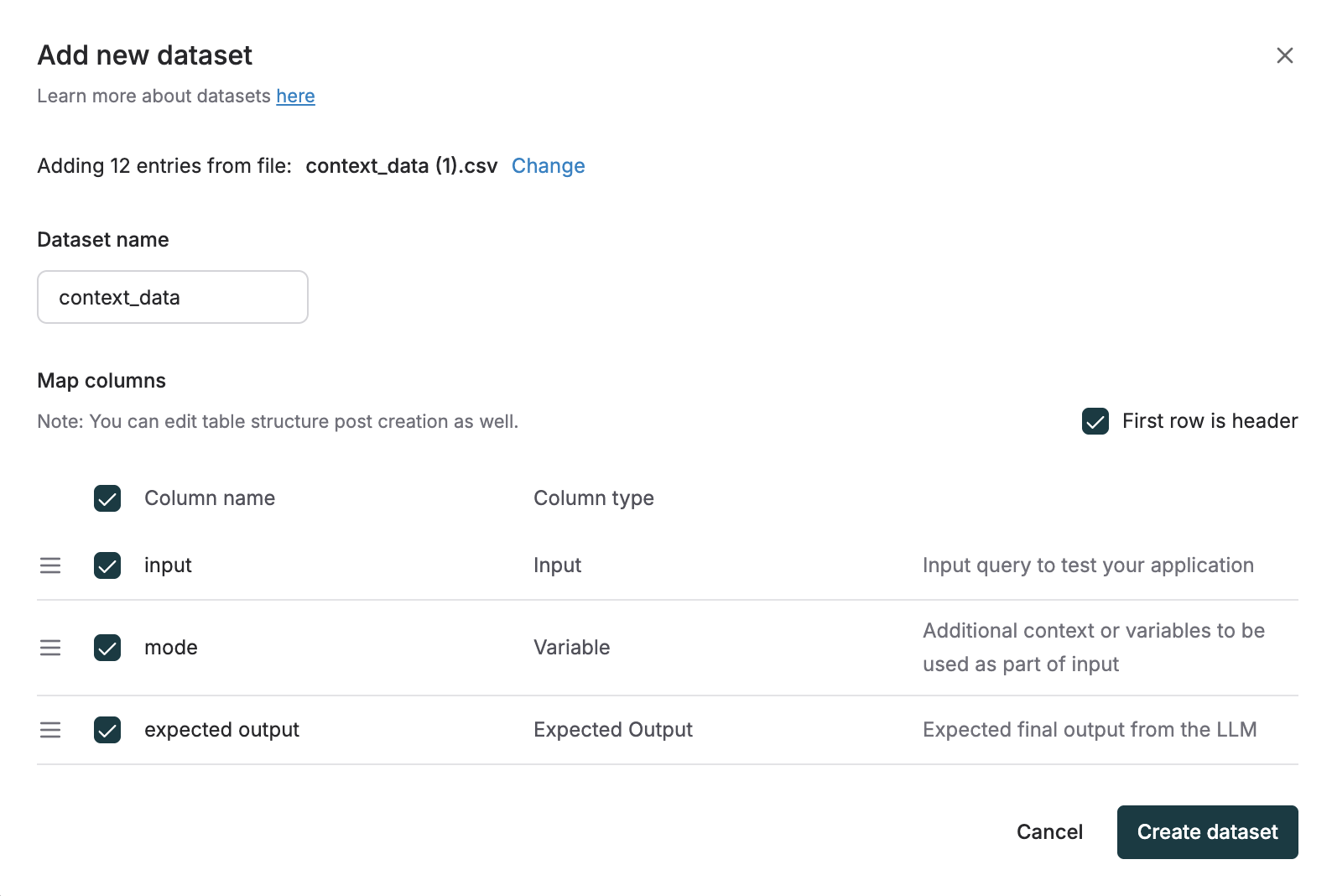
- Click on Create Dataset to complete dataset creation.
CSV-based dataset creation is useful when you already have structured data prepared in spreadsheets or logs. Ensure columns are mapped correctly to avoid mismatches.
Update Existing Datasets Using CSV
You can add new entries to an existing dataset by uploading a CSV with compatible columns.1
Update an Existing Dataset with CSV
- Prepare your CSV file with columns matching your dataset structure (e.g.,
Input,Expected_Output). - In the Maxim UI, go to Library → Datasets, select your dataset.
- Click on Upload CSV and upload your CSV file.
- Map CSV columns to dataset columns or create new dataset columns.
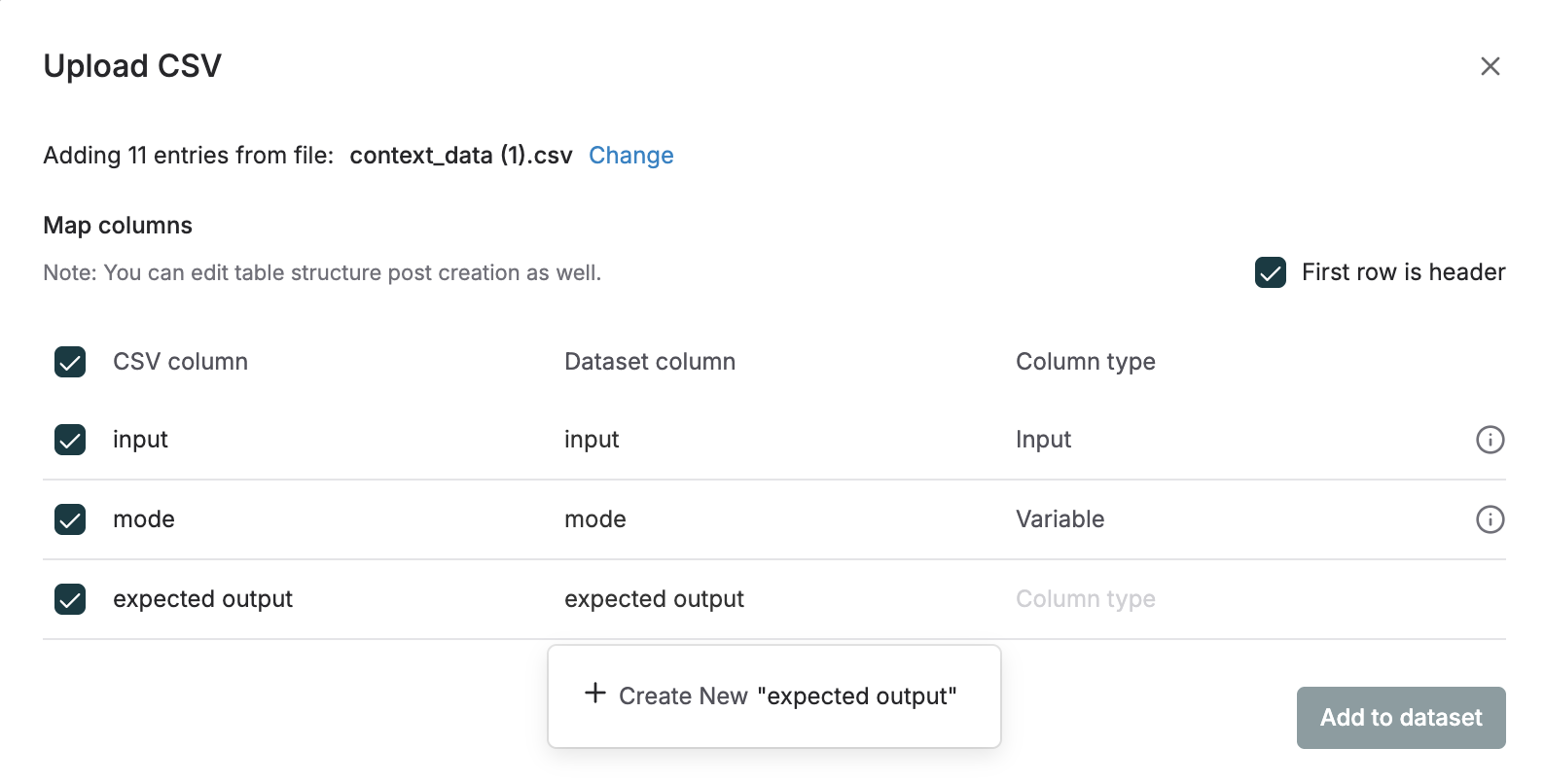
- Confirm mapped dataset columns and column types and click on Add to dataset.
When updating a dataset, the CSV must follow the same column structure defined in the dataset to ensure consistency.
Add Images to Your Dataset
You can enhance your datasets by including images alongside other data types. This is particularly useful for:- Visual content evaluation
- Image-based prompts and responses
- Multi-modal testing scenarios
1
Add Images to Your Dataset
You can add images to your Dataset by creating a column of type Images. We support both URL and local file paths.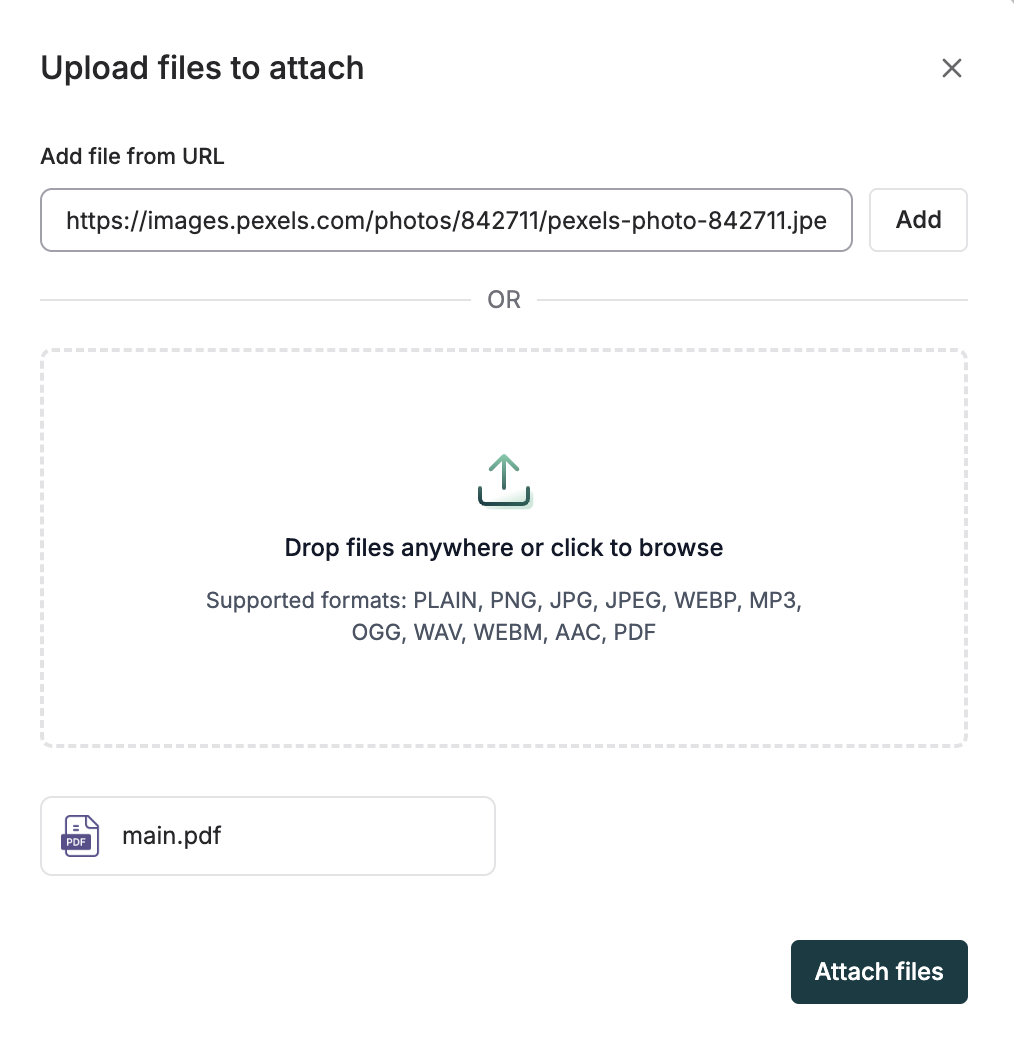
When working with images in datasets:
- Supported formats include common image types (PNG, JPG, JPEG, GIF)
- For URLs, ensure they are publicly accessible
- For local files, maintain consistent file paths across your team
Column types
Input
The Input column type represents the input query used to test your application. This column contains the data that will be processed by your prompt, endpoint, or agent during test runs. Every dataset must have at least one Input column to define what data will be fed into your application. Use this column to store the questions, prompts, or data points that you want to test. Input columns are automatically used during test runs and passed to your application for processing. Examples:- “Summarize this article about climate change”
- “What’s the weather in New York?”
- “Translate the following text to French: Hello world”
Expected Output
The Expected Output column type represents the desired response that your application should generate for the corresponding input. This column is used to evaluate whether your application’s actual output matches the expected result during test runs. Use this column to define what you consider the correct or ideal response for each input. When evaluators are configured for your test runs, they compare the actual output against the expected output to determine accuracy and quality. Examples:- For an input “Translate ‘Hello’ to Spanish”, the expected output might be “Hola”
- For a summarization task, the expected output would be the ideal summary of the original content
Output
The Output column type is used when you have already run your queries elsewhere and have the outputs within your CSV that you want to evaluate directly. This column contains pre-generated responses that you want to assess or analyze without re-running your application. Use this column when you need to evaluate existing outputs from previous runs, external systems, or manual annotations. This is particularly useful when you want to assess the quality of responses that were generated outside of Maxim’s platform. This column type enables you to import historical evaluation data and perform comparative analysis on outputs that were generated using different models or prompts.File
The File column type allows you to upload a file or provide a file URL containing assets or structured data. This is useful for testing applications that need to process documents, images, or other file-based inputs. Use this column when your test cases require external files such as PDFs, images, documents, or structured data files. Files can be uploaded directly to Maxim or referenced via URLs. Supported formats: PDF, TXT, WAV, MP3, images, and other common file types This column type enables multimodal testing scenarios where your application needs to process different types of media and structured content beyond text inputs.Variables
The Variables column type stores values used to parameterize prompts or endpoint payloads, allowing dynamic substitution of content during testing. This enables you to create reusable test cases with flexible inputs that can be customized per row. Use this column to define contextual information that varies across test cases but can be referenced consistently in your prompts or API requests. Variables are automatically substituted during test runs using the{{variable_name}} syntax.
Example: A variable like {{user_name}} can be defined in your dataset and automatically substituted in prompts or API requests during test runs.
Variables provide flexibility in dataset design by allowing you to parameterize common elements like user information, preferences, or context-specific data without hardcoding values into your prompts.
Scenario
The Scenario column type allows you to define specific situations or contexts for your test cases. Use this column to describe the background, user intent, or environment in which an interaction takes place. Scenarios help guide agents or models to respond appropriately based on the described situation. Examples:- “A customer wants to buy an iPhone.”
- “A user is trying to cancel their subscription.”
- “A student asks for help with a math problem.”
Expected Steps
The Expected Steps column type allows you to specify the sequence of actions or decisions that an agent should take in response to a given scenario. This helps users clearly outline the ideal process or workflow, making it easier for evaluators to verify whether the agent is behaving as intended. Use this column to break down the expected agent behavior into individual, logical steps. This is especially useful for multi-turn interactions or complex tasks where the agent’s reasoning and actions need to be evaluated step by step. Example:Expected Tool Calls
The Expected Tool Calls column type allows you to specify which tools (such as APIs, functions, or plugins) you expect an agent to use in response to a scenario. This is especially useful when running prompt runs, where you want to evaluate whether the agent is choosing and invoking the correct tools as part of its reasoning process. Use this column to list the names of the tools or actions that should be called, optionally including parameters or expected arguments. This helps ensure that the agent’s tool usage aligns with your expectations for the task.Supported Tool Call Formats
Tool calls can be provided as a single object or an array of objects. Below are the supported formats:Basic Format
arguments or input field, both parsed JSON object and stringified JSON are supported:
OpenAI Format
Anthropic Format
Bedrock Format
inAnyOrder
Allows tool calls to match in any order.
anyOne
Allows matching any one of the specified alternatives.
anyOne combinator is used when any one of several possible tool calls is acceptable to fulfill the requirement. This is useful in scenarios where there are multiple valid ways for an agent to achieve the same outcome, and you want to allow for flexibility in the agent’s approach.
For example, in the following JSON, either get_pull_request_reviews or get_pull_request_comments (with the specified arguments) will be considered a valid response. The agent only needs to make one of these tool calls to satisfy the expectation.
Conversation History
Conversation history allows you to include a chat history while running Prompt tests. The sequence of messages sent to the LLM is as follows:- messages in the prompt version
- history
- input column in the dataset.
Format
- Conversation history is always a JSON array
Similarly you can add
assistant and tool messages in conversation history.Schedule a demo to see how Maxim AI helps teams ship reliable agents.