We currently only have v1 of the CLI tool. So please replace <VERSION> with v1.
How to/Evaluate Prompts
Automate Prompt evaluation via CI/CD
Trigger test runs in CI/CD pipelines to evaluate prompts automatically.
Ensuring quality with every deployment
AI applications today are shipping lightning fast and there are a lot of iterations / changes being made to the system. Moving as fast means having to break a lot; but it doesn't necessarily have to. A good practice is to ensure that none of previous functionality breaks with the new changes.
This is where Maxim's CI/CD integration can help you out. By integrating a step to run a Test run into your deployment workflow, you can ensure that every new deployment is meeting a certain baseline quality.
Before we start
Triggering a test run from CI/CD requires you have the following setup and ready:
- An API key from Maxim
- A prompt version to test upon
- A dataset to test against
- Evaluators to evaluate the prompt version against the dataset
Now that we have all the prerequisites, test runs can be triggered via:
Test runs via CLI
Maxim offers a CLI tool that can be used to run test runs. It is an executable binary that can be run from the command line.
Installation
Use the following command template to install the CLI tool (if you are using Windows, please refer to the Windows example as well):
Supported OS + ARCH
The command template can have the following OS + Architectures values,
| OS | ARCH |
|---|---|
| Linux | amd64 |
| Linux | 386 |
| Darwin | arm64 |
| Darwin | 386 |
| Windows | amd64 |
| Windows | 386 |
Env Variables
We require you to set these environment variables before using the CLI, these values cannot be passed via arguments/flags.
| Name | Value |
|---|---|
| MAXIM_API_KEY | API key obtained via Maxim |
Triggering a test run
Use this template to trigger a test run:
Here are the arguments/flags that you can pass to the CLI to configure your test run
| Argument / Flag | Description |
|---|---|
| -p | Prompt version ID or IDs; in case you send multiple IDs (comma separated), it will create a comparison run. |
| -d | Dataset ID |
| -e | Comma separated evaluator names Ex. bias,clarity |
| --json | (optional) Output the result in JSON format |
Test runs via GitHub Action
GitHub actions provide a powerful way to run tests, build, and deploy your application. Our GitHub Action can seamlessly integrate with your existing deployment workflows, allowing you to ensure that your LLM is functioning as you expect.
Quick Start
In order to add the GitHub Action to your workflow, you can start by adding a step that uses maximhq/actions/test-runs@v1 as follows:
Please ensure that you have the following setup:
- in GitHub action secrets
- MAXIM_API_KEY
- in GitHub action variables
- WORKSPACE_ID
- DATASET_ID
- PROMPT_VERSION_ID
This will trigger a test run on the platform and wait for it to complete before proceeding. The progress of the test run will be displayed in the Running Test Run section of the GitHub Action's logs as displayed below:
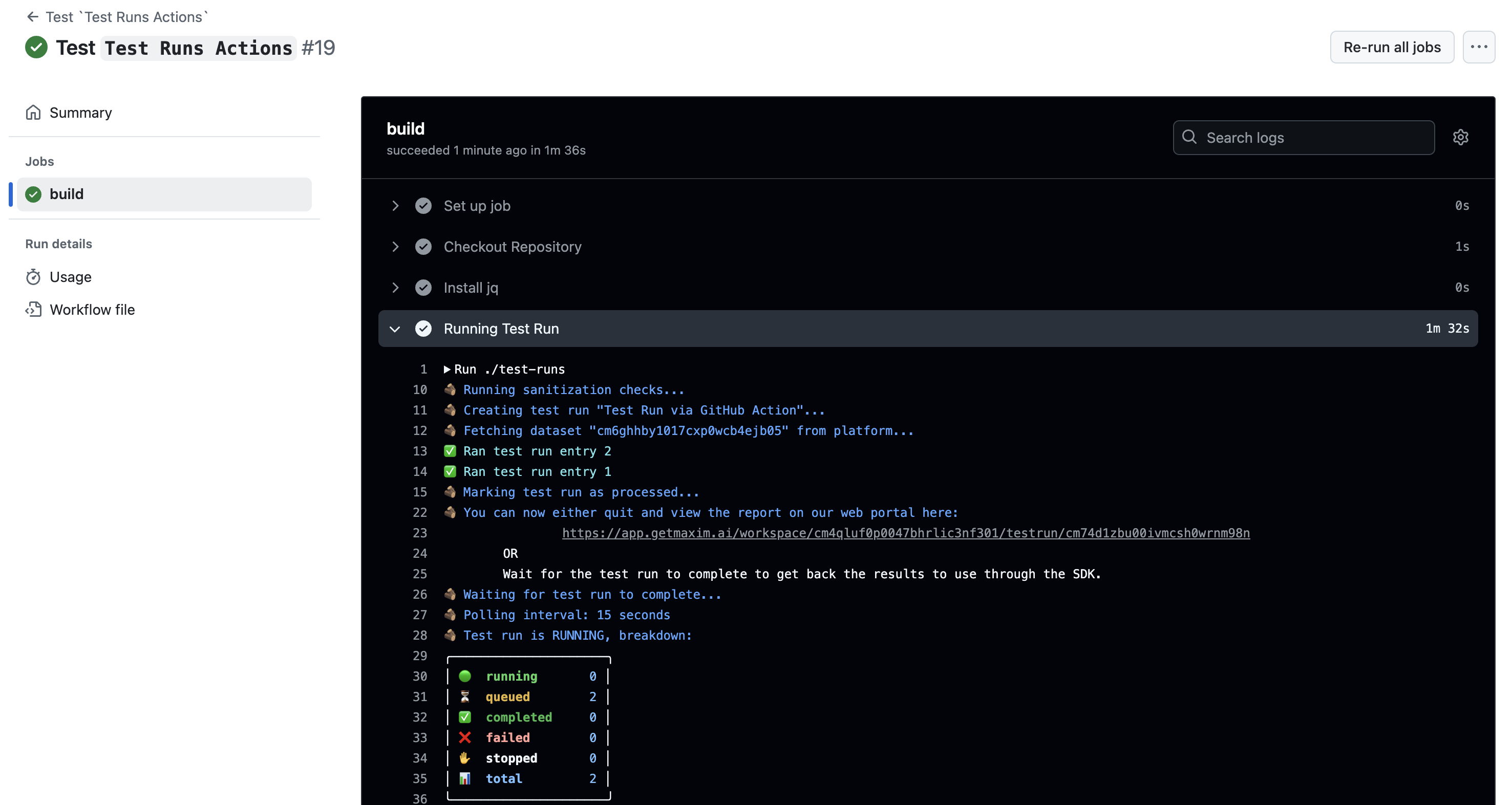
Inputs
The following are the inputs that can be used to configure the GitHub Action:
| Name | Description | Required |
|---|---|---|
api_key | Maxim API key | Yes |
workspace_id | Workspace ID to run the test run in | Yes |
test_run_name | Name of the test run | Yes |
dataset_id | Dataset ID for the test run | Yes |
prompt_version_id | Prompt version ID to run for the test run (do not use with workflow_id) | Yes (No if workflow_id is provided) |
workflow_id | Workflow ID to run for the test run (discussed in Evaluate Workflows via API -> Automate workflow evaluation via CI/CD, do not use with prompt_version_id) | Yes (No if prompt_version_id is provided) |
context_to_evaluate | Variable name to evaluate; could be any variable used in the workflow / prompt or a column name | No |
evaluators | Comma separated list of evaluator names | No |
human_evaluation_emails | Comma separated list of emails to send human evaluations to | No (required in case there is a human evaluator in evaluators) |
human_evaluation_instructions | Overall instructions for human evaluators | No |
concurrency | Maximum number of concurrent test run entries running | No (defaults to 10) |
timeout_in_minutes | Fail if test run overall takes longer than this many minutes | No (defaults to 15 minutes) |
Outputs
The outputs that are provided by the GitHub Action in case it doesn't fail are:
| Name | Description |
|---|---|
test_run_result | Result of the test run |
test_run_report_url | URL of the test run report |
test_run_failed_indices | Indices of failed test run entries |
Evaluating Workflows
Please refer to Evaluate Workflows via API -> Automate workflow evaluation via CI/CD
Query Prompts via SDK
Learn how to efficiently query and retrieve prompts using Maxim AI's SDK, including deployment-specific and tag-based queries for streamlined prompt management.
Set up a human annotation pipeline
Human annotation is critical to improve your AI quality. Getting human raters to provide feedback on various dimensions can help measure the present status and be used to improve the system over time. Maxim's human-in-the-loop pipeline allows team members as well as external raters like subject matter experts to annotate AI outputs.