How should you be structuring log repositories?
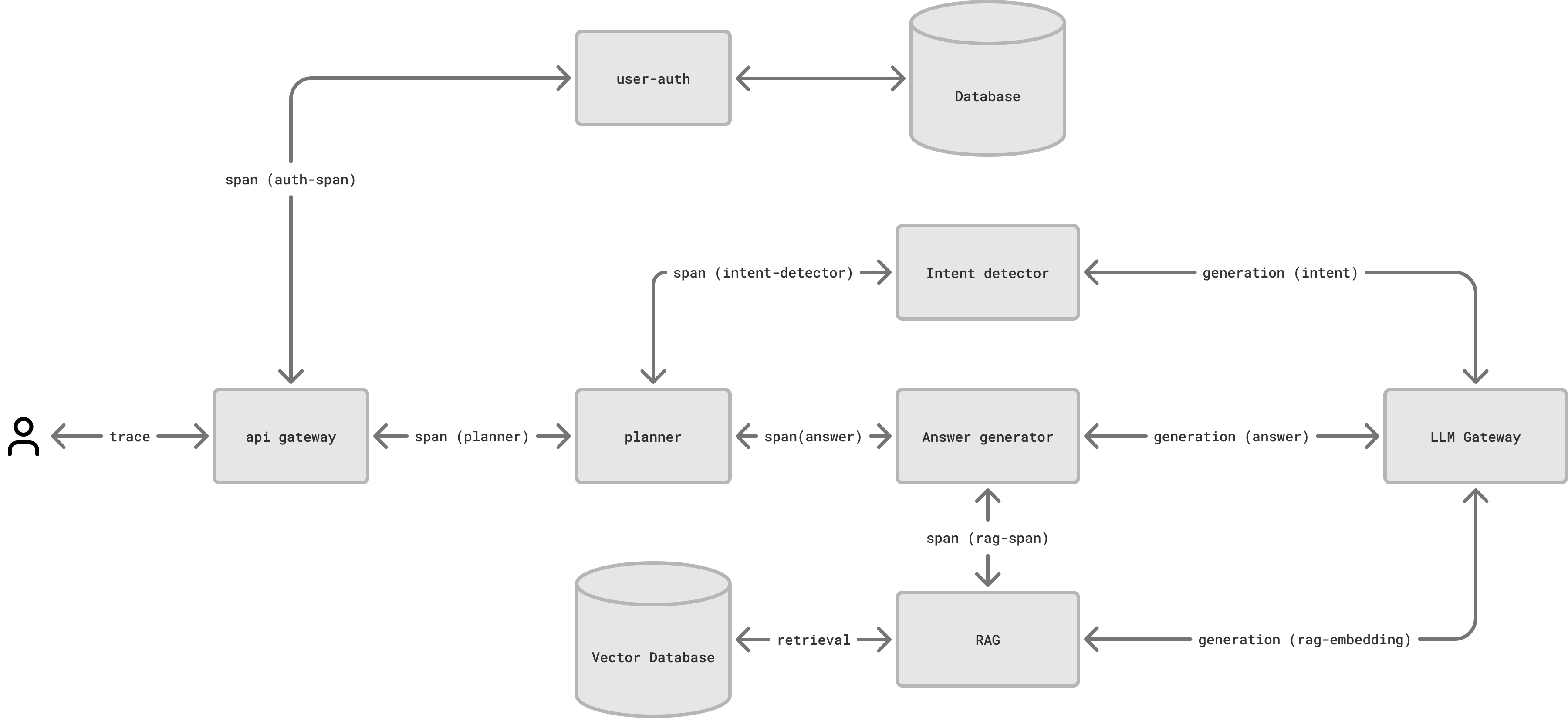
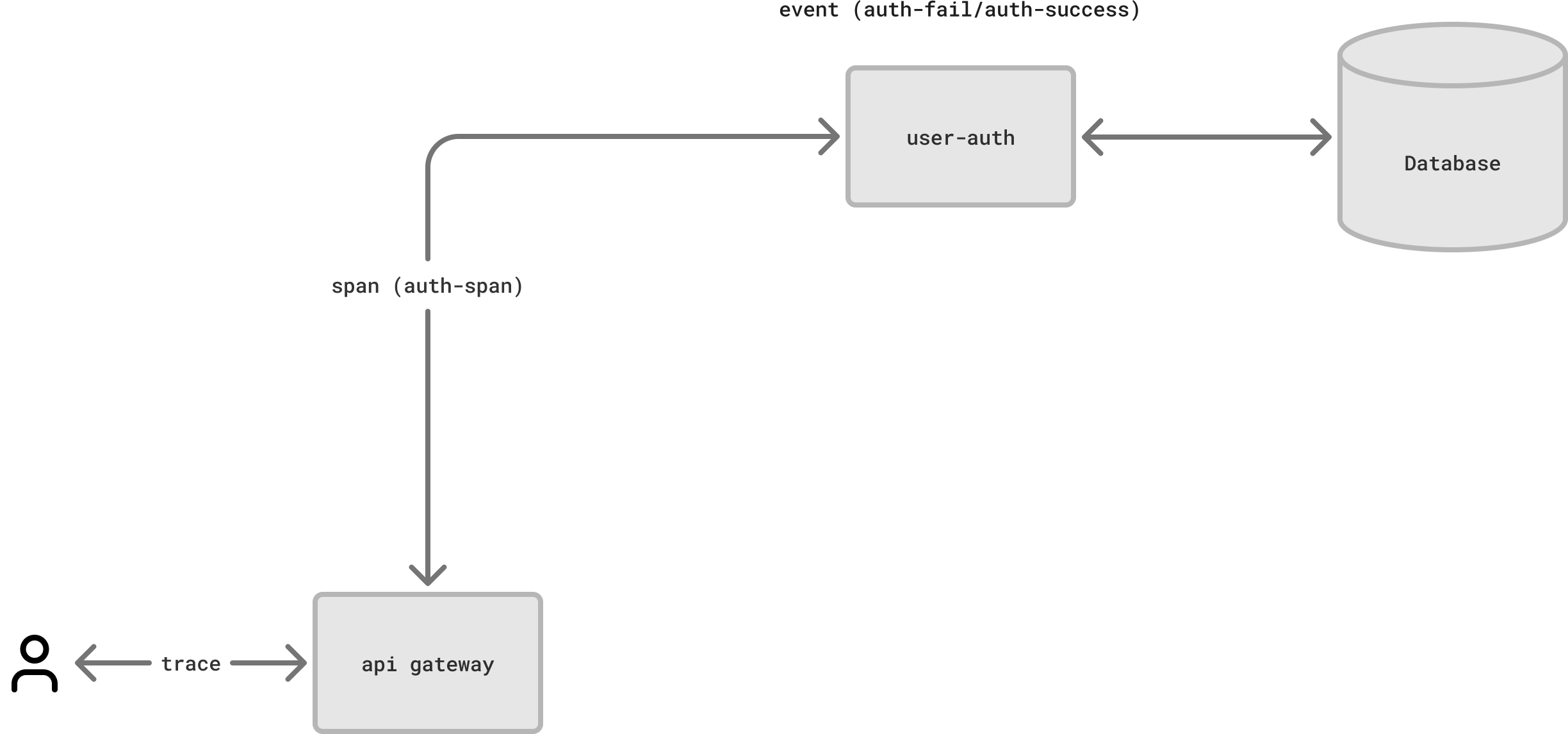
Split your logs across multiple repositories in your workspace based on your needs. For example, you might have one repository for production logs and another for development logs; or you could have a single repository for all logs, differentiated by tags indicating the environment.
We recommend implementing separate log repositories for separate applications, but also separate log repositories for separate services that managed by distinct teams. Trying to keep logs that are related to different applications or services in the same repository can lead to difficulties in analyzing and troubleshooting.