Run bulk comparisons across test cases
Experimenting across prompt versions at scale helps you compare results for performance and quality scores. By running experiments across datasets of test cases, you can make more informed decisions, prevent regressions and push to production with confidence and speed.
Why run comparison experiments
- Make decisions between Prompt versions and models by comparing output differences.
- Analyze scores across all test cases in your Dataset for the evaluation metrics that you choose.
- Side by side comparison views for easy decision making and detailed view for every entry.
Run a comparison report
Open the Prompt playground for one of the Prompts you want to compare.
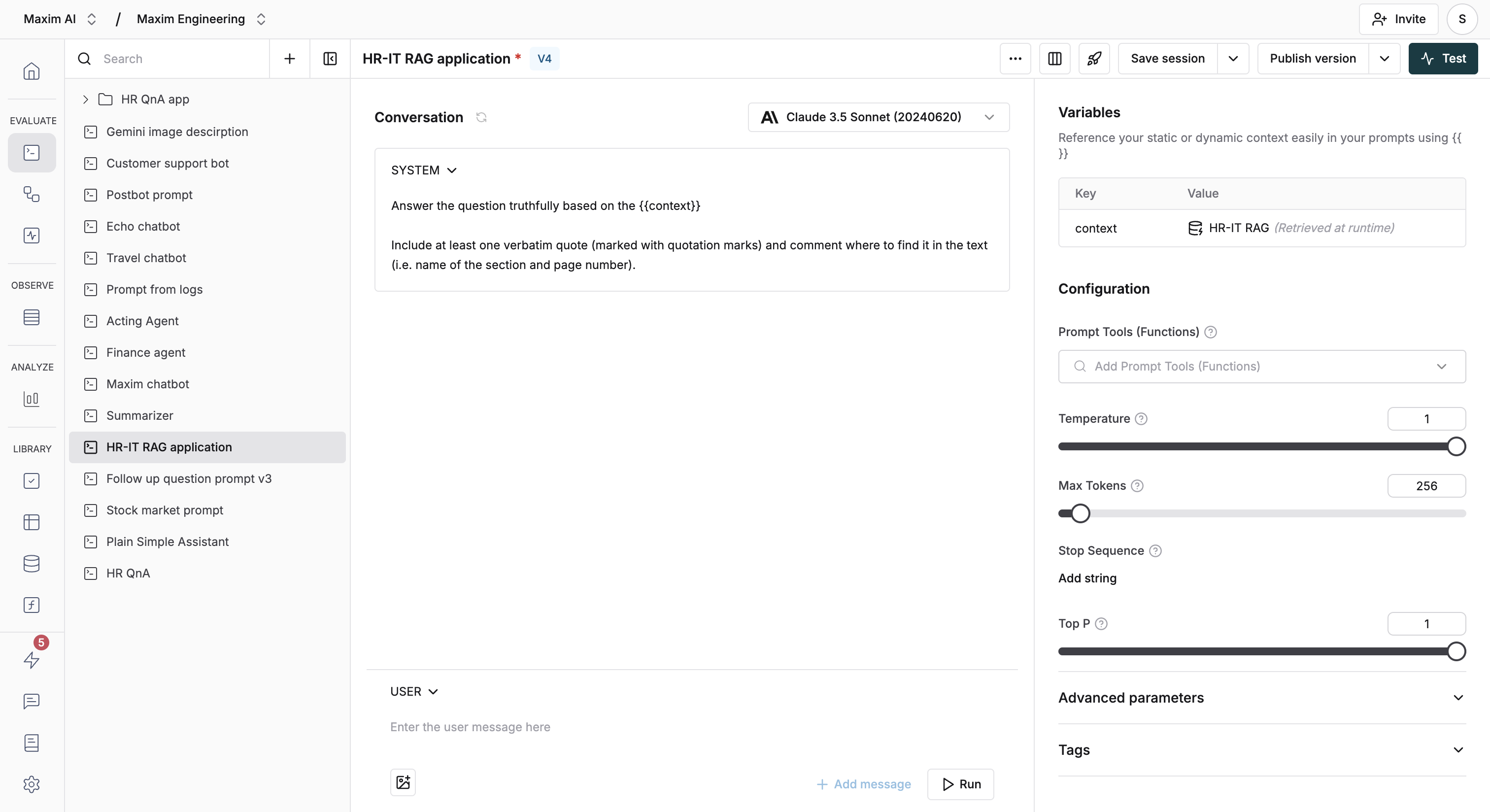
Click the test button to start configuring your experiment.
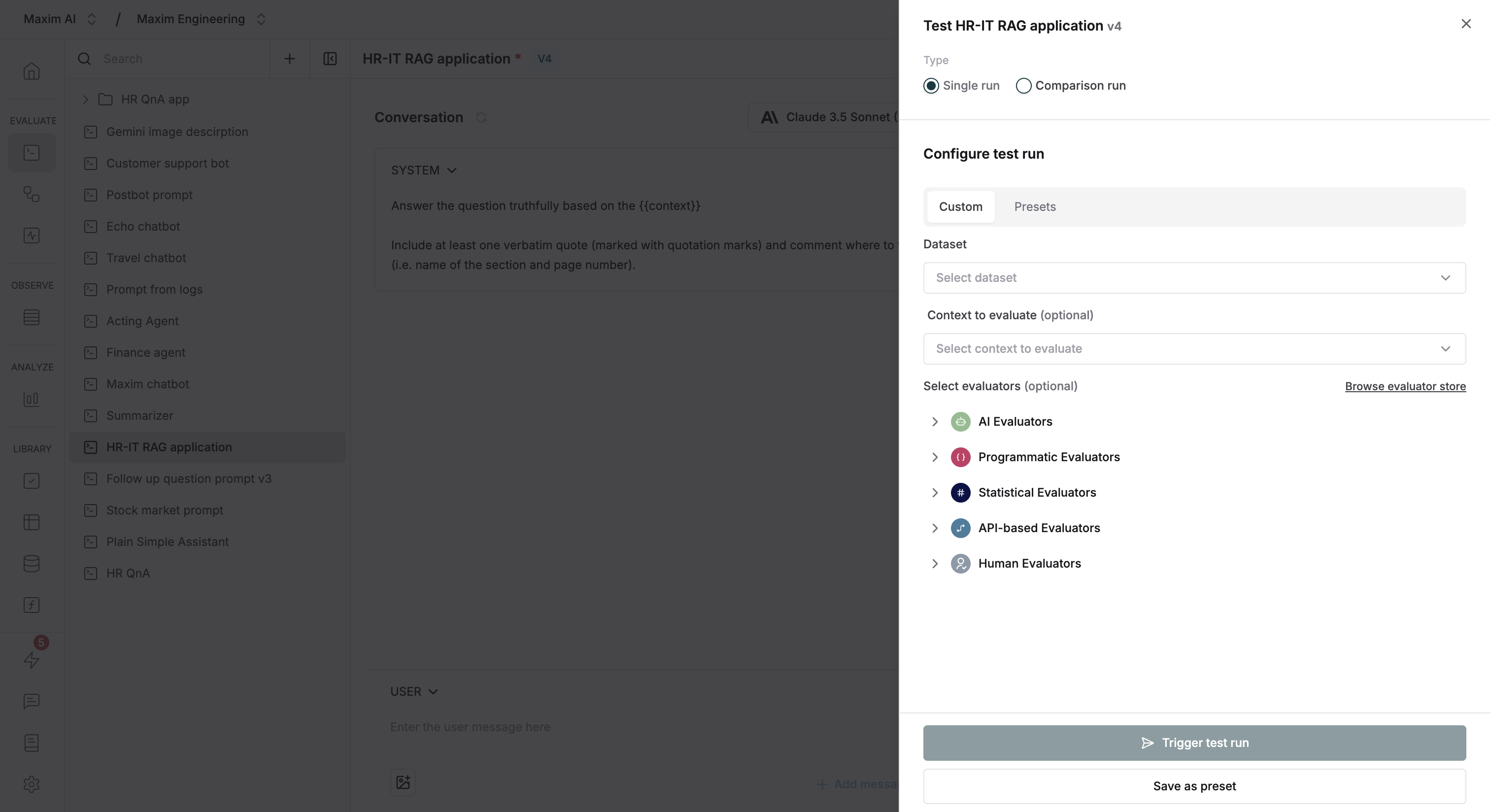
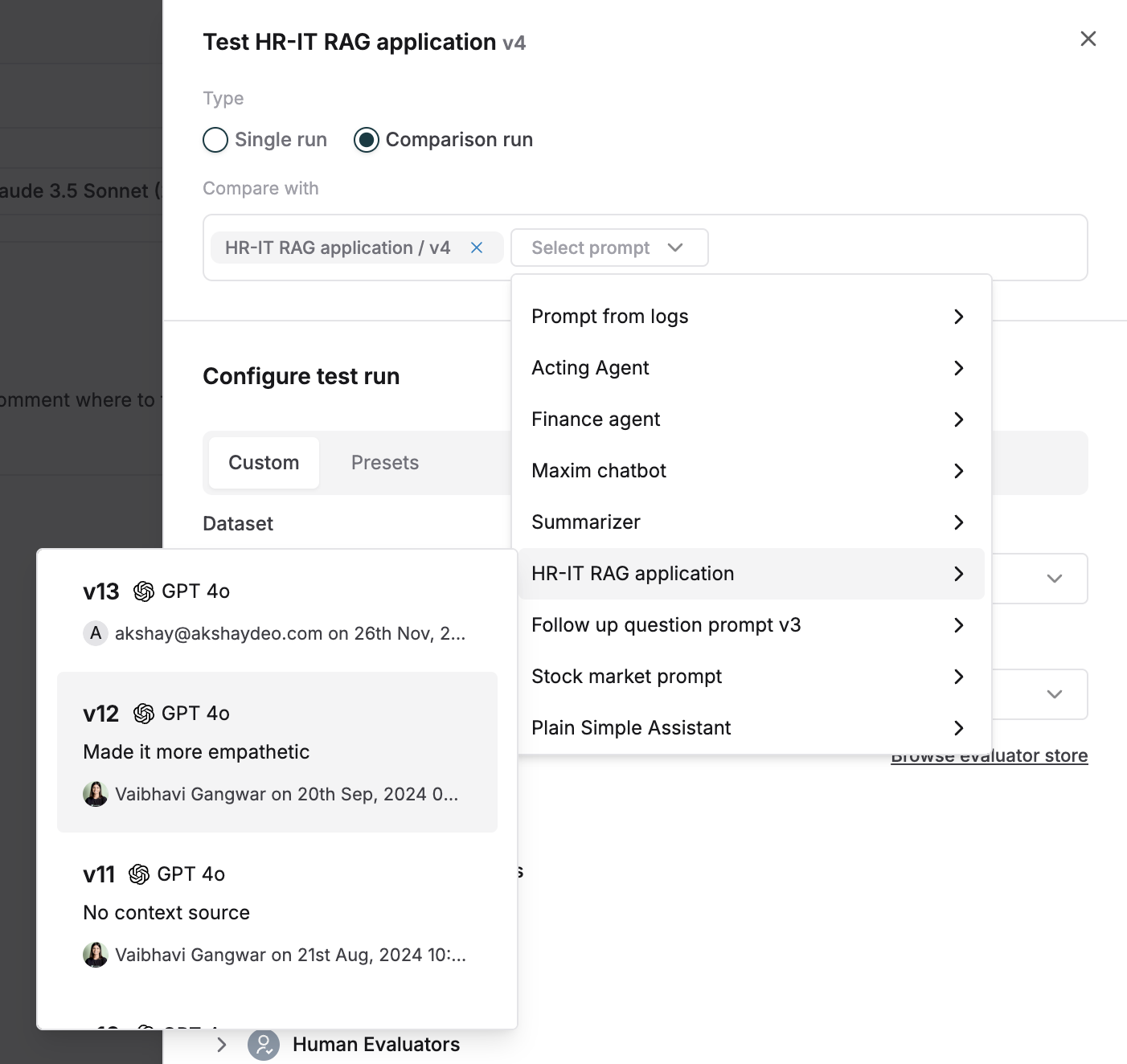
Select the Prompt versions you want to compare it to. These could be totally different Prompts or another version of the same Prompt.
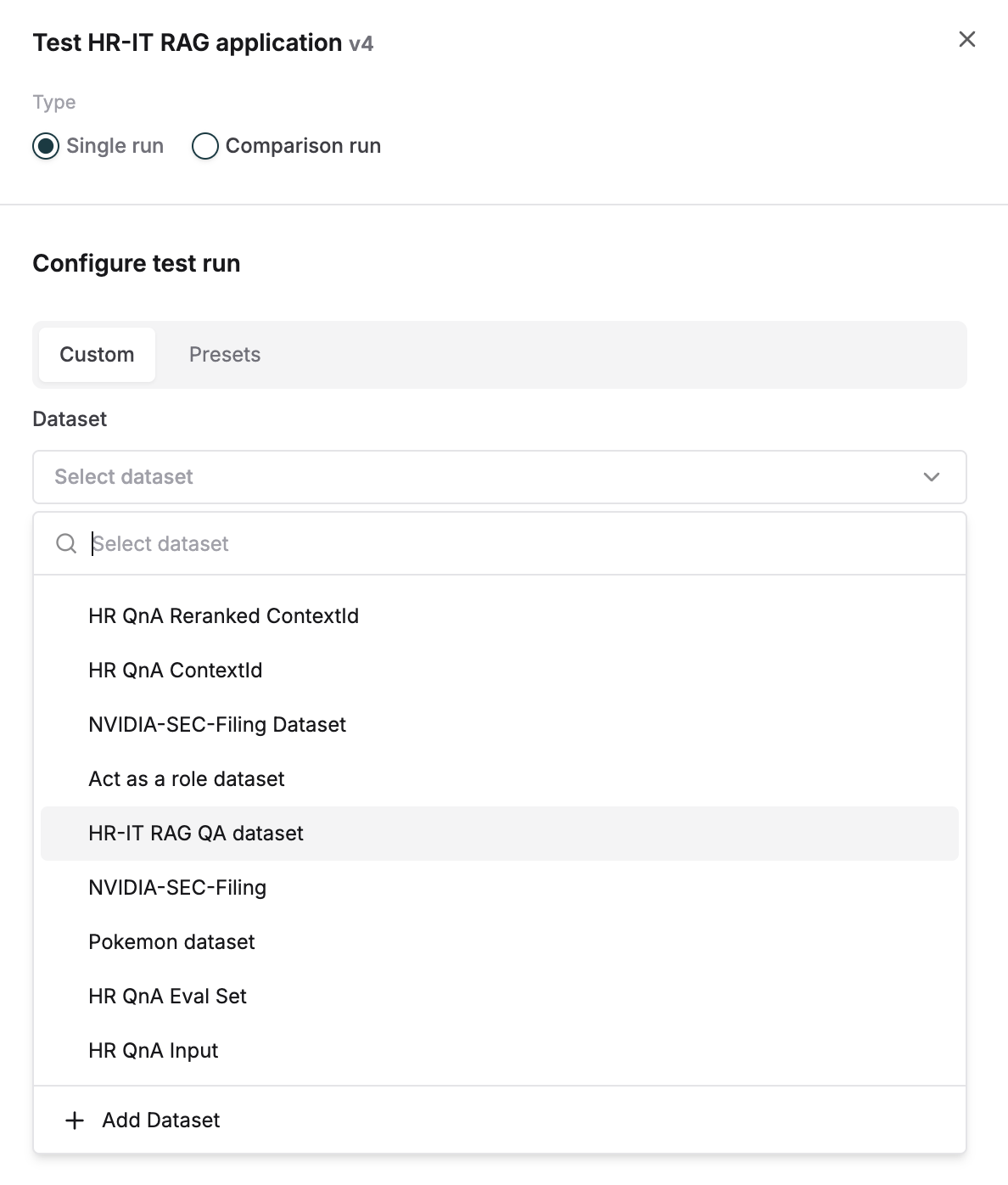
Select your Dataset to test it against.
Optionally, select the context you want to evaluate if there is a difference in retrieval pipeline that needs comparison.
Select existing Evaluators or add new ones from the store, then run your test.

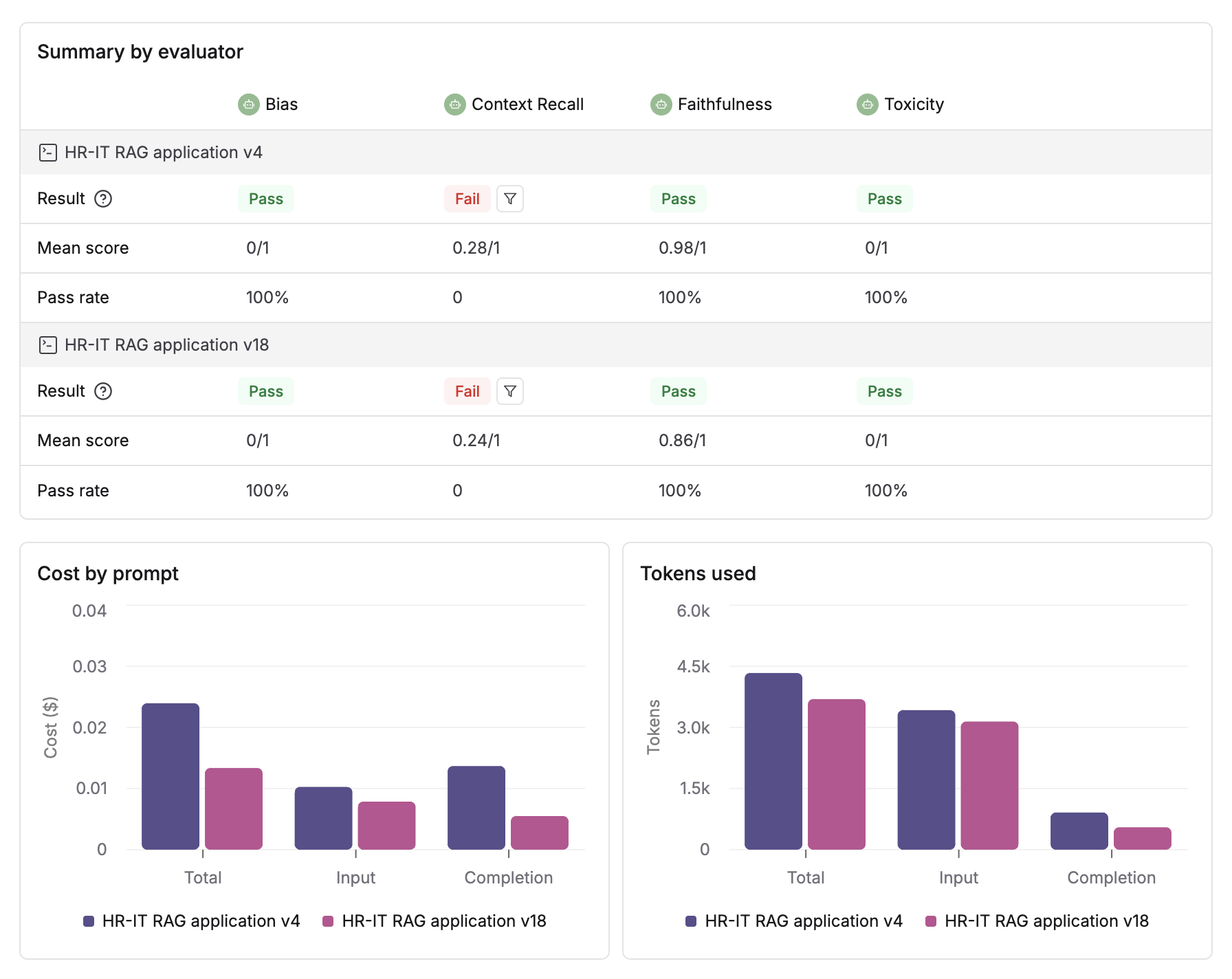
Once the run is completed, you will see summary details for each Evaluator. Below that, charts show the comparison data for latency, cost and tokens used.
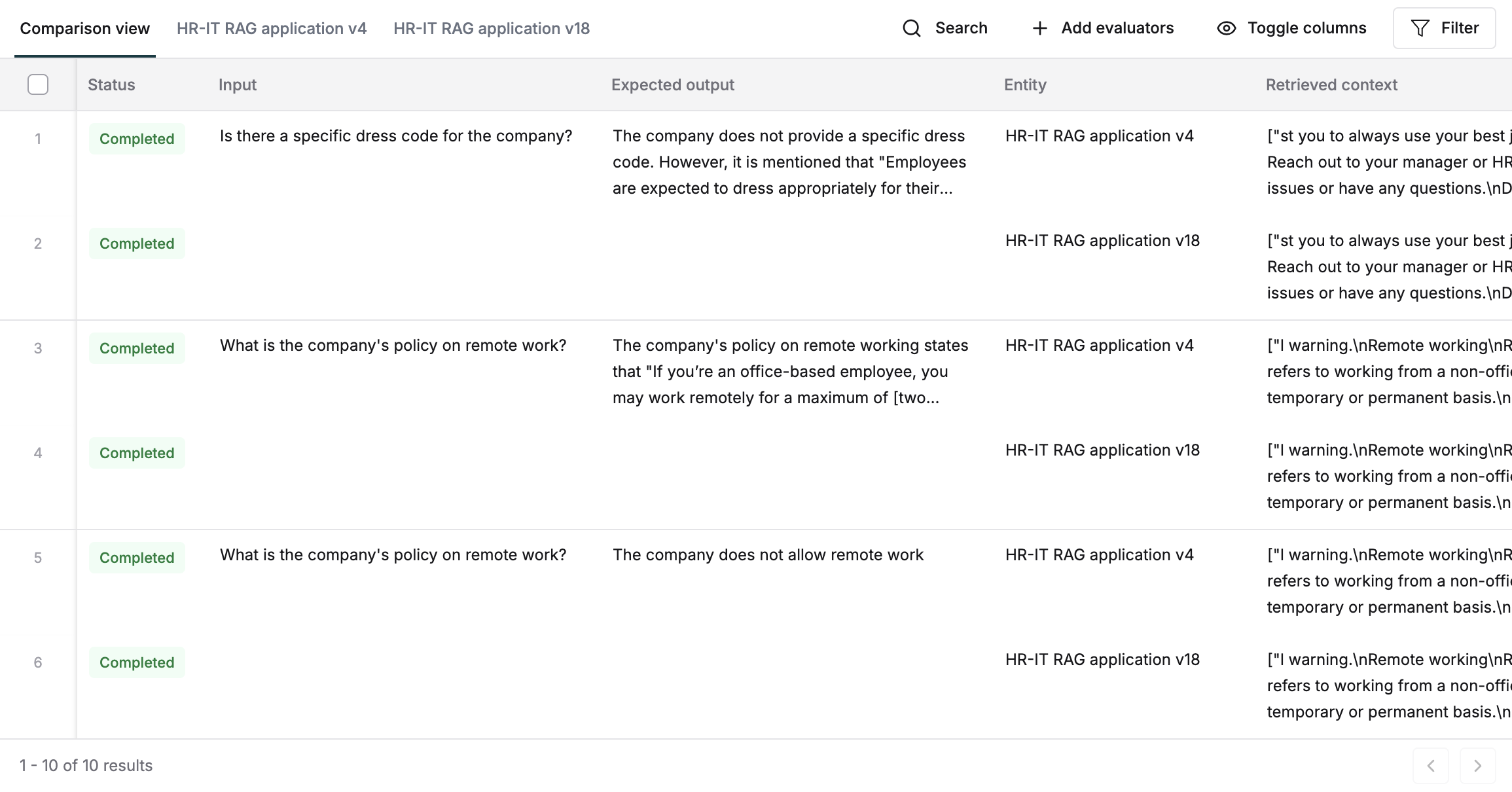
Each entry has 2 rows one below the other showing the outputs, latency and scores for the entities or versions compared. Deep dive into any entry by clicking the row and looking into the particular messages, evaluation details and logs.
If you want to compare Prompt versions over time (e.g. Last month's scores and this month's scores post a Prompt iteration), you can instead generate a comparison report retrospectively under the analyze section.
Next steps
Compare Prompts in the playground
Iterating on Prompts as you evolve your AI application would need experiments across models, prompt structures, etc. In order to compare versions and make informed decisions about changes, the comparison playground allows a side by side view of results.
Deploy Prompts
Quick iterations on Prompts should not require code deployments every time. With more and more stakeholders working on prompt engineering, its critical to keep deployments of Prompts as easy as possible without much overhead. Prompt deployments on Maxim allow conditional deployment of prompt changes that can be used via the SDK.